







Introducing Flows Agent in ElevenCreative
- Category
- Product
- Date
Dubbing v2 conditions on the source performance, not a transcript ‒ so tone, emotion, and delivery carry across every language, for true, authentic localization that is close to human quality.
Dubbing preserves the original performance across languages, maintaining emotion, tone, and timing.
Each translation is delivered in a voice clone of the original speaker, preserving identity, pitch, and tone without any manual setup.
Dubbing adapts phrasing and meaning for each target language, ensuring the result sounds natural to native audiences.
Supports source audio, source text, and target text. The full pipeline — translation, cloning, dubbing, and sync — runs automatically with no manual intervention.
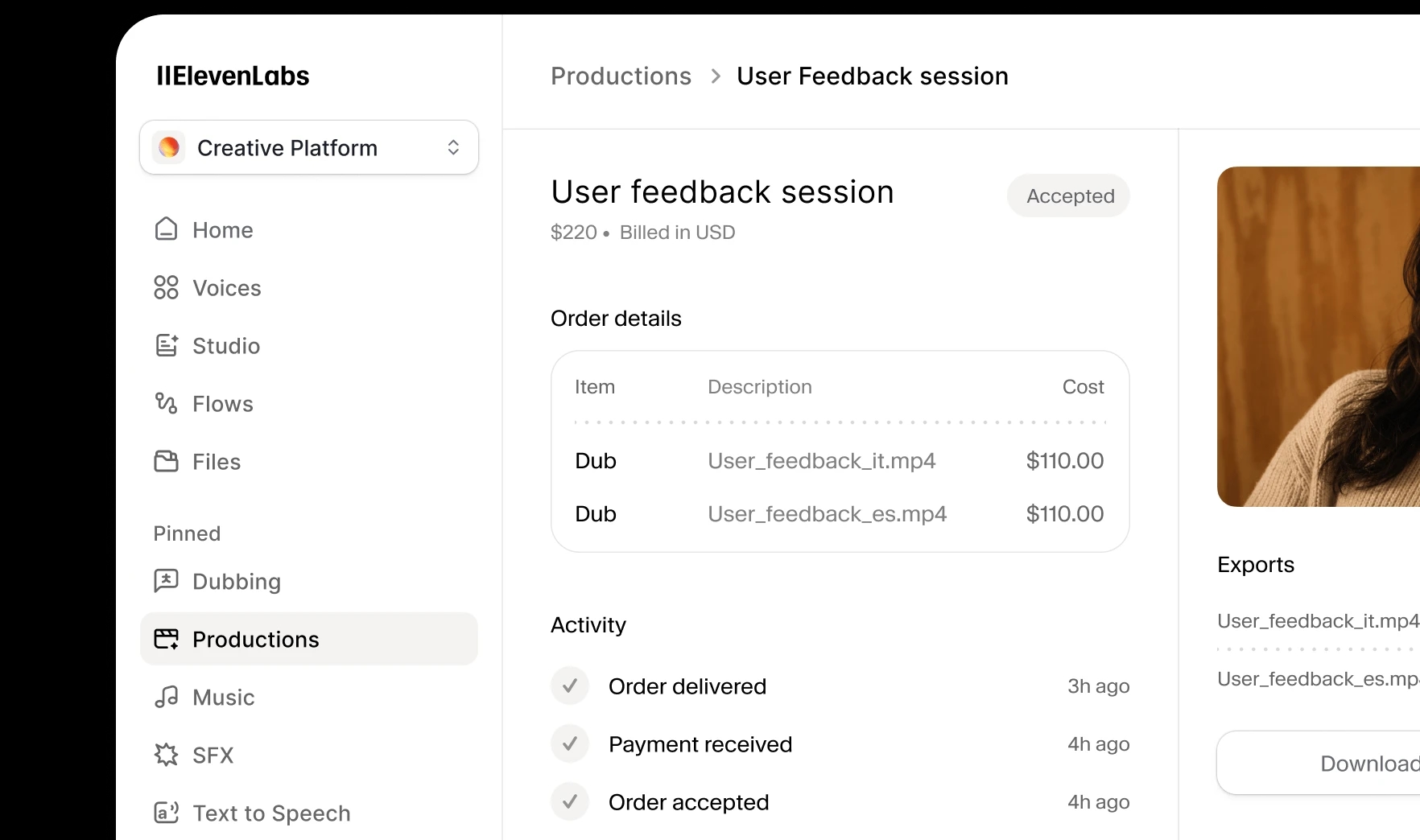
User feedback session
1h ago
Workshop script final
1d ago
Shell instruction manual draft
Apr 17
Every dub delivered in a voice clone of the original speaker while maintaining voice identity, pitch, and tonality.
The volume of Al-generated content will keep growing. We want to provide the needed transparency, helping verify the origins of digital content.
Dulce Arcand
CPO at Meta
One-click dubbing for creators, marketers, and teams. Upload your content, choose your languages, and get natural-sounding dubs ‒ no setup required.
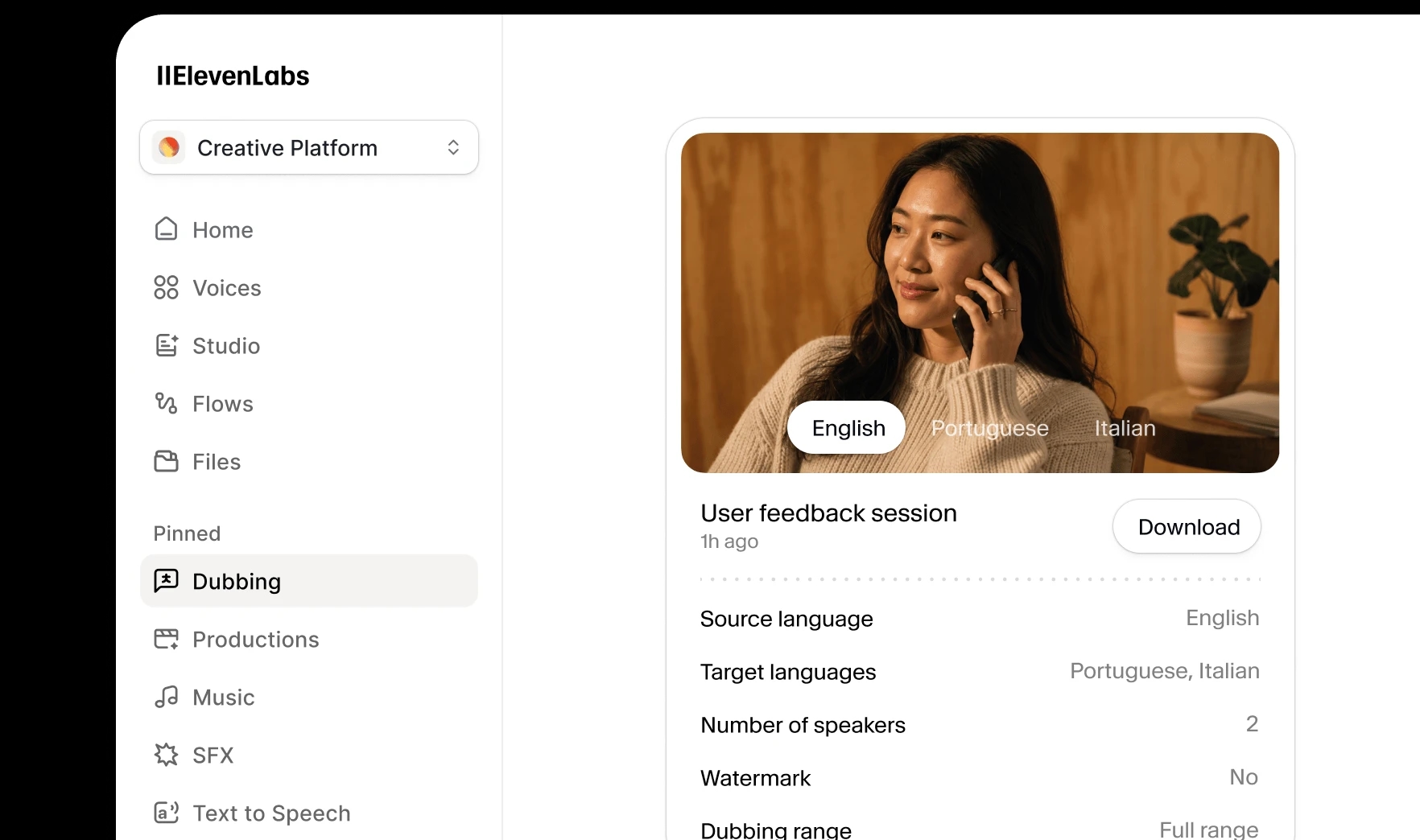
For studios and broadcasters with broadcast-quality requirements. Human translators, expert voice casting, and professional mixing ‒ with Dubbing v2 handling the audio.



.webp&w=3840&q=80)
.webp&w=3840&q=80)
