Text to Speech vs Speech to Text: Qual è la differenza?
- Pubblicato
- Ultimo aggiornamento
AscoltaAscolta questo articolo
Immagina questa scena: stai guidando verso il lavoro e il tuo smartphone ti legge le email non lette grazie altext-to-speech (TTS). Ancora meglio, puoi inviare le risposte senza nemmeno toccare il telefono o distogliere lo sguardo dalla strada—tutto grazie alSpeech to Text (STT).
Queste tecnologie non sono solo idee futuristiche: stanno diventando parte integrante della nostra vita quotidiana, semplificando le attività di tutti i giorni e migliorando l’accessibilità.
Scopriamo insieme il mondo del TTS e STT basati su intelligenza artificiale: vediamo cosa sono, in cosa si differenziano, come funzionano, cosa valutare nei fornitori di TTS e STT e i tanti modi in cui vengono utilizzati nei diversi settori.
Le differenze tra TTS e Text From Speech
Ci sono alcune differenze fondamentali traTTS e la tecnologia text-from-speech. Ecco quali sono.
Funzionalità
Il TTS (Text to Speech) trasforma il testo scritto in parole pronunciate, mentre lo Speech to Text (STT) fa l’opposto, trascrivendo le parole pronunciate in testo. Il TTS serve a rendere udibile un contenuto scritto, diventando un assistente vocale per chi ha disabilità visive o difficoltà di apprendimento. Lo STT, invece, cattura il linguaggio parlato e lo trasforma in una trascrizione scritta, utile per la dettatura e i comandi vocali.
Contesto d’uso
Il TTS viene spesso integrato in e-reader, sistemi di annunci pubblici e assistenti virtuali per fornire output audio. Lo STT trova applicazione nei servizi di trascrizione, nelle app controllate dalla voce e nei sottotitoli in tempo reale per persone con problemi di udito. Il TTS viene usato soprattutto per fornire informazioni in formato audio, mentre lo STT è centrato sull’input, cioè sulla cattura e l’elaborazione del linguaggio parlato.
Approccio tecnologico
La tecnologia TTS coinvolge l’analisi del testo, l’elaborazione del linguaggio e la sintesi vocale. Deve riprodurre in modo accurato le sfumature del parlato, come intonazione e ritmo. Lo STT richiede invece capacità avanzate di riconoscimento vocale per trascrivere correttamente accenti, dialetti e diversi modi di parlare, spesso in tempo reale.
Cos’è il TTS (Text to Speech)?
Il TTS (Text to Speech) è una tecnologia che trasforma il testo scritto in parole pronunciate. In sostanza,il TTSpermette ai computer di leggere ad alta voce, trasformando qualsiasi testo in una voce sintetica. Questa tecnologia viene usata in molte applicazioni, dagli assistenti virtuali agli strumenti di accessibilità per chi ha difficoltà di lettura.
Un esempio di TTS avanzato è quello di ElevenLabs. Il TTS di ElevenLabs si distingue per la capacità di produrre voci estremamente naturali e simili a quelle umane. Questo risultato si ottiene grazie ad algoritmi di IA sofisticati che non solo imitano il suono della voce umana, ma comprendono e riproducono anche le sfumature e le inflessioni tipiche del parlato naturale.
Questo livello di realismo rende il TTS di ElevenLabs ideale per creare contenuti audio coinvolgenti per diversi media, migliorare le interfacce utente con feedback vocali e offrire un’alternativa accessibile alla lettura per chi ha disabilità visive.
Cos’è il Text from Speech (Speech to Text, STT)?
Text from Speech, also known as Speech to Text (STT), is the process of converting spoken language into written text. This speech recognition technology is pivotal in creating transcriptions from audio recordings, enabling voice commands, and facilitating real-time captioning for accessibility.
ElevenLabs made significant advancements in STT technology. Our Scribe model efficiently converting audio and video into text in 99 languages. It offers a user-friendly interface, making it ideal for capturing meetings, lectures, and interviews in written form, from audio and video files.
Come funziona il TTS?
La tecnologia TTS (Text to Speech) trasforma il testo scritto in parlato, attraverso diversi passaggi complessi.
All’inizio, il sistemaTTSanalizza il testo e lo suddivide in fonemi, cioè le unità di suono più piccole di una lingua. Questa suddivisione è fondamentale per permettere al sistema di pronunciare correttamente le varie parole.
Dopo la segmentazione in fonemi, il sistema converte questi suoni in parlato digitale. Qui entra in gioco l’intelligenza artificiale (IA): grazie ad algoritmi addestrati su grandi quantità di parlato, il sistema riesce a produrre una voce che riprende toni e ritmi umani. Il parlato generato viene poi allineato ai fonemi individuati, dando come risultato un audio naturale.
Grazie ai progressi dell’IA e del machine learning, oggi le tecnologieTTS sono molto più evolute. Sono in grado di cogliere le sfumature del contesto, supportare più lingue e imitare in parte anche le inflessioni emotive. Questi miglioramenti rendono il parlato generato molto più naturale e coinvolgente nell’interazione con i dispositivi digitali.
Quali sono i migliori fornitori di TTS?
The best TTS software solutions are ElevenLabs, Murf, and PlayHT. Here’s a brief rundown of their main features, pros, cons, and rating out of 5.
Come funziona lo Speech to Text?
La tecnologia Speech to Text (STT) trasforma il linguaggio parlato in testo scritto attraverso un processo articolato in più fasi.
Per prima cosa, vengono catturate le parole pronunciate, di solito tramite un microfono. Questo input audio viene poi convertito in un formato digitale che il sistema può elaborare. Il cuore dello STT è la capacità di analizzare questo audio digitale, suddividendolo in segmenti più piccoli e riconoscibili grazie ad algoritmi avanzati.
Questi segmenti sono i fonemi, le unità di suono più piccole del parlato. Il sistema STT confronta i fonemi con un modello linguistico predefinito per identificare parole e frasi. Questo passaggio è fondamentale per riconoscere accenti, dialetti e variazioni nel modo di parlare.
Successivamente, il sistema applica tecniche di elaborazione del linguaggio naturale (NLP). L’NLP aiuta a comprendere il contesto e la sintassi del parlato, permettendo trascrizioni più accurate. Consente anche di gestire strutture frasali complesse e termini tecnici specifici di un settore.
I sistemi STT più avanzati utilizzano algoritmi di machine learning e deep learning, che migliorano con l’uso e con l’aumento dei dati disponibili. Queste tecnologie permettono al sistema di apprendere nuovi accenti, modi di parlare e persino lingue diverse nel tempo, aumentando precisione ed efficienza.
In sintesi, la tecnologia STT prevede la cattura dell’audio, l’analisi fonemica, la modellazione linguistica e l’NLP, il tutto supportato dal machine learning, per convertire efficacemente il parlato in testo.
Quali sono i migliori fornitori di Speech to Text?
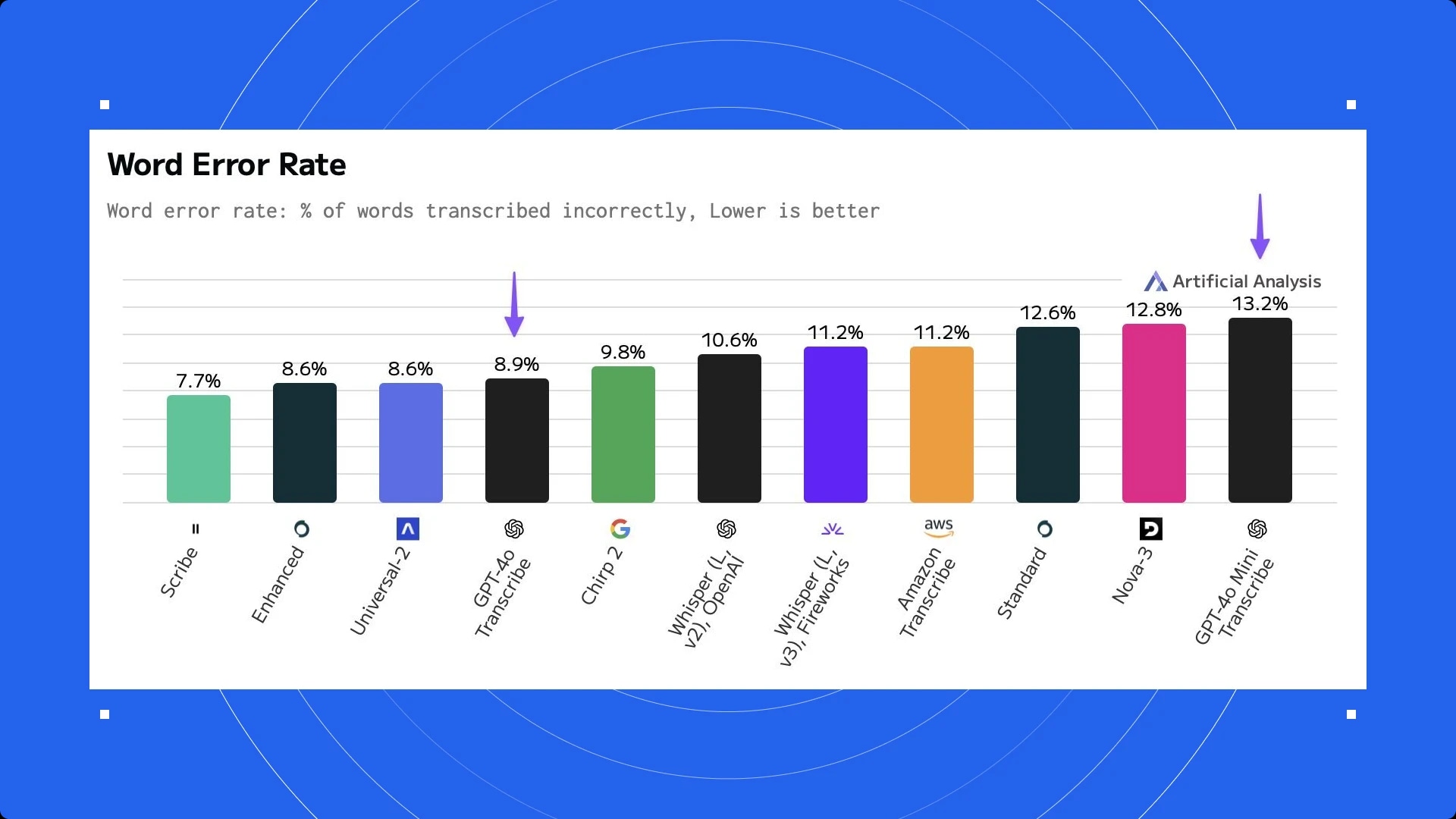
The best speech-to-text providers are ElevenLabs' Scribe, followed by OpenAIand other providers like Google.
TTS e STT: precisione e sfide
Le tecnologie TTS e Speech to Text puntano a una precisione simile a quella umana. La loro accuratezza è in costante miglioramento, ma non è ancora perfetta. Ecco cosa aspettarsi in termini di precisione e sfide per entrambe le tecnologie.
Precisione e sfide del TTS (Text to Speech)
La voce IATTS è molto migliorata, ma ci sono ancora delle sfide. La principale è ottenere voci umane davvero naturali. Anche se i sistemi TTS moderni producono audio chiaro e comprensibile, riprodurre inflessioni ed emozioni umane resta difficile. Inoltre, il TTS può avere problemi a interpretare il contesto, a volte sbagliando la pronuncia di alcune parole. Un’altra sfida è la personalizzazione delle voci per adattarsi a esigenze diverse, come accenti e stili di parlato, fondamentale per l’accessibilità globale.
Precisione e sfide del Text from Speech/Speech to Text (STT)
La tecnologia STT ha fatto grandi passi avanti in termini di precisione, soprattutto grazie al deep learning. Tuttavia, incontra difficoltà in ambienti rumorosi, dove i suoni di fondo possono interferire con il riconoscimento vocale. Trascrivere correttamente accenti e dialetti diversi è un’altra sfida importante. Inoltre, i sistemi STT spesso faticano con gli omofoni (parole che suonano uguali ma hanno significati diversi) e con la comprensione di strutture sintattiche complesse o slang, il che può limitarne l’efficacia nelle applicazioni reali.
Applicazioni nei diversi settori
Le tecnologie TTS e Speech to Text hanno trovato applicazioni innovative in moltissimi settori, trasformando il modo in cui interagiamo con le informazioni e migliorando l’accessibilità.
Applicazioni del TTS nei settori
La tecnologia TTS viene utilizzata in diversi ambiti. Nell’istruzione, aiuta a creare materiali didattici accessibili per studenti con difficoltà di lettura o disabilità visive, ad esempio trasformando i libri di testo in audiolibri.
Nel settore automotive, il TTS gestisce le risposte vocali nei sistemi di navigazione. Nel customer service viene usato per risposte automatiche nei call center, migliorando l’efficienza. Inoltre, il TTS è fondamentale nell’intrattenimento, soprattutto nei videogiochi e negli assistenti virtuali, dove offre esperienze interattive.
Applicazioni dello STT nei settori
La tecnologia STT trova applicazione in molti settori diversi. In ambito sanitario, aiuta a trascrivere le conversazioni tra medico e paziente e a dettare la documentazione clinica, migliorando l’efficienza. Nel settore legale, lo STT viene usato per trascrivere udienze e documenti giuridici. È fondamentale anche nei media, dove permette la sottotitolazione in tempo reale delle trasmissioni per le persone con problemi di udito. Nel mondo aziendale, lo STT facilita la trascrizione delle riunioni, migliorando la gestione e l’accessibilità delle informazioni.
Considerazioni finali
Le tecnologie TTS (Text to Speech) e Speech to Text (STT), pur sembrando simili, hanno funzioni ben distinte. Il TTS trasforma il testo scritto in parole pronunciate, dando vita ai contenuti scritti con voci simili a quelle umane. Lo STT, invece, fa l’opposto: converte le parole pronunciate in testo scritto, catturando le sfumature del parlato in formato testuale.
Entrambe sfruttano l’IA avanzata, ma rispondono a esigenze diverse:il TTS per ascoltare contenuti scritti, lo STT per creare trascrizioni di ciò che viene detto.
Vuoi iniziare? Prova Eleven v3, il nostro modello text-to-speech più espressivo di sempre.
Se vuoi provare la tecnologia TTS più avanzata,registrati su ElevenLabs oggi stesso. Non te ne pentirai.



