
Eleven v3 Audio Tags: Esprimere il contesto emotivo nel parlato
- Categoria
- Risorse
- Data
Come costruiamo sistemi IA che comunicano in tempo reale: le scelte tecniche dietro la gestione dei turni, la latenza, l’espressività e i modelli che abbiamo rilasciato.

Da anni lavoriamo per arrivare a questa categoria. In questo post raccontiamo cosa abbiamo realizzato e le scelte di ricerca e prodotto che ci sono dietro.
Il nostro prodotto di punta - ElevenAgents con v3 Conversational
Expressive Mode - Mark - Richiesta prestito personale in entrata (Panico) - launch asset.mp4
Cosa serve per far funzionare un modello di interazione
Tre elementi devono funzionare insieme perché un sistema di interazione sia efficace e crei conversazioni naturali e coinvolgenti:
Cosa abbiamo già realizzato
Eleven v3 Conversational.La nostra variante conversazionale di v3, lanciata all’interno di ElevenAgents a febbraio 2026 con gestione dei turni integrata. Il modello di turn-taking è attivo di default quando scegli v3 Conversational come modello TTS.
Turn-taking speculativo.Una funzione separata di v3 Conversational che anticipa la generazione della risposta LLM durante i silenzi dell’utente, riducendo la latenza percepita.
Flash v2.5.Il nostro modello Text to Speech più veloce, pensato per l’uso in tempo reale a bassa latenza, con inferenza di circa 75 ms.*
Scribe v2.Il nostro modello Speech to Text con un’accuratezza ai massimi livelli del settore.
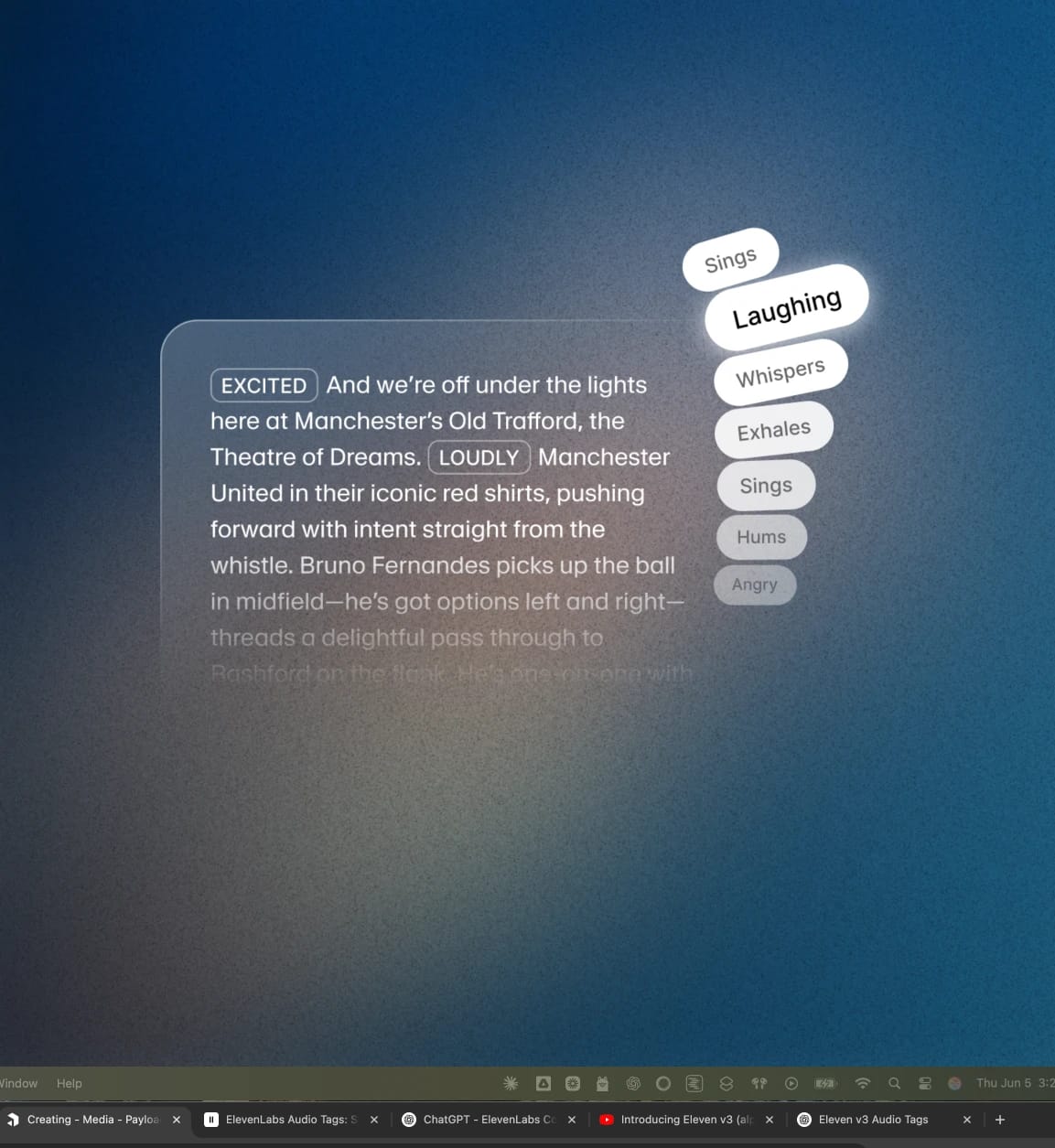
Modalità espressiva ElevenAgents.Permette agli agenti di usare tag espressivi come [ride], [sussurra], [sospira] e [lento] per controllare la resa in base al contesto.
Modalità Espressiva di ElevenAgents. Permette agli agenti di usare tag espressivi come [ride], [sussurra], [sospira] e [lento] per controllare la resa in base al contesto.
Dove stiamo andando
Molte conversazioni con l’IA sembrano ancora semplici richieste. Le vere conversazioni non sono così. Ridurre questa distanza è il nostro obiettivo.



