Le chemin vers le doublage en temps réel
- Publié
- Dernière mise à jour
ÉcouterÉcouter cet article
Pour certains, le doublage en temps réel évoque l'image du Babelfish du Guide du voyageur galactique.
Tant que nous ne pouvons pas lire les ondes cérébrales, nous devons écouter les mots du locuteur et les traduire dans la langue cible. Essayer de traduire chaque mot au fur et à mesure qu’il est prononcé pose de vrais défis.
Imaginez que vous souhaitez traduire de l’anglais vers l’espagnol. Le locuteur commence par « The ». En espagnol, « The » se traduit par « El » pour les mots masculins et « La » pour les mots féminins. On ne peut donc pas traduire « The » avec certitude avant d’avoir plus d’informations.
Imaginez un scénario où vous souhaitez traduire de l'anglais vers l'espagnol. Le locuteur commence par « The ». En espagnol, « The » se traduit par « El » pour les mots masculins et « La » pour les mots féminins. Nous ne pouvons donc pas traduire « The » avec certitude tant que nous n'avons pas entendu plus.

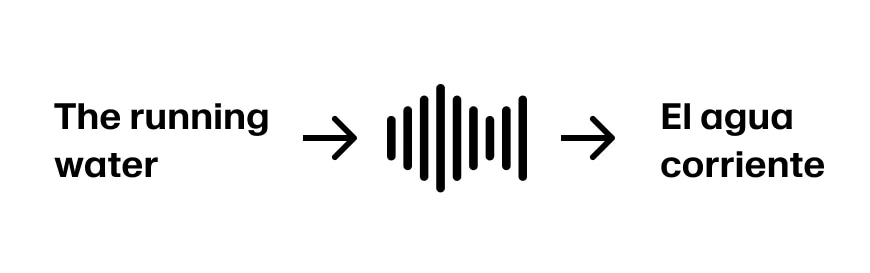
Imaginez que le locuteur continue par « The running water ». Nous avons maintenant suffisamment d'informations pour traduire les trois premiers mots par « El agua corriente ». En supposant que la phrase continue par « The running water is too cold for swimming », nous sommes en bonne voie.
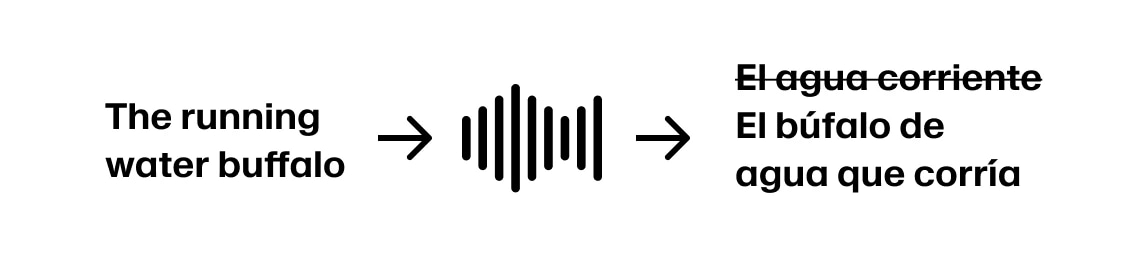
Mais si le locuteur continue par « The running water buffalo… », nous devons revenir en arrière.
Ces phrases dites «
Selon les cas d’usage, vous pouvez accepter de devoir revenir en arrière si vous commencez le doublage trop vite. Pour d’autres, vous pouvez choisir d’ajouter de la latence pour plus de précision. Puisqu’un certain délai est inévitable dans tous les cas de doublage, nous définissons le « doublage en temps réel » comme un service qui permet de diffuser de l’audio en continu et de recevoir le contenu traduit en retour.
Pour certains cas d'utilisation, vous pouvez accepter de devoir revenir en arrière après avoir commencé à doubler trop rapidement. Pour d'autres, vous pouvez choisir d'ajouter une latence pour plus de précision. Étant donné qu'une certaine latence est inhérente à tous les cas d'utilisation de doublage, nous définissons le doublage « en temps réel » comme un service à travers lequel vous pouvez diffuser en continu de l'audio et obtenir du contenu traduit en retour.

Les meilleures applications commerciales du doublage en temps réel sont celles où
Les meilleures applications commerciales du doublage en temps réel sont celles où
- Il y a un public mondial
- C'est du contenu en direct
- Il est acceptable d'avoir un certain retard dans la diffusion
Sport
Forbes a rapporté en 2019 que la NBA gagne 500 millions de dollars en droits télévisés internationaux. La NFL organise maintenant des matchs au Brésil, en Angleterre, en Allemagne et au Mexique, car elle considère l'expansion internationale comme un moteur de revenus essentiel pour l'avenir.
En général, plusieurs opérateurs caméra et son sont sur place et envoient leurs flux à une régie de production. Celle-ci alterne entre les caméras, mixe l’audio, ajoute des graphiques et les commentaires. Il arrive aussi qu’un délai supplémentaire soit ajouté pour pouvoir couper les gros mots ou contenus inattendus.
Le flux principal de production est envoyé au réseau de diffusion, qui ajoute son habillage et ses publicités, puis distribue le contenu à ses réseaux locaux. Enfin, les fournisseurs finaux partagent le contenu avec les spectateurs via câble, satellite ou services de streaming.
Le flux de production principal est envoyé au réseau de diffusion qui ajoute sa propre marque et ses publicités et distribue le contenu à ses réseaux locaux. Enfin, les fournisseurs de dernière étape partagent le contenu avec les consommateurs via des câbles, des flux satellites et des services de streaming.

Les entreprises du sport veulent avant tout offrir un produit de qualité, et pour elles, la clé est de bien transmettre l’émotion et le rythme des commentateurs. « Il tire, il marque ! » doit être dit avec enthousiasme.
Nos modèles de clonage de voix, qui alimentent notre service de doublage, sont capables de reproduire l’émotion et l’intonation du locuteur d’origine. Contrairement à la traduction, plus de contexte ne donne pas toujours un meilleur résultat. Mais nous n’avons pas encore atteint le niveau d’émotion d’un commentateur de football espagnol !
Chaque clone de voix est une moyenne de ses entrées. Si vous mélangez une phrase dite de façon neutre comme « Ils vont devoir être plus agressifs, il ne reste que deux minutes. » avec « Il tire, il marque ! », le clone obtenu aura une intonation moyenne entre les deux.
Chaque clone de voix est une moyenne de ses entrées. Si vous combinez une ligne livrée de manière plate comme « Ils vont devoir être plus agressifs avec seulement deux minutes restantes. » avec « Il tire, il marque ! », le clone résultant sera la moyenne des deux prestations.

Journal télévisé
Comme pour le sport « en direct », le journal télévisé passe par une chaîne de production qui ajoute du délai. D’après nos échanges avec les médias, transmettre l’émotion (même si c’est important) est moins critique et souvent plus simple, car la plupart des présentateurs ont un ton très régulier. En revanche, il est essentiel que la traduction soit précise et nuancée.
En plus du risque d’erreur dans la traduction automatique, certains concepts n’ont pas d’équivalent direct. Par exemple :
« La communauté s’est réunie pour une journée de commémoration, où les survivants ont partagé leurs histoires et les aînés ont prononcé des prières traditionnelles pour la guérison. »
Espagnol : « La comunidad se reunió para un día conmemorativo, donde los sobrevivientes compartieron sus historias y los ancianos realizaron oraciones tradicionales para la sanación. »
Même si c’est techniquement correct, « survivors » et « sobrevivientes » n’ont pas le même poids dans le contexte d’un traumatisme historique : en anglais, cela implique souvent la résilience et la dignité, alors que « sobrevivientes » peut insister sur la victimisation. De même, « performed prayers » et « realizaron oraciones » diffèrent dans la nuance : « performed » souligne l’importance cérémonielle, tandis que « realizaron » peut sembler plus procédural.
Bonus – Vers le doublage conversationnel
Pour permettre une conversation naturelle, en face à face, entre des personnes qui ne parlent pas la même langue, il faut une traduction quasi instantanée.
En utilisant les probabilités de prédiction du prochain token des LLM, on obtient un modèle en temps réel de la probabilité de la suite d’une phrase.
En utilisant les probabilités de prédiction du prochain token des LLM, vous avez un modèle en temps réel de la probabilité de la direction d'une phrase.

Source de l'image - Hugging Face « Comment générer du texte »
Vous trouvez ça intéressant et souhaitez travailler avec nous sur l’avenir de l’audio IA ? Découvrez
Vous trouvez cela intéressant et souhaitez travailler avec nous sur l'avenir de l'audio IA ? Découvrez les postes ouverts ici.




