Voice agent evaluation framework: 6 pillars explained
- Written by
- Jack Limebear
- Published
- Last updated
ListenListen to this article
Voice agents need to orchestrate a symphony of near-concurrent tools. It’s a delicate dance of recording a customer’s comments with real-time speech to text (STT), assimilating context and producing a response with a large language model (LLM), and then generating an audio file with text to speech (TTS) software.
With so many moving parts, how do you accurately evaluate voice agent performance?
In this article, we’ll propose a six pillar voice agent evaluation framework that describes exactly what to measure when assessing agent success. We’ll also touch on why distinct industries should weigh these pillars differently and common mistakes to look out for when evaluating.
Summary
- The six main voice agent evaluation pillars to use are TTS voice quality, conversation quality, tool usage and task completion, intelligence, compliance and safety, and reliability.
- The most important production targets to work toward are an MOS of 4.3, a TSR above 85%, and a time-to-first audio under 500ms.
- Different industries will weigh each of the pillars distinctly, with certain deployments favoring one over the others.
- Common testing mistakes include only evaluating clean audio and ignoring P99 latency spikes.
- ElevenLabs leads on the metrics that matter most: Scribe v2 achieves the lowest WER in the field at 2.2% (Artificial Analysis, June 2026,) Flash v2.5 and Turbo v2.5 are top models for speed (Artificial Analysis, June 2026,) and ElevenAgents deliver ~75ms model inference latency.
What is a voice agent evaluation framework?
An AI voice agent evaluation framework is a structured system that allows you to test performance across multiple dimensions. A comprehensive framework will include metrics to assess everything from audio fidelity to conversation flow and even regulatory compliance.
Unlike a text chatbot, a voice agent routes every interaction through at least three stacked technologies: automatic speech recognition (ASR), which converts a user’s words to text; an LLM that assembles a response; and a TTS system that converts that response back to audio. If any one of these systems fails, it degrades the entire experience.
This complexity is precisely why businesses need to evaluate voice agents before selecting a provider and deploying. Any additional latency or imprecise responses could have real-world repercussions, like churned customers or, at worst, regulatory fines and reputational damages.
A framework for evaluating voice agents uses benchmarking and measurable data to define whether or not an agent is apt for certain use cases. From a business perspective, being able to evaluate different voice models allows you to select the best one for your customers.
The six voice agent evaluation pillars you should evaluate
While creating and deploying an AI agent has never been simpler, the active processes going on under the hood are fairly complex. With several components acting in tandem to listen to a user, understand what they want, feed that information to an LLM, and then produce an audio response, lots of near-simultaneous actions occur.
When aiming to partner with the best possible voice agent, businesses need a rigorous framework to benchmark against.
If you’re more interested in seeing the results of testing, then Artificial Analysis offers several agent comparisons based on different components. Below, you can see the results of their model-to-model speed factor face-off, with ElevenLabs Turbo v2.5 and Flash v2.5 leading by a significant margin in characters processed per second.
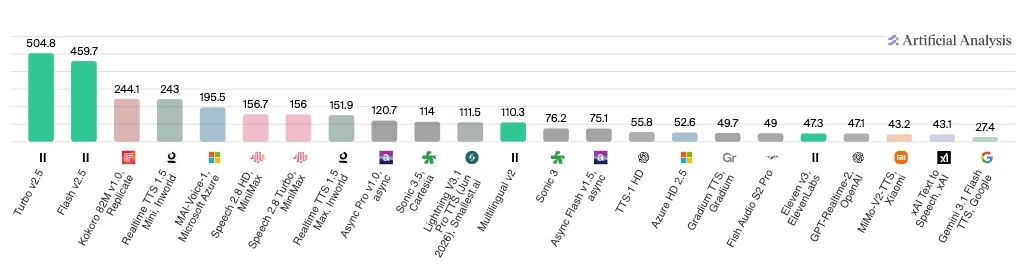
For developers or businesses that want to conduct their own experiments, here are the six pillars of an AI agent assessment framework you should use:
- TTS voice quality: How natural, clear, and expressive the synthesized speech sounds to end users. Top models in the field, like Eleven v3, offer human-like, emotive delivery in over 70 languages.
- Conversation quality: Does a model understand human speech, compute meaning, and respond in context promptly across multiple turns?
- Tool usage: The extent to which an AI agent completes tasks using available resources without needing human intervention.
- Intelligence: How well a model reasons, handles novel inputs, and avoids producing inaccurate or hallucinated responses.
- Compliance and safety: Alongside all capabilities, AI voice agents must adhere to all regulatory and compliance requirements, including active guardrails.
- Reliability: Components like total uptime and consistent performance under load to determine if a conversational AI agent can scale with demand.
While each of these pillars is independent, they interlink to provide a high-quality final experience for the user. For example, if a model improved its voice quality but still had high latency, the customer would experience awkward wait times before the model delivered speech.
Let’s explore each of these voice AI evaluation pillars in more depth.
TTS voice quality
We’re starting with voice quality, as that is likely the first thing a human will notice when interacting with an AI conversational agent. If it sounds robotic or uncanny, the subjective experience with an agent will be considerably worse.
One of the original assessment metrics, as defined by the International Telecommunication Union Telecommunication Standard Sector (ITU-T), is Mean Opinion Score (MOS). MOS works on a scale of 1-5, with 1 being unusable and 5 being excellent. As a subjective measurement, this uses human listeners and then gathers feedback after a call.
Anything below MOS 3.5 on this scale is fairly unimpressive, especially by modern standards, and will likely impact customer satisfaction.
While MOS is the human-first metric, several technical requirements feed into that figure:
- Pitch consistency and jitter: Pitch and jitter are two linguistic elements that humans naturally register while they listen. “Pitch” refers to changing intonation throughout speech, like when you naturally raise your voice when asking a question. Jitter is where a voice model’s understanding of pitch varies, making it unable to maintain coherent prosody across a sentence. The industry baseline for jitter is 30ms.
- Emotional expressiveness: A voice that is clear and precise still sounds wrong if the tone doesn’t match the intended emotional register of a sentence. Without accurate tonal cues, human listeners will have less rapport with AI conversational agents and rank them lower. ElevenAgents offers near-human-like expressiveness to match every response with a clear emotional intention.
- Background noise: Background noise in voice agents has two distinct dimensions worth evaluating. On the output side, ambient background noise is subtly added to responses to make agents sound more natural. On the input side, background noise filtering on the STT layer is an optional toggle that improves accuracy. When evaluating an agent, test both: listen for whether ambient noise sounds natural and assess STT accuracy with the noise filter on and off.
When calculating MOS, you should aim for 4.3-4.5, which demonstrates high scores across all of these perceptive categories. For MOS prediction at scale without requiring human panels, you can use tools like UTMOS and NISQA.
Conversation quality
Conversation quality is a composite pillar that exists between voice quality and task completion. It aims to measure how effectively a voice agent understand a user’s needs, interrupt them in context, and carry that through a multi-turn dialogue to completion.
The primary metric here is intent classification accuracy, with a typical range scoring between 85% and 92% and top performers reaching upwards of 96%. While 85% may seem high, that still represents 15% of all incoming traffic being miscategorized and routed to the wrong resources.
The technical elements that contribute to high intent classification accuracy are:
- Turn-taking: Turn-taking determines how well a voice agent manages the natural flow of conversation. It aims to assess when it knows to listen, respond, or wait for more input. It also extends to handling barge-ins, where a model clears an in-process response and generates a fresh one based on the new input. ElevenLabs uses a multi-context websocket to seamlessly handle these graceful interruptions.
- Latency: Latency describes the end-to-end delay between a user finishing their sentence and the agent beginning its audio response. Production-grade voice agents should target a time-to-first audio of under 500ms, with sub-300ms being superior. ElevenLabs Flash models offer industry-leading model inference time of ~75ms, setting you up for success in this category.
- Fallback rate: Fallback rate is a measure of how often an AI agent fails to understand a user and asks for either a clarification or a repetition. It’s largely a downstream consequence of STT accuracy, as if the speech recognition layer mishears or misrepresents what a customer said, the LLM receives corrupted input. Fallback rate is a flat calculation that uses the formula: Fallback rate (%) = (Number of fallbacks / Total number of interactions) * 100.
ElevenLabs Scribe V2 has the lowest WER at 2.2% on the Artificial Analysis speech to text model evaluation
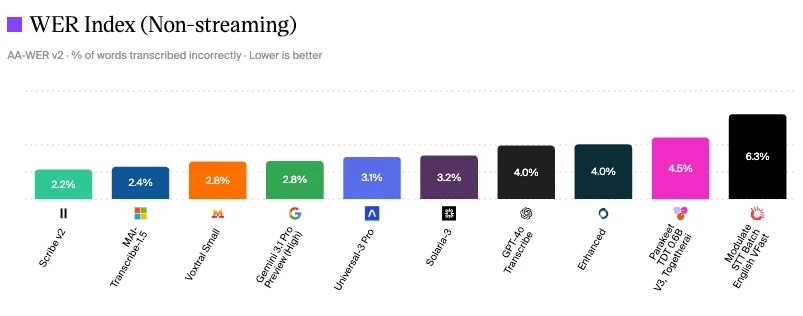
Artificial Analysis speech to text models evaluation
One way to measure conversation quality is by looking at industry benchmarking standards for different components. As you can see, ElevenLabs’ Scribe v2 has the lowest Word Error Rate at 2.2% as of June 2026, which means fewer mishears, fewer fallbacks, and more accurate intent classification.
Businesses may find that conversational quality also depends on the workflow a voice agent operates in. For example, in customer service, another consideration would be escalation handoff quality or FAQ resolution.
Tool usage and task completion
While quality measures how a conversation felt, task completion measures whether it led to a successful outcome. Enterprises should pay close attention to this part of the voice agent evaluation framework, as it is directly tied to business outcomes.
One measure of tool usage is slot-fill accuracy, which determines how well AI agents can complete fairly routine tasks, like filling in a form with customer information. High slot-fill accuracy demonstrates the agent can move seamlessly from conversation to action without losing information along the way.
Task Success Rate (TSR) is a percentage-based measurement of which end-to-end tasks were successfully completed by an agent. Completion here is based on an agent’s ability to both understand a request and then use the right connected tools (APIs, databases, Retrieval-Augmented Generation (RAG), and internal knowledge bases) for assistance.
The formula for TSR is:
TSR = (Tasks fully completed / Total tasks attempted) x 100
Production-ready voice agents should be targeting a TSR of above 85%, with monitoring for tool call accuracy and tool call reliability. To avoid slippage in your TSR, make sure to regression test for any prompt or connected model alteration. Even a small deviation could have significant consequences for your TSR.
Intelligence
Intelligence captures the reasoning and higher-order capabilities of a voice agent. It’s this pillar that clearly denotes the difference between a voice-led IVR (Interactive Voice Response) and a voice AI agent.
Key dimensions to evaluate here include:
- Hallucination risk: Hallucinations, where an agent produces information that is inaccurate or inconsistent with company documents, are especially damaging in voice AI as they can be delivered with confidence. Recent studies suggest that common hallucination significantly damages customer satisfaction with voice agents.
- Out-of-scope handling: Intelligent agents understand when a question falls outside of their contextual domain and are able to respond appropriately. Rather than hallucinating an answer, they decline or redirect the conversation back into contextually mapped territory.
- Context retention: Across several turns, can an agent track entities and commitments made earlier? Without this ability, customers may find themselves having to repeat themselves or experiencing contradictory responses.
- Reasoning and multi-step logic: Can the agent correctly handle conditional logic or chain inferences across multiple turns? Especially in more technical use cases, like financial services, the ability to reason within a predefined context is essential for success.
Several third-party benchmarks exist for these dimensions and components. For example, Stanford’s Holistic Evaluation of Language Models (HELM) benchmark LLM performance in different categories. For hallucinations, TruthfulQA offers a robust analysis of how frequently false answers creep into responses.
One advantage of ElevenAgents is that, unlike some voice platforms that lock you into a single underlying model, you can swap out the LLM layer entirely. In practice, that means you can plug in whichever model leads on the reasoning benchmarks for your specific use case.
Compliance and safety
Businesses need to implement active guardrails to prevent harmful or policy-violating outputs. Unlike system-level prompt instructions, which could be talked around or overridden, independent guardrail checks run as a separate layer outside the model itself. These evaluate outputs before they reach the user and halt the conversation if it strays into dangerous territory.
Auditability is a related requirement, with production agents needing to maintain detailed logs of decisions and outputs in a format that supports post-hoc review. Particularly in heavily regulated industries, demonstrating compliance after the fact is just as important as achieving it in the first place.
The exact regulations your business must comply with will vary by industry. Some of the most commonly applicable frameworks are:
- HIPAA: For protected health data in US healthcare contexts.
- PCI-DSS: For any agent handling payment card data.
- GDPR: Data privacy obligations for the EU and businesses with customers in the EU.
For businesses evaluating their compliance posture, ElevenLabs holds AICPA SOC Type II and GDPR compliance, alongside achieving AIUC-1 certification. The AIUC-1 is a security standard designed specifically for AI agents.
Reliability
Reliability is the final pillar in our voice agent evaluation framework, covering whether an agent can consistently deliver in real-time.
When assessing a voice agent, look for the following characteristics:
- Uptime: Any customer-facing deployment expects 99.9% uptime to avoid outages. Especially for always-on use cases, like inbound support, reliable uptime is a major factor.
- Graceful degradation: Due to the underlying complexity of voice agents, if one component begins to fail, the agent should handle that degradation gracefully. What that means in practice is routing to a human, rather than continuing to function with increased strain or while returning errors.
- Performance under load: Load testing should aim to simulate at least 2x your expected peak concurrency before you go live. Testing under heavy strain can pinpoint latency increases or degraded performance that only appear at scale.
Even a high-quality model that ticks all the other boxes may be unusable if it doesn’t scale with your customer demand. ElevenAgents is trusted by 1,000,000 leading creators and enterprises, demonstrating the platform’s ability to supply deployment at an enterprise scale without compromising on performance benchmarks.
How to measure MOS for voice agents (step-by-step)
If your business wants to measure MOS manually, you’ll need a large pool of human listeners and a selection of audio clips from real conversations. It’s a structured process that involves gathering feedback, averaging, and then interpreting the data.
Here’s how to measure MOS for voice agents in practice:
- Prepare your test set: Select a representative sample of audio outputs from your agent, covering at least 100 clips across a range of conversations.
- Run the rating session: Ask your human listeners to rate each on a scale of 1-5 based on the quality of the communication experience.
- Aggregate ratings and calculate scores: Average ratings across each clip, then average across all of your sample clips to produce an overall MOS. A MOS of 4.3 or higher indicates that your voice agent is ready for production.
Although manually intensive, this process will give you a solid MOS for your chosen voice agent. If you want to run the test at scale, you could replace human listeners with automated tools like NISQA, which predict MOS scores programmatically. You could integrate these systems into your active pipelines to continuously monitor MOS over time.
AI vs. human testing benchmarks: FCR, AHT, and CSAT
While calculating MOS repeatedly over time is a way to see model improvement or regression, you can bring in extra context by benchmarking against human performance. Seeing what humans actually achieve in similar roles will demonstrate whether your voice agent is performing close to an ideal level.
Here are a few metrics to consider for AI vs. human testing benchmarks.
AI agents should be able to match human FCR and CSAT while significantly improving AHT. The latter enhancement is due to AI agents typically handling conversations that are more general than human agents. Many businesses implement a workflow where AI agents are the first responders, only then passing calls to human agents if they are too complex to handle autonomously.
2025 data from Poe, an AI comparison aggregator, reveals that ElevenLabs retained the strongest overall ability to fulfill requests, completing 74.4% of all incoming requests. Its success has translated into a quickly growing usage, with Eleven v3 and v2.5-Turbo accounting for over 60% of messages sent to AI models over time.
Messages sent to AI models over time, ElevenLabs leading the poe voice agent evaluation framework
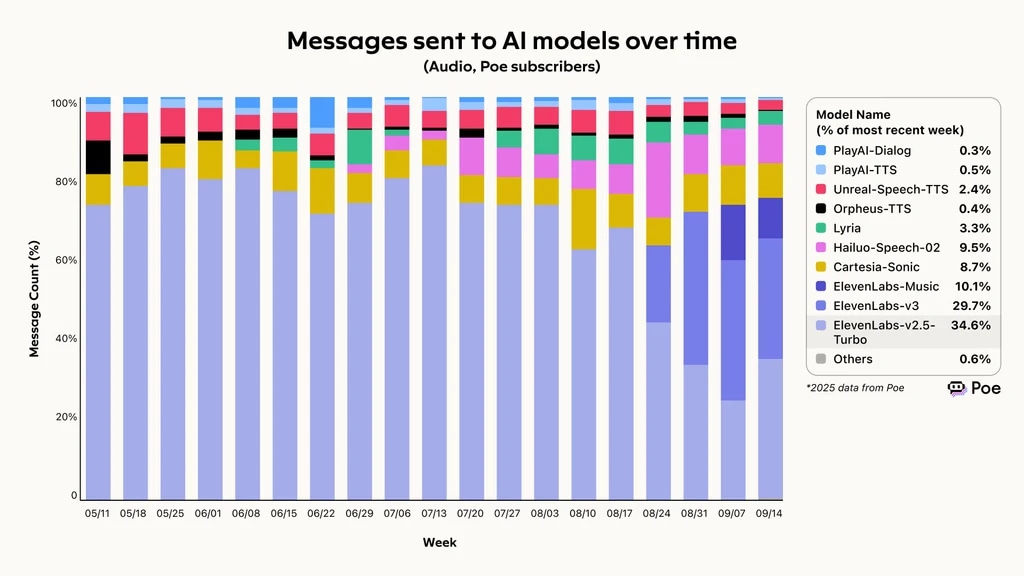
Messages sent to AI models over time, as benchmarked by Poe
Common voice agent testing mistakes
When following a voice agent evaluation framework, it’s tempting to test for best-case scenarios. The reality is, the day-to-day experience of customers interacting with your voice AI systems won’t stem from ideal conditions.
Here are three common voice agent testing mistakes and how to fix them:
- Testing the easiest path: Especially when selecting audio clips for MOS, be sure to include edge use cases. Clips with background noise or accented speech are extremely common in real life, so testing only on ‘clean’ audio files will lead to miscalibrating MOS.
- Prioritizing containment over resolution: Optimizing your models to keep users within your agent system inflates containment rates without improving outcomes. If your FCR is low despite a high containment rate, the agent is cycling users through a frustrating loop. Have practices in place to allow users to speak to human agents if they wish.
- Ignoring latency percentiles: SLAs often designate latency by the P95 level. While this metric is important for providing a consistent experience for the majority of your customers, don’t forget that the final 5% are also real customers. At scale, 5% of a system handling 10,000 daily calls is still 500 people experiencing a slow conversation. Focus on P99 as your headline SLA target, not median or P95 alone.
By keeping these in mind, you’re able to establish fair and representative baselines rather than working off idealized averages.
The argument for use-case-specific evaluations
While the six pillars mapped out in this framework provide guidance into the areas you should explore, the weighting of each pillar will depend on your industry. For example, a business in the financial services industry may prioritize compliance and tool usage, while a consumer brand would look to TTS voice quality as its guiding principle.
Here are two examples of use-case-specific evaluations in action and how they can shift the balance of each pillar.
Customer support
In certain industries, like in call centers, other task completion metrics like First Call Resolution (FCR) are an important part of the conversation. Being able to successfully handle an incoming call without human intervention significantly cuts back on demand placed upon human customer service agents. McKinsey estimates that call centers using voice agents can reduce interaction volume by up to 50%.
While not as important as task success rate, another dimension to consider here is containment rate. Containment rate is a metric that explores the total duration of a call. If your containment rate is very high but your FCR is low, then your agents are holding people on the line without providing a resolution to the customer. In practice, that could look like a frustrating experience of going in circles for the customer.
Other metrics to track would be AHT, with AI agents aiming to quickly solve routine problems. Due to that, the customer support field would prioritize conversation quality, especially in turn-taking and fallback rate, over other areas.
Healthcare
Healthcare is a highly regulated field, with stringent compliance requirements that make voice agent operation extremely delicate. Compliance is a central concern, shifting the weighting of the safety pillar of the framework significantly towards this and intelligence above all else.
Healthcare chatbots need to handle appointment scheduling, telehealth access pathways, symptom triage, and insurance questions. All of these require a high degree of intelligence and tool usage, once again reflecting that industry or role-specific demands influence which of the pillars is most important.
Whichever field your business works in, understanding the core pillars of voice agent evaluation and applying them in a balanced manner will help find the best agents for you.
Build with ElevenAgents for high performance and low latency
The platform you choose to build on directly influences how your voice agents perform in real workflows. Especially when interacting with your customers, you need to be confident that your agent will exceed in every category.
ElevenAgents is built for production voice deployments, combining industry-leading TTS via Eleven v3, real-time STT through Scribe v2, and an agent orchestration layer designed for enterprise scale. Every component is built to perform against the benchmarks set out in this framework, allowing you to deliver high-quality experiences to your customers.
Whether you’re weighing your options or are ready to start building, ElevenLabs has a path for you. Explore the ElevenAgents platform to see how it maps to your use case, or sign up and start building today.




