

ビデオとオーディオの編集、ボイスオーバーと音楽の追加、テキストへの書き起こし、ナレーション付きの字幕付き作品の公開までの完全なワークフロー

Text to Speech (TTS) 技術は、基本的に書かれたコンテンツを音声に変換します。近年、機械学習の大幅な進歩により、TTS 技術は進化し、合成音声が人間のナレーションとほとんど区別がつかないレベルに達しました。現代のTTSシステムが提供するリアリズムと表現力は、特に出版業界において比類のない可能性を秘めています。
ニュース出版社にとって、音の世界は新興分野であるだけでなく、エンゲージメントに必要不可欠です。オーディオプレゼンスを拡大することで、ユーザーの保持率と満足度が向上することが証明されています。従来の方法では、ボイスアクターを雇ったり、記者にナレーションを依頼したりしますが、これらの方法は時間とコストの効率が良くありません。テキスト読み上げを使用すれば、公開と同時にストーリーを音声化でき、コンテンツが常に新鮮で関連性があり、高品質であることを保証します。
非常に長いテキストでも人間らしい表現を実現する方法は、私たちのモデルの構築方法にあります。言葉の意味だけでなく、各発話の周囲の文脈も考慮して、何が言われているかを理解し、適切に調整します。何が言われているかを理解し、適切に調整します。言葉の意味だけでなく、各発話の周囲の文脈も考慮します。
従来の音声生成アルゴリズムは、文ごとに発話を生成します。これは計算負荷が少ないですが、すぐにロボットのように感じられます。感情やイントネーションは、特定の思考を結びつけるために、いくつかの文にわたって伸びて共鳴する必要があります。トーンとペースは意図を伝え、これが音声を人間らしく聞こえさせる要因です。したがって、各発話を個別に生成するのではなく、私たちのモデルは周囲の文脈を考慮し、生成された全体の素材にわたって適切な流れとプロソディを維持します。この感情的な深みと最高の音質が組み合わさり、ユーザーに最も本格的で魅力的なナレーションツールを提供します。
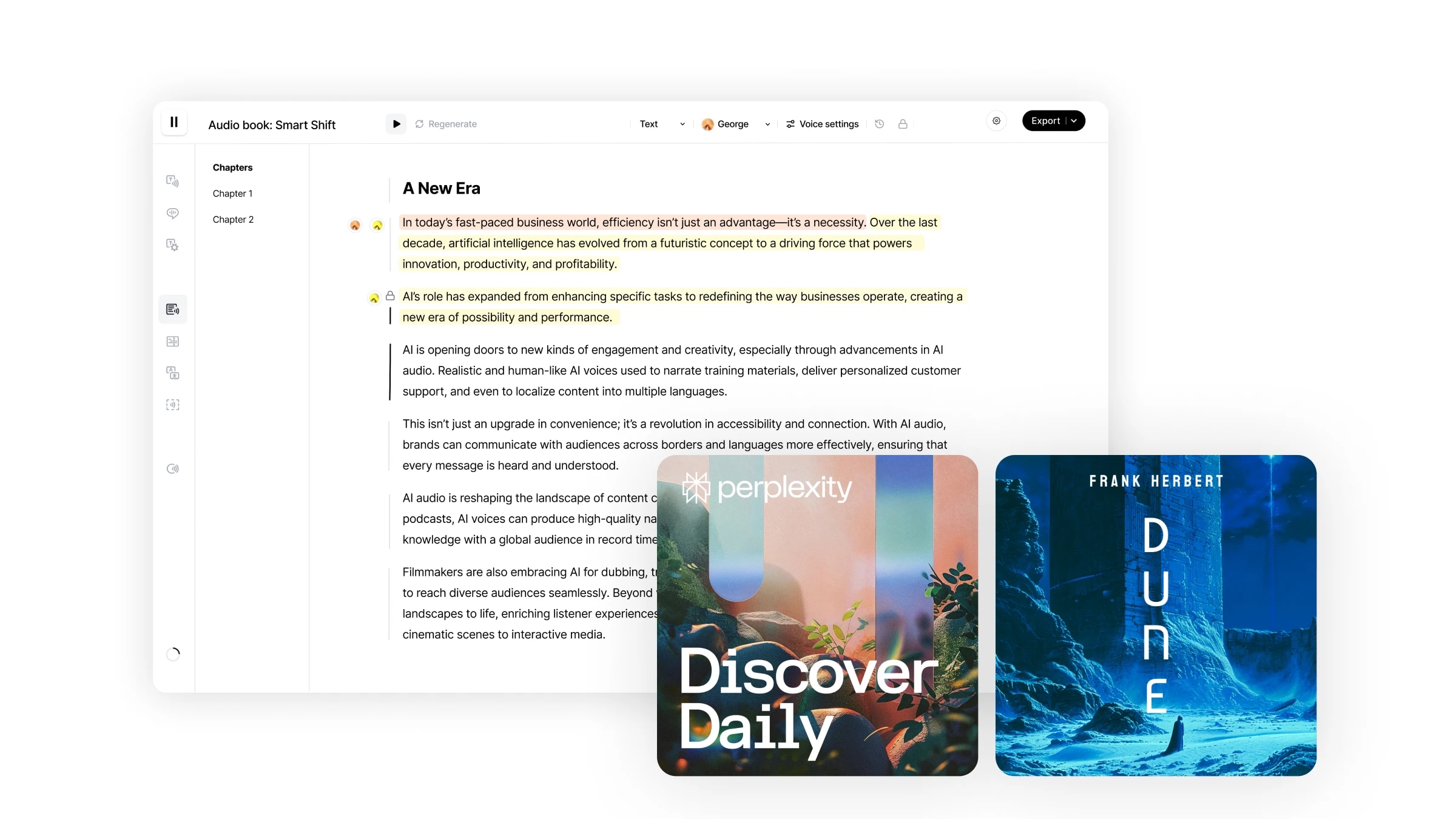
スタジオは、オーディオブックを数分で作成するためのエンドツーエンドのワークフローです。特定のオーディオチャンクを再生成したり、特定のテキストフラグメントに異なるスピーカーを割り当てたり、複数の形式のファイルを直接インポートしたりする能力を備え、オーディオ作成に対する前例のないレベルのコントロールを提供します。
Studioの操作は簡単で直感的です。
Studioは、Googleドキュメントを使用するようなシンプルなユーザー体験を提供し、さまざまな編集機能をサポートする直感的でユーザー中心のインターフェースを備えています。
ビデオとオーディオの編集、ボイスオーバーと音楽の追加、テキストへの書き起こし、ナレーション付きの字幕付き作品の公開までの完全なワークフロー
Studioは、音声合成、ボイスラボ、およびVoice Libraryと共に、長編オーディオ合成の包括的なソリューションとして機能します。さらに、プロフェッショナル ボイスクローン、ボイスライブラリー、および多言語モデルとシームレスに統合されています。
ElevenLabsでは、革新への取り組みが新しい多言語モデルの立ち上げにつながりました。これにより、同じナラティブを最大28言語で翻訳し、音声化することができます。出版社にとって、これは前例のないグローバルリーチを意味し、異なる文化や地域に響くストーリーを一貫した統一された声で届けることができます。
現在サポートされている言語は次のとおりです: 英語、韓国語、オランダ語、中国語、トルコ語、スウェーデン語、インドネシア語、フィリピン語、日本語、ウクライナ語、ギリシャ語、チェコ語、フィンランド語、ルーマニア語、デンマーク語、ブルガリア語、マレー語、スロバキア語、クロアチア語、古典アラビア語、ポーランド語、ドイツ語、スペイン語、フランス語、イタリア語、ヒンディー語、ポルトガル語、タミル語。
私たちの独自のVoice Designツールは、出版社に変革的な体験を提供します。年齢、性別、アクセントなどの選択したパラメータに基づいて完全にユニークな声を作成することを可能にします。生成されたすべての声はユニークであり、出版社が特定の声をブランドや出版物と同義にすることができます。
プロフェッショナル ボイスクローン (PVC)技術は、ElevenLabsでのカスタマイズのもう一つの層を提供します。出版物の記者の声をクローンすることで、彼らの独自のトーンでオーディオストーリーを作成できます。これにより、信頼性が提供されるだけでなく、従来の録音プロセスにかかるコストと時間を大幅に削減します。さらに、私たちの多言語モデルはプロフェッショナル ボイスクローンと互換性があり、記者の声がサポートされているすべての言語を話すことができるようになりました。

動画のボイスオーバー、広告、ポッドキャストなどを、ご自分の声で自動化できます
プロフェッショナル ボイスクローンツールで生成されたポッドキャストエピソードを聞いてみてください:
出版社にとって、プロフェッショナル ボイスクローン (PVC) は多くの利点を提供します:
テキスト読み上げ技術と組み合わせることで、出版社は豊かで多様なグローバルオーディオコンテンツを制作するための最先端のツールキットを手に入れます。プロフェッショナル ボイスクローン技術の能力を採用することは、出版社にとって進歩的な動きであり、多くの機会を開きます。
出版の未来は、単に書かれた言葉だけでなく、それらの言葉がどのように伝えられるかにあります。テキスト読み上げのようなツールを使用することで、出版社はコンテンツ配信を革新し、アクセス性、独自性、グローバルリーチを確保する可能性があります。ElevenLabsでは、この変革の最前線に立ち、より豊かで多様なオーディオ体験への道を開く技術を提供しています。
更新: 2025年1月現在、ProjectsはStudioと呼ばれ、すべての無料ユーザーに利用可能です。

Demand for digital tour guides rises with 10k+ tours taken and an average of 53 minutes listening time per session

Supporting 10,000+ research conversations with natural, trustworthy voices
Powered by ElevenLabs エージェント