Was ist Generative KI-Audio? Alles, was Sie wissen müssen
KI-Audio verändert Klang und Industrie. Sie erfahren mehr über Text-to-Speech, Voice Cloning, Videoübersetzung und andere aufkommende Technologien – und sehen, wie sie sich auf Unternehmen auswirken.
Einführung in KI-Audio
Mit neuen technologischen Entwicklungen, die das Unvorstellbare zur Realität machen, kann es schwierig sein, Schritt zu halten. Dieser Artikel bringt Sie auf den neuesten Stand der sich schnell entwickelnden Welt des KI-gesteuerten Audios und zeigt, wie es Ihnen zugutekommen kann.
Wir beginnen mit einer Erkundung von KI-Text-to-Speech (KI TTS) – eine spannende Technologie, die unsere Interaktion mit Audio revolutioniert. Aber es hört hier nicht auf; wir werden das gesamte Spektrum des generativen KI-Audios abdecken, von Voice Cloning bis hin zu KI-Dubbing und darüber hinaus.
KI-gesteuertes Audio – Warum es wichtig ist
In diesem Leitfaden erfahren Sie die leistungsstarken Fähigkeiten von KI-gesteuerten Audiotechnologien und sehen, wie sie Veränderungen in verschiedenen Branchen vorantreiben. Diese Technologie bietet viele überzeugende Vorteile und verändert die Landschaft der Audiogenerierung.
Vielleicht am wichtigsten ist die Geschwindigkeit und Genauigkeit von KI-TTS, das Stimmen erzeugen kann, die praktisch nicht von menschlicher Sprache zu unterscheiden sind. Es hat kürzlich die Audioproduktion einem viel breiteren Publikum zugänglich gemacht, da KI-TTS und generatives Audio jetzt eine kostengünstige Alternative zu herkömmlichen Sprachaufnahmen und Dubbing bieten.
KI-Audio spielt auch eine große Rolle bei der Verbesserung der Zugänglichkeit, da es digitale Inhalte inklusiver macht. Dies führt zu bereicherten Benutzererfahrungen auf verschiedenen Plattformen und bietet eine dynamische auditive Dimension für Benutzerinteraktionen. Diese Auswirkungen des generativen KI-Audios sind besonders im Film, Gaming und der Inhaltserstellung prominent, wo es schnell an Popularität gewinnt.
Bevor wir tief in KI-Audio eintauchen, lassen Sie uns sicherstellen, dass wir alle auf dem gleichen Stand sind. Wir werden jeden Begriff weiter erkunden, aber wir beginnen mit einer einfachen Definition der Schlüsselbegriffe.
KI-Generatives Audio - Schlüsselbegriffe
KI-Generatives Audio - Schlüsselbegriffe
Begriff
Definition
KI-Text-to-Speech (KI TTS):
Wandelt geschriebenen Text in lebensechte gesprochene Worte um, indem künstliche Intelligenz-Algorithmen und Sprachsynthesetechnologie verwendet werden.
KI-generative Stimmen:
Sind lebensechte, anpassbare Stimmen, die von künstlichen Intelligenzmodellen erstellt werden und eine Vielzahl von Tonhöhen und Akzenten für unterschiedliche Anwendungen bieten.
KI-Voice Cloning:
Beinhaltet die Erstellung einer künstlichen Replik einer Person, indem fortschrittliche KI-Algorithmen und Deep-Learning-Methoden eingesetzt werden.
KI-Dubbing:
Verwendet künstliche Intelligenz, um Audioinhalte in Filmen, Videos oder Spielen nahtlos zu ersetzen – oft für Lokalisierung oder Übersetzung.
KI-Musik:
Erstellt und verbessert Musikstücke durch generative KI-Modelle, maschinelle Lerntechniken und spezialisierte Musikgenerierungsalgorithmen.
Die Möglichkeiten von KI-Audio
KI-gesteuerte Audiotechnologien sind mehr als nur Schlagworte; sie verändern die Art und Weise, wie wir Audio erleben und damit interagieren. Täglich werden mehr Branchen unterstützt, aber um einige reale Beispiele hervorzuheben: Frühe Anwender genießen ihre Lieblingsbücher, die von einem Erzähler ihrer Wahl gelesen werden, KI-Anime-Dubbing erhöht die Zugänglichkeit, und KI-generierte Podcasts gewinnen an Bedeutung.
Lesen Sie weiter, um zu erfahren, wie generatives Audio funktioniert und seine Auswirkungen auf verschiedene Branchen zu verstehen. Beginnen wir unsere Reise mit einem genaueren Blick auf KI-Text-to-Speech.
KI-gesteuerte Audiotechnologien entwickeln sich unglaublich schnell. Um diese Innovationen wirklich zu schätzen, ist es jedoch wichtig, den Grundstein zu verstehen, auf dem sie aufgebaut sind. Hier kommt KI-Text-to-Speech (KI TTS) ins Spiel. In diesem Abschnitt werden wir die Geschichte, Funktionalität und den bedeutenden Einfluss der Text-to-Voice-Technologie erkunden, die in verschiedenen Branchen gemacht wird.
KI-Text-to-Speech ist eine komplexe Technologie mit einem einfachen Zweck – sie wandelt geschriebene Texteingaben in lebensechte gesprochene Worte um. Dies wird durch ausgeklügelte Algorithmen und fortschrittliche Sprachsynthesetechniken erreicht. Inhaltserstellung, -konsum und -zugänglichkeit wurden alle durch diese neue Ära des KI-Audios transformiert.
Erstellen Sie menschenähnliche Stimmen mit unserem Text to Speech (TTS) System, entwickelt für hochwertige Erzählungen, Gaming, Video und Barrierefreiheit. Ausdrucksstarke Stimmen, mehrsprachige Unterstützung und API-Integration erleichtern die Skalierung von persönlichen Projekten bis hin zu Unternehmensabläufen.
Eine Reise durch die Geschichte
Um das Ausmaß der Fortschritte von KI-TTS wirklich zu verstehen, ist es entscheidend, einen kurzen Blick auf seine Geschichte zu werfen. Die Text-to-Speech-Technologie hat einen langen Weg zurückgelegt seit ihren Anfängen, als synthetisierte Stimmen oft roboterhaft und emotionslos klangen.
Bemühungen, menschliche Sprache zu imitieren, erstrecken sich über Jahrhunderte, mit verschiedenen Versuchen im 19. Jahrhundert, die mechanische Stimmbänder, Zungen und Lippen einbezogen. Diese frühen Bemühungen waren unbeholfen und extrem begrenzt in ihrer Ausgabe. Die ersten erfolgreichen elektronischen TTS-Versuche entstanden in den späten 1950er Jahren, doch selbst neuere Beispiele fehlen die Qualität, die wir heute als Standard erwarten. Denken Sie an die ikonische Stimme von Stephen Hawking oder den künstlichen Ton, der in frühen Navigationssystemen verwendet wurde:
„Bitte nehmen Sie die nächste links, um Ihr Ziel zu erreichen.“
Zu dieser Zeit wurde dieses Niveau der synthetisierten Sprache als hochmodern angesehen. Heute bringt KI-TTS ein Maß an Realismus in die Stimmerzeugung, das einst unvorstellbar war – sogar Emotionen zu vermitteln.
Wie funktioniert KI-TTS?
Im Kern von KI-TTS steht die Fähigkeit, Text zu analysieren und seine Nuancen zu verstehen. Betrachten Sie, wie Sie einen Satz lesen – Sie nehmen intuitiv wahr, wo die Intonation steigen und fallen sollte, wie gängige Phrasen flüssig von der Zunge rollen sollten, und verstehen, wie Interpunktion die Gesamtlieferung eines Satzes beeinflusst.
Die Entwicklung von KI ist ein weites Feld, aber auf hoher Ebene waren Deep Learning und neuronale Netze entscheidend. Diese Fortschritte ermöglichen moderne KI-TTS-Modelle, den Text zu entschlüsseln, die geeigneten Intonationen zu bestimmen und sie in gesprochene Worte zu synthetisieren. Dieser Prozess beinhaltet das Training der KI mit umfangreichen Datensätzen menschlicher Sprache, wodurch sie Stimmen erzeugen kann, die nicht nur von Menschen ununterscheidbar sind, sondern auch Gefühle und nuancierte Bedeutungen kommunizieren können.
Grundlage für Generatives KI-Audio
KI-TTS ist beeindruckend in seiner eigenen Hinsicht, aber sein Wert wird wirklich deutlich, wenn es als Baustein für komplexere KI-Audioprogramme verwendet wird. Es ist der Eckpfeiler, auf dem andere generative KI-Audiotools aufgebaut sind. Die natürlichen, lebensechten Stimmen, die von KI-TTS erzeugt werden, werden zum Rohmaterial für Anwendungen wie Voice Cloning, Dubbing und vieles mehr.
Der Einfluss von KI-TTS auf verschiedene Branchen
Das Verständnis von KI-Text-to-Speech als Grundlage des generativen KI-Audios ist entscheidend, um das volle Potenzial dieser Technologie zu schätzen. Mit seiner reichen Geschichte, beeindruckenden Funktionalität und weitreichenden Auswirkungen bereitet KI-TTS die Bühne für die transformativen Technologien, die wir als nächstes erkunden werden.
Da KI immer besser darin wird, komplexe Eingaben zu verstehen, werden die Unterschiede zwischen Audio-, Text-zu-Bild- und Chatbot-Modellen verschwinden, sodass KI nahtlos übergreifende Aufgaben ausführen kann.“ – Ignaz Kowalczuk, Head of Comms, ElevenLabs
Von KI-Voiceovers in Bildung und Unterhaltung bis hin zu konversationellen, realistischen Sprach-Chatbots im Gesundheitswesen und Kundenservice – KI-TTS taucht in zahlreichen Branchen auf. In den kommenden Abschnitten werden wir genauer darauf eingehen, wie die Effizienz und Qualität von KI-TTS die Audioinnovation in jeder dieser Branchen unterstützt.
Lesen Sie weiter, um die faszinierende (und gelegentlich beängstigende) Welt des KI-Voice Cloning zu entdecken und wie es unsere Wahrnehmung der Stimmreproduktion verändert.
Lebensechte Stimmen gestalten: KI-Voice Cloning und Generative Voices
Es gibt zwei entscheidende Entwicklungen, die Innovationen in diesem Bereich vorantreiben: KI-Voice Cloning und generative Stimmen. In diesem Abschnitt erfahren Sie, wie wir lebensechte Stimmen mithilfe fortschrittlicher künstlicher Intelligenzmodelle erstellen können, und erhalten eine vereinfachte Erklärung dessen, was hinter den Kulissen vor sich geht.
Hier sind einige Klone von Freya und James (beide verfügbar auf der ElevenLabs-Plattform):
Freya - Real
/
Freya - Clone
/
James - Real
/
James - Clone
/
KI-Voice Cloning: Die Kunst der Stimmreplikation
Das Ziel des Voice Cloning ist es, eine künstliche Replik einer Person zu erstellen – wir wollen eine digitale Kopie der Stimme erstellen, die nicht vom Original zu unterscheiden ist. Dies wird durch den Einsatz modernster Algorithmen und Deep-Learning-Techniken ermöglicht.
Unser KI-basiertes Voice Cloning funktioniert ein wenig wie ein talentierter Imitator. Stellen Sie sich einen geschickten Nachahmer vor, der perfekt die Stimme und Sprachmuster einer Person kopieren kann. Sie können sich unsere Technologie als die digitale Form dieses Imitators vorstellen.
So funktioniert es: Zuerst haben wir etwas, das als "Sprecher-Encoder" bezeichnet wird. Stellen Sie sich dies als den Imitator vor, der der Stimme der Person zuhört und ihre einzigartigen Merkmale versteht. Er lernt, wie sie sprechen, ihre Tonhöhe, Intonation und ihren Akzent.
Als nächstes haben wir den "Generator". Hier nimmt der Imitator all das Gelernte und beginnt, für die Person zu sprechen. Es ist, als ob sie eine Maske der Stimme dieser Person tragen, und egal welchen Text Sie geben, sie sagen es genau so, wie es die Originalperson tun würde.
Ohne Feedback könnten wir jedoch sehr schlechte Stimmen erhalten, daher haben wir auch einen "Diskriminator". Dieser Teil fungiert wie ein Richter, der entscheidet, ob die Stimme des Imitators echt oder gefälscht klingt. Wenn sie die Originalstimme nicht genau nachahmt, wird sie abgelehnt und die anderen Teile werden angewiesen, es erneut zu versuchen.
Durch das Training dieser drei Teile mit vielen Sprachdaten wird unser KI-basierter Stimmgenerator zu einem Meisterimitator – er versteht alle Nuancen, die Stimmen einzigartig machen. Die Stimmen, die er erzeugt, sind so realistisch, dass man sie leicht mit der echten Person verwechseln könnte.
Dies eröffnet eine Reihe von Anwendungen, von Sprachassistenten, die berühmte Persönlichkeiten nachahmen, bis hin zu personalisierten Erzählungen für Hörbücher. Was einst auf Science-Fiction beschränkt war, ist jetzt eine alltägliche Realität.
Möchten Sie Ihre Stimme klonen?
Besuchen Sie unser Voice Lab, um Ihre erste geklonte Stimme zu erstellen. Es dauert nur eine 1-minütige Audioaufnahme, um eine Replik Ihrer Stimme zu erzeugen.
Automatisieren Sie Voiceovers für Videos, Werbung, Podcasts und mehr – mit Ihrer eigenen Stimme.
Generative Stimmen: Einzigartige und anpassbare Töne gestalten
Generative Stimmen stellen hingegen den Höhepunkt der KI-Audiosynthese dar. Künstliche Intelligenzmodelle treiben einen synthetischen Stimmgenerator an, der fein angepasst werden kann, um eine Vielzahl von Tonhöhen, Akzenten und Tönen zu bieten. Das Ergebnis ist eine nahezu unbegrenzte Vielfalt an lebensechten Stimmen, die auf verschiedene Anwendungen zugeschnitten werden können.
KI-generative Stimmen nutzen ähnliche neuronale Netzwerk-Audiogenerierung und Deep-Learning-Prozesse wie oben, aber der "Sprecher-Encoder" wird künstlich basierend auf den an ihn übermittelten Stimmanforderungen erzeugt. Da diese Modelle auf riesigen Datensätzen menschlicher Sprache trainiert werden, können sie die Nuancen der gesprochenen Sprache und die Feinheiten der Emotionen erfassen. Das Ergebnis ist eine grenzenlose Palette von Stimmen, die eine Vielzahl von Gefühlen vermitteln können, von Aufregung bis Empathie. Dies macht sie ideal für Anwendungen, bei denen emotionale Ausdruckskraft wichtig ist.
Anwendungen und Szenarien für generative Stimmen
KI-generative Stimmen bieten eine Vielzahl von Anwendungen in verschiedenen Branchen.
Im Unterhaltungsbereich erwecken sie animierte Charaktere mit authentisch klingenden Dialogen zum Leben.
Im Bildungsbereich ermöglichen sie personalisierte Lernerfahrungen, indem Benutzer ihren bevorzugten 'Lehrer' auswählen können.
Digitale Assistenten können auf natürliche und ansprechende Weise mit Benutzern kommunizieren.
Inhaltsersteller können neues Material schneller, kostengünstiger und in gleichbleibend hoher Qualität erstellen.
Unternehmen können die Benutzerbindung und Zugänglichkeit steigern, indem sie automatisierten Diensten eine menschliche Note verleihen.
Schauen Sie sich die Stimmen an, die unsere Benutzer erstellt haben
Warum nicht eine Minute Zeit nehmen und einige von Benutzern generierte Stimmen durchsuchen? Such- und Filtertools erleichtern das Finden der perfekten Stimme.
Erstellen Sie menschenähnliche Stimmen mit unserem Text to Speech (TTS) System, entwickelt für hochwertige Erzählungen, Gaming, Video und Barrierefreiheit. Ausdrucksstarke Stimmen, mehrsprachige Unterstützung und API-Integration erleichtern die Skalierung von persönlichen Projekten bis hin zu Unternehmensabläufen.
Dies sind nur einige Beispiele dafür, wie KI-generative Stimmen verwendet werden, um ein besseres Erlebnis für den Endbenutzer zu schaffen. Lesen Sie weiter, um die Auswirkungen lebensechter generativer Stimmen in den Bereichen Film, Gaming, Inhaltserstellung und mehr zu entdecken.
KI im Audio-Dubbing und der Inhaltserstellung
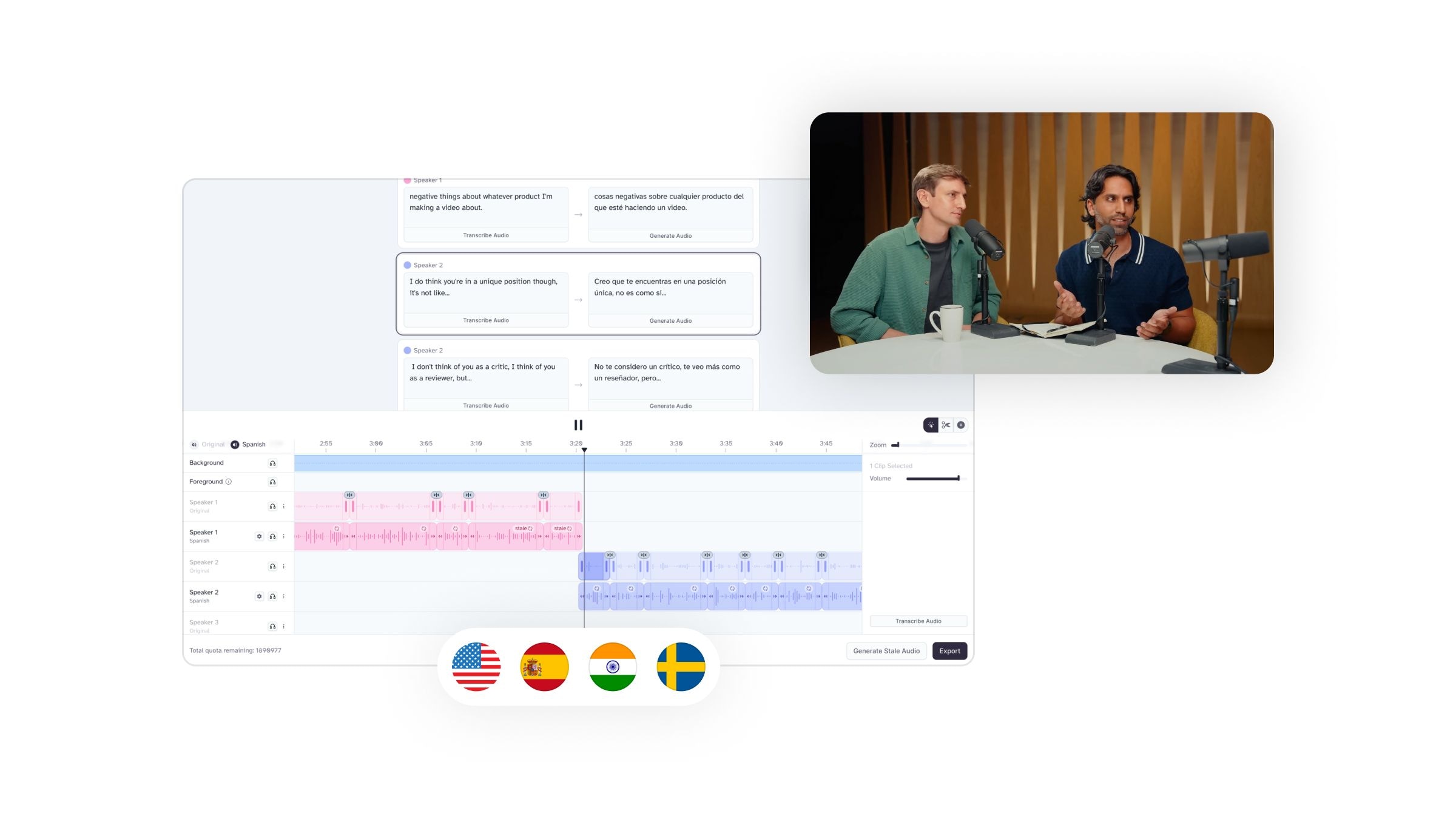
Mit einem soliden Verständnis von KI-Text-to-Speech, KI-Voice Cloning und generativen Stimmen sind wir nun bereit, genauer zu betrachten, wie es auf Audio-Dubbing und Inhaltserstellung angewendet wird.
KI in der Filmindustrie
Die Welt des Films erlebt eine KI-gesteuerte Revolution im Audio-Dubbing und der Lokalisierung. Stellen Sie sich vor: ein klassischer ausländischer Film, wunderschön in Ihrer Muttersprache synchronisiert, mit den Stimmen Ihrer Lieblingsschauspieler, die mühelos von den Lippen der Charaktere fließen. Es ist nicht nur Science-Fiction; KI-gesteuerte Audiotechnologie macht dies zur Realität.
Mit KI-Voice-Dubbing-Tools können Filmemacher Audiomaterial nahtlos ersetzen und sicherstellen, dass ein globales Publikum den Film in ihrer bevorzugten Sprache genießen kann. Es wird bereits umgesetzt; der nordamerikanische Streaming-Dienst Topic nutzt die Technologie, um ihren fremdsprachigen Katalog englischsprachigen Zuschauern zugänglich zu machen.
KI in der Gaming-Industrie
Die Anwendungen im Gaming sind immens. Ob es darum geht, dynamische und ausdrucksstarke Dialoge für nicht spielbare Charaktere (NPCs) zu liefern, wie in unserer Zusammenarbeit mit Inworld, oder das Dubbing von In-Game-Erzählungen zu perfektionieren – KI glänzt darin, lebensechte Stimmen zu schaffen, die das Audioerlebnis für Spieler verbessern.
Darüber hinaus haben wir kürzlich mit dem Metaverse-Spiel BUD zusammengearbeitet, um es Spielern zu erleichtern, In-Game-Text in realistische Stimmen umzuwandeln. Dies bringt ein neues Maß an Immersion in benutzererstellte Erlebnisse, die über Grafik und Gameplay hinausgehen.
KI in der Inhaltserstellung
Inhaltsersteller in der digitalen Landschaft begrüßen KI in ihren Arbeitsabläufen. Mit der Fähigkeit, hochwertige, natürlich klingende Stimmen und Erzählungen zu erzeugen, beschleunigt KI den Inhaltserstellungsprozess, senkt die Kosten und sorgt für Konsistenz in der Qualität.
Sie müssen nur einen TikTok-Feed öffnen, und Sie werden schnell Beispiele für Erfolgsgeschichten von Inhaltserstellern finden – Millionen von Aufrufen auf Kanälen, die auf Audioinhaltsautomatisierung setzen. Vermarkter, professionelle Inhaltsersteller und Hobbyisten finden alle kreative Anwendungen für generatives Audio. Die Möglichkeiten sind vielfältig, und täglich entstehen neue Anwendungen.
Möchten Sie die Kraft des KI-Dubbings sehen?
Probieren Sie unser kostenloses KI-Dubbing-Tool aus. Sie können ein Video hochladen oder einen Link von beliebten Videoplattformen wie YouTube, X (Twitter) und TikTok teilen.
Übersetzen Sie Audio und Video, während Sie die Emotion, das Timing, den Ton und die einzigartigen Merkmale jedes Sprechers bewahren
Lesen Sie weiter, um zu sehen, wie generatives Audio die Zugänglichkeit verbessert und virtuelle Realität (VR)-Erlebnisse schafft, die wirklich immersiv sind.
KI-Audio für Zugänglichkeit und Immersion in der virtuellen Realität
Die Fähigkeiten von generativem KI-Audio gehen weit über Unterhaltung hinaus; sie spielen eine entscheidende Rolle bei der Verbesserung der Zugänglichkeit für ein breiteres Publikum. Darüber hinaus verändert KI-gesteuertes Audio die Landschaft der virtuellen Realität (VR) und der erweiterten Realität (AR), indem es immersive Erlebnisse mit realistischen Stimmen und interaktiven Erzählungen zum Leben erweckt.
Digitale Inhalte inklusiv gestalten
Um zu zeigen, wie KI-gesteuerte Audiotechnologien Inklusivität und Zugänglichkeit fördern, betrachten wir die lebensverändernde Kraft dieser Fortschritte mit Mark.
Mark ist ein begeisterter Leser und ein enthusiastischer Lerner. Mark steht jedoch vor einer erheblichen Herausforderung – er ist sehbehindert, was das Lesen von Standardtexten zu einer Herausforderung macht. Dieses Hindernis lässt ihn oft von der Fülle an Informationen und Unterhaltung, die online verfügbar sind, ausgeschlossen fühlen.
Alles änderte sich, als Mark KI-gesteuerte Online-Lesesoftware entdeckte. Diese leistungsstarke Technologie wandelt geschriebene Inhalte sofort in lebensechte gesprochene Worte um. Als er die Fähigkeiten des KI-Textlesers erkundete, fühlte Mark ein beispielloses Gefühl von Freiheit und Ermächtigung. Nicht mehr durch seine visuellen Einschränkungen behindert, konnte er digitale Inhalte mühelos zugreifen und genießen.
Die KI-Lesesoftware ermöglicht es Mark, seine Lieblingsbücher zu genießen, über Nachrichtenartikel auf dem Laufenden zu bleiben und sogar Online-Kurse zu belegen. Die digitale Welt, einst eine Herausforderung, ist jetzt sein zugänglicher Spielplatz.
Mark ist nicht allein; laut WHO-Forschung gibt es über 2,2 Milliarden Menschen mit Sehbehinderungen. Um es all diesen Nutzern wie Mark zu erleichtern, werden wir bald unseren eigenen Chrome-Erweiterungsleser veröffentlichen – entwickelt, um die Zugänglichkeit digitaler Inhalte weiter zu verbessern.
Digitale Zugänglichkeit kann schwierig sein, aber KI-Text-to-Speech macht es Menschen mit Behinderungen leichter, Online-Inhalte zu konsumieren. KI-gesteuerte Bildschirmleser wandeln Text in eine natürliche, leicht zu hörende KI-Lesestimme um, die ein bereichertes Surferlebnis für sehbehinderte Benutzer bietet. Darüber hinaus unterstützt KI-Audio auch inklusives Lernen, da es sicherstellt, dass Bildungsinhalte für alle verfügbar sind, unabhängig von Sprache oder Lesefähigkeit.
KI-Audio in virtueller Realität und erweiterter Realität
Virtuelle Realität (VR) und erweiterte Realität (AR) drehen sich um immersive Erlebnisse. Bis vor kurzem lag der Fokus auf dem visuellen Aspekt, aber KI-Audio bietet die fehlende Zutat, um eine multisensorische, authentische virtuelle Welt zu schaffen.
Erhöhte Interaktivität
In VR und AR ist die Fähigkeit, mit Ihrer digitalen Umgebung zu interagieren, entscheidend. KI-Audio fügt eine neue Ebene der Interaktivität hinzu, die es Benutzern ermöglicht, natürlich mit KI-Charakteren zu sprechen. Da die NPCs KI sind, können Benutzer freie Gespräche führen und erhalten kontextbezogene Echtzeitantworten. Egal, ob Sie eine historische Simulation erkunden, Rätsel lösen oder an sozialen Interaktionen teilnehmen, KI-Audio bereichert das Erlebnis.
Eine digitale Persona aufrechterhalten
In einigen dieser immersiven Umgebungen ist die Aufrechterhaltung einer digitalen Persona Teil des Reizes. Ein KI-Charakterstimmengenerator stellt sicher, dass die Stimme Ihres Avatars nicht nur realistisch ist, sondern auch in der Lage ist, Emotionen und Nuancen zu vermitteln. Dadurch wird virtuelle Realität mehr als nur ein visuelles Erlebnis; es wird zu einer Möglichkeit, sich mit Klang und Emotionen auszudrücken.
KI-Audio geht über Unterhaltung hinaus
Bildschirmleser spielen eine transformative Rolle bei der Verbesserung der Zugänglichkeit für diejenigen, die sie am meisten benötigen. Einen Schritt weiter gehen generative KI-Stimmen, die VR- und AR-Erlebnisse auf neue Höhen heben. Die Synergie zwischen KI und Audio öffnet die Tür zu neuen Möglichkeiten und Inklusivität.
Das Ergebnis? Digitale Inhalte und immersive Simulationen werden für alle zugänglicher und ansprechender.
Im nächsten Abschnitt erkunden wir die ethischen Überlegungen rund um KI-Sprachtechnologie und den verantwortungsvollen Einsatz dieser leistungsstarken Werkzeuge.
Ethische Überlegungen in der KI-Sprachtechnologie
Wir haben gesehen, wie leistungsstark generatives Audio ist, aber wie bei jedem fortschrittlichen Werkzeug erfordert es eine Diskussion über verantwortungsvollen Einsatz. Da KI-Sprachtechnologie riesige Datensätze umfasst, gibt es offensichtliche Bedenken hinsichtlich Datenschutz und Privatsphäre. Es gibt jedoch einige einzigartige Probleme, die für ethische KI-Sprachtechnologie berücksichtigt werden müssen.
Voice Cloning ohne Zustimmung
Meme-Videos, die von realistischen Spongebob- und Joe Rogan-KI-Text-to-Speech-Generatoren angetrieben werden, mögen harmlos und lustig erscheinen, aber es gibt eine dunklere Seite dieses Trends. Da das Klonen von Prominentenstimmen immer beliebter wird, werden wir sehen, dass mehr Menschen die Technologie für betrügerische Zwecke nutzen.
Die Fähigkeit, eine überzeugende Replik einer Stimme zu erstellen, wirft offensichtliche Bedenken auf. Es ist leicht vorstellbar, wie ein Deepfake-Voice-Clone von Donald Trump verwendet werden könnte, um eine Desinformationskampagne zu führen. In kleinerem Maßstab gab es einen Anstieg von Betrügern, die KI-Stimmenreplikatoren verwenden, und es gibt auch Sicherheitsprobleme bei der Stimmerkennung.
Ist ethisches Voice Cloning möglich?
„Die Sicherstellung des ethischen Einsatzes von KI ist von größter Bedeutung. Wir arbeiten gemeinsam daran, Branchenstandards zu etablieren und den verantwortungsvollen Einsatz von KI-Audiotechnologie zu fördern.“ – Jan Czarnocki, Legal Counsel, ElevenLabs
Solange die richtigen Schritte unternommen werden, denken wir, dass es möglich ist. Unsere Nutzungsbedingungen erlauben Voice Cloning nur, wenn Sie die Zustimmung der Person haben. Für zusätzliche Transparenz haben wir einen KI-Sprachklassifikator entwickelt, der in der Lage ist, von ElevenLabs generierte Audioclips zu identifizieren.
Es ist erwähnenswert, dass unsere KI-Audiotools mehrere unserer 'Konkurrenten' unterstützen, sodass der KI-Sprachklassifikator Voice Clones von vielen der führenden generativen Audiounternehmen erkennen kann.
Gesetzgebung und Regulierung
Die Automatisierung von sprachbezogenen Aufgaben wird zunehmend menschliche Arbeitsplätze in Bereichen wie Animationsfilmen, Kundenservice und Inhaltserstellung ersetzen. Regulierungsbehörden müssen über die potenziellen Auswirkungen auf Arbeitnehmer nachdenken und wie sie einen fairen Übergang für die Betroffenen unterstützen können.
Darüber hinaus muss ein rechtlicher Rahmen für KI-Sprachtechnologie geschaffen werden, um Missbrauch zu verhindern, Benutzerrechte zu schützen und verantwortungsvolle Entwicklung zu fördern. Zum Beispiel gibt es Diskussionen darüber, welche Parteien für unethische Nutzung oder Konsequenzen aus KI-generiertem Audio verantwortlich gemacht werden sollten. Zu diesem Zweck arbeiten wir mit Partnern wie Loccus zusammen, um Branchenstandards für faire und ethische KI-Sprachtechnologie zu schaffen.
Die verantwortungsvolle Entwicklung und Anwendung dieser leistungsstarken KI-Audiotools ist entscheidend, um Risiken zu minimieren und die Vorteile zu maximieren. Wenn wir in die Zukunft blicken, ist es wichtig, Diskussionen zu führen und Richtlinien zu entwickeln, die den ethischen Einsatz von KI-Sprachtechnologie fördern.
Die Zukunft des generativen KI-Audios
Sie haben ein Verständnis für die aktuelle Landschaft der KI-Audiotechnologie gewonnen, und es ist klar, dass wir am Rande einer Revolution stehen; KI-gesteuertes Audio, realistisches KI-Text-to-Speech, generative Stimmen, Voice Cloning und mehr verändern dramatisch die Art und Weise, wie wir mit Klang interagieren.
Aber was kommt als Nächstes für diese transformative Technologie?
„Wir stehen an der Spitze der KI-Audio-Innovation, und die Integration von KI-Audio in den Alltag ist keine ferne Zukunft, sondern eine bevorstehende Realität.“ – Mati Staniszewski, CEO, ElevenLabs
KI-Audio im Alltag
Die Integration von KI-Audio in unser tägliches Leben ist unvermeidlich. Statista schätzt, dass bis 2024 weltweit 8,4 Milliarden digitale Sprachassistenten genutzt werden – das ist das Doppelte der 4,2 Milliarden im Jahr 2020.
KI-verbesserte Live-Sprachverbesserung (auch KI-Sprachmodulation genannt) während Anrufen wird die Kommunikationsqualität erhöhen. Callcenter und Echtzeit-Kommunikationsplattformen werden in der Lage sein, die Sprachklarheit zu verbessern, Hintergrundgeräusche zu unterdrücken und Benutzern sogar zu helfen, sich effektiver auszudrücken.
Marktforschung und Kundenfeedback-Analyse werden mit KI-gesteuerter Sentimentanalyse von Sprachdaten revolutioniert. Durch die automatische Bewertung des emotionalen Tons und Kontexts gesprochener Gespräche können Unternehmen tiefere Einblicke in die Kundenzufriedenheit gewinnen und ihre Produkte und Dienstleistungen entsprechend verfeinern. In Kombination mit KI-Sprachkundendiensttools können diese Daten den besten Tonfall und die beste Kadenz bestimmen, um einen verärgerten Kunden zu beruhigen.
Vielleicht weiter in der Zukunft werden wir einen Marketingansatz sehen, der Ihre Sprachpräferenzen berücksichtigt. Würde eine tiefe männliche Stimme oder eine sprudelnde weibliche Stimme Sie eher zum Kauf bewegen? Die Marketingwelt wird KI-Audio schnell in die Variablen integrieren, die sie A/B testen.
Dieser personalisierte Ansatz für Audio wird wahrscheinlich vom Marketing auf alle Inhalte, die Sie konsumieren, übergehen. Ihre Sprachpräferenzen werden notiert und verwendet, um das optimale Audioerlebnis in verschiedenen Branchen zu liefern, von Gesundheitswesen bis Unterhaltung.
KI-Audio-Trends werden fortgesetzt
Inklusive Technologien:
KI-Audio macht digitale Inhalte bereits für Menschen mit Behinderungen zugänglich. Dieser Trend wird sich mit der Entwicklung weiterer KI-Tools und Lösungen, die Barrierefreiheit und Vielfalt priorisieren, beschleunigen.
KI-Voice Cloning und Sicherheit:
Derzeit können wir Stimmen erstellen, die für menschliche Ohren praktisch nicht zu unterscheiden sind. Mit dem Fortschritt der Technologie zu perfekten Replikaten der menschlichen Stimme wird es zunehmend schwierig für Computer, Deepfake-Voice-Clones und betrügerische Stimmnutzung zu erkennen. Der anhaltende Kampf zwischen denen, die KI-Voice-Cloning-Technologie entwickeln, und denen, die sie missbrauchen wollen, wird Fortschritte in Sicherheitsmaßnahmen erfordern.
Bildungs- und Karrieremöglichkeiten:
KI-Audio wird neue Bildungs- und Karrieremöglichkeiten bieten. Personen, die das Potenzial von KI-gesteuertem Audio verstehen und nutzen, werden in verschiedenen Bereichen gefragt sein: von Inhaltserstellung und Sprachschauspiel bis hin zu KI-Entwicklung und Cybersicherheit.
Die Zukunft von KI-Audio ist vielversprechend und komplex
Die oben genannten sind nur einige Beispiele für Entwicklungen, die wir erwarten können. KI-Audiotechnologie ist noch jung, und es wird sicherlich neuartige Anwendungen geben, die wir noch nicht in Betracht gezogen haben. Statista erwartet, dass die Größe des KI-Marktes zwischen 2023 und 2030 um 788 % steigen wird.
Die KI-Audioindustrie birgt ein enormes Potenzial, die Art und Weise, wie wir kommunizieren, Inhalte konsumieren und mit der Welt um uns herum interagieren, neu zu gestalten.
Im nächsten Abschnitt erklären wir, wie Sie eine KI-Stimme erstellen können, und diskutieren die Vor- und Nachteile der besten KI-Stimmengeneratoren online.
ElevenLabs vs. Wettbewerber
Wenn es um KI-Audio geht, ist die Branche voller Tools und Plattformen, die alle versuchen, ihre Nische zu finden. ElevenLabs hebt sich jedoch von der Konkurrenz ab, indem es eine einzigartige Mischung aus Funktionen und Fähigkeiten bietet, die unsere KI-Audiolösungen auszeichnen. Lassen Sie uns erkunden, wie sich unsere Angebote im Vergleich zu einigen wichtigen Wettbewerbern auf dem Markt behaupten.
ElevenLabs vs. Speechify, Narakeet, Murf.ai und Natural Readers
Viele beliebte KI-Audio-Plattformen wie Speechify, Narakeet, Murf.ai und Natural Readers haben Schwierigkeiten mit der Qualität ihrer generierten Stimmen. Benutzer stoßen oft auf Probleme bei der Lieferung, Kadenz oder dem Ton, die die Immersion stören und die synthetische Natur der Stimme offenbaren.
Hier bei ElevenLabs verfolgen wir einen anderen Ansatz. Hochwertige Stimmen, die nicht von einer echten menschlichen Stimme zu unterscheiden sind, sind unser Standard – wir erstellen Stimmen, die so realistisch sind, dass Sie nicht merken, dass sie KI-generiert sind.
ElevenLabs vs. Lovo.ai und Play.ht
Lovo.ai und Play.ht bieten gute Stimmenqualität, aber Benutzer könnten es schwierig finden, die perfekte Stimme für ihre spezifischen Bedürfnisse auszuwählen.
Hier übernimmt ElevenLabs die Führung. Wir bieten eine vielfältige Auswahl von 120 vorgefertigten Stimmen, sodass Sie eine breite Auswahl haben. Aber wir gehen noch einen Schritt weiter, da wir Ihnen auch ermöglichen, vollständig benutzerdefinierte Stimmen zu generieren. Mit ElevenLabs müssen Sie nicht Hunderte von Stimmproben durchsuchen, um die richtige zu finden.
Stattdessen müssen Sie nur das Geschlecht, das Alter, den Akzent und die Stärke des Akzents angeben, den Sie wünschen – wir erstellen eine 100% einzigartige Stimme, die auf Ihre Vorlieben zugeschnitten ist. Nicht ganz das, was Sie suchen? Kein Problem, Sie können einfach neu generieren, um eine brandneue Stimme zu erhalten, die perfekt zu Ihren Audioanforderungen passt.
Vergleich von KI-Audiotools
Im wettbewerbsintensiven Umfeld des KI-Audios sticht ElevenLabs als die bevorzugte Wahl hervor.
Wie Sie gesehen haben, legen wir Wert auf hochwertige und lebensechte Stimmen, aber wir machen KI-Audio auch einfach. Unser Ziel ist es, die Technologie in eine Vielzahl von Branchen zu bringen und einen reibungslosen, benutzerfreundlichen und anpassbaren Arbeitsablauf für jeden Anwendungsfall zu schaffen.
Wir bieten bereits einen realistischen Text-to-Speech-freien KI-Stimmengenerator, Voice Cloning-Software, ein langes KI-TTS-Tool, ein automatisches KI-Dubbing-Tool, eine leistungsstarke API und vieles mehr, das bald kommt.
Unser Engagement, unvergleichliche Audiolösungen bereitzustellen, hebt uns weiterhin ab und stellt sicher, dass ElevenLabs-Benutzer das Beste aus beiden Welten genießen – Qualität und Komfort.
Bereit, das Beste zu erleben, was KI-Audio zu bieten hat?
Erstellen Sie menschenähnliche Stimmen mit unserem Text to Speech (TTS) System, entwickelt für hochwertige Erzählungen, Gaming, Video und Barrierefreiheit. Ausdrucksstarke Stimmen, mehrsprachige Unterstützung und API-Integration erleichtern die Skalierung von persönlichen Projekten bis hin zu Unternehmensabläufen.
Einzigartige Wege, wie Kunden KI-Audio nutzen
In diesem Abschnitt werden wir einige einzigartige KI-Audio-Anwendungsfälle betrachten, die von der Technologie von ElevenLabs unterstützt werden. Mit einem Fokus auf reale Funktionalität werden wir sowohl kleine persönliche Anwendungen als auch große, branchenverändernde Projekte betrachten, die die Vielseitigkeit und Stärken unserer Tools hervorheben.
Wiederverbindung durch Voice Cloning
Im ElevenLabs Discord-Server haben wir mehrere Benutzer, die verstorbene Verwandte stimmlich klonen. Nun, wir wissen, dass dies nicht für jeden ist, aber einige Benutzer finden, dass dies hilft, mit Verlust umzugehen. Es ermöglicht Benutzern, Abschluss zu finden, schöne Erinnerungen wiederzuerleben (mit der Stimme, die wertvolle Briefe liest), oder Familien dabei zu helfen, gemeinsam in Erinnerungen zu schwelgen.
„Ich finde es verrückt, dass ein KI-Modell 'schöne' Dinge schaffen kann. Ich habe die Stimme einer verstorbenen Person, die ich kenne, sofort geklont, und jetzt kann ich ihn wiederbeleben, wenn ich ihn brauche.“ – Adam, Discord-Mitglied
Wir hatten auch Menschen, die die Stimme eines verstorbenen Familienmitglieds klonten und sie verwendeten, um das Buch zu erzählen, das sie vor ihrem Tod veröffentlicht hatten. Können Sie sich vorstellen, wie sich der Benutzer fühlen wird, wenn er diese KI-Hörbucherzählung in der Stimme seines geliebten Menschen hört?
Verlorene und beschädigte Stimmen wiederherstellen
Weitere Beispiele für die emotionale Wirkung von KI-Audio sind verfügbar, wenn wir Benutzer betrachten, die nicht mehr so kommunizieren können wie früher. Diese Benutzerreaktionen bieten ein gutes Beispiel dafür, wie transformativ Voice Cloning sein kann: „Das ist mir suuuuuuper wichtig, da ich meine Stimme verloren habe. Wörtlich. Ich kann heute nur flüstern, nachdem ich intubiert wurde. Meine Stimmbänder sind etwa zur Hälfte geöffnet gelähmt.“ – Aaron, Discord-Mitglied
„Ich habe meine Stimme dauerhaft aufgrund von Kehlkopfkrebs verloren. Wäre es möglich, KI meine Stimme aus alten Videobändern, die ich herumliegen habe, zu trainieren? Ich kann es kaum erwarten, diese Technologie zu nutzen, um meine Stimme zurückzubekommen...“ – Vince, Discord-Mitglied
Hörbücher in Minuten erstellen
In einer professionellen Anwendung macht unser Studio-Tool es Benutzern leicht, hochwertige lange Audios in verschiedenen Sprachen zu erstellen. Die einzigartigen Herausforderungen, dies mit manuellen Sprachaufnahmen zu tun, sind offensichtlich: Umfang, Kosten und Geschwindigkeit. Wie viele Stunden würde es dauern, ein Buch in nur einer Sprache aufzunehmen und zu bearbeiten?
Ein bemerkenswertes Beispiel dafür, wie dies genutzt werden kann, ist unsere Fallstudie mit dem Verlag Lukeman Literary. Sie nutzten Studio, um schnell Hörbücher zu erstellen und die mehrsprachige Expansion zu unterstützen, indem sie in mehreren Sprachen veröffentlicht werden. Dies ermöglicht es ihnen, ein globales Publikum mit unterschiedlichen sprachlichen Vorlieben anzusprechen.
„Trotz der offensichtlichen Vorteile der digitalen Erzählung waren wir nicht bereit, die neue Technologie zu akzeptieren, bis ein Unternehmen mit einer Erzählung von bahnbrechender Qualität kam, die einer natürlichen menschlichen Stimme entsprechen konnte. In ElevenLabs' neuem Produkt haben wir diese Qualität gefunden.“ – Noah Lukeman, Präsident & Gründer von Lukeman Literary
Innovationen in KI-Audio und darüber hinaus
Diese einzigartigen Anwendungsfälle, Kundenreferenzen und Fallstudien zeigen die vielseitige Natur der KI-Audiotechnologie von ElevenLabs. Von Enterprise-KI-Audioprojekten, die sprachliche Barrieren überwinden, bis hin zu zutiefst persönlichen emotionalen Erlebnissen, unsere Lösungen setzen weiterhin die Grenzen dessen, was mit KI-Audio möglich ist.
Fazit
Wir haben eine detaillierte Reise durch die Welt des KI-Audios unternommen und die transformativen Technologien kennengelernt, die unsere Beziehung zum Klang neu gestalten. Von realistischem TTS und generativen Stimmen bis hin zu Voice Cloning und automatischem Audio-Dubbing ist das Potenzial für die Übernahme der KI-Industrie enorm.
Die aktuelle KI-Technologielandschaft hat bereits die Bedeutung von KI-Audio gezeigt – verbesserte Benutzererfahrungen, Kosteneinsparungen, verbesserte Zugänglichkeit und neue Möglichkeiten für Unternehmen.
Die Zukunft sieht jedoch noch spannender aus. Mit neuen Anwendungen für KI-Technologie, die fast täglich erscheinen, erwarten wir einen Boom bei der Übernahme in Branchen wie Gesundheitswesen, Banken, Bildung, Marketing und mehr – und vergessen Sie nicht all die Anwendungen für Barrierefreiheit.
Wie fängt man mit KI-Audio an?
Wenn Sie genauso begeistert sind wie wir über das Potenzial von allem, was KI-Audio betrifft, dann sind Sie hier genau richtig.
ElevenLabs steht als führender Anbieter in der KI-Audioindustrie und bietet hochmoderne Lösungen, die lebensechte Stimmen und benutzerzentrierte Anpassung priorisieren. Unser Engagement für Qualität und Komfort hält uns an der Spitze dieses sich schnell entwickelnden Feldes.
Ein guter Ausgangspunkt ist unsere Sprachsynthese Seite. Unser kostenloses Text-to-Speech-KI-Tool ermöglicht es Ihnen, die Technologie auszuprobieren und zu sehen, ob sie Ihren Bedürfnissen entspricht.
Denken Sie, dass generatives KI-Audio gut zu Ihrem Unternehmen passt?
Wir wissen, dass es schwierig ist, neue Technologien in Ihr Unternehmen zu integrieren. Wir würden es Ihnen gerne erleichtern. Kontaktieren Sie uns, und wir werden sehen, wie wir helfen können.
Häufig gestellte Fragen
Sie können ganz einfach eine KI-Stimme erstellen, indem Sie Online-KI-Stimmengeneratoren wie ElevenLabs verwenden, die verschiedene Text-to-Speech-Stimmen kostenlos anbieten.
KI hat bedeutende Fortschritte bei der Erstellung lebensechter TTS (Text-to-Speech)-Stimmen mit Emotionen und Akzenten gemacht. Die realistischsten KI-Stimmen von ElevenLabs sind von menschlicher Sprache nicht zu unterscheiden.
Die beste Text-to-Speech-KI variiert je nach Ihren Bedürfnissen, aber es gibt viele ausgezeichnete Optionen zur Generierung lebensechter Stimmen. ElevenLabs kombiniert hochwertige Stimmen und Benutzerfreundlichkeit und ist damit eine der beliebtesten Optionen.
Ja, ElevenLabs bietet kostenlose KI-Text-to-Speech-Software online an, mit der Sie hochwertige Stimmen generieren können.
Sie können KI-Stimmengeneratoren wie ElevenLabs verwenden, um KI-generierte Stimmen für Voiceovers und Erzählungen in Ihren TikTok- und YouTube-Videos zu erstellen.
ElevenLabs unterstützt 29 Sprachen, darunter Arabisch, Chinesisch und Indisch Text-to-Speech.
ElevenLabs bietet eine Reihe realistischer Text-to-Speech-Stimmen, die über eine benutzerfreundliche API zugänglich sind.
ChatGPT von OpenAI hat viele reale Anwendungen wie Chatbots, Inhaltserstellung, Sprachübersetzung und mehr.
Sprachsynthesetechnologie von ElevenLabs macht es einfach, Ihren Chatbot zum Leben zu erwecken.
ChatGPT ist ein KI-Modell, das von OpenAI entwickelt wurde und natürliche Sprache versteht und generiert. Es ist ein beliebtes Beispiel für generative KI-Modelle, bei denen maschinelles Lernen verwendet wird, um menschenähnlichen Text basierend auf Texteingaben zu generieren.
Stable Diffusion, DALL-E 2 und Midjourney sind die beliebtesten KI-Bildgeneratoren. Für alles rund um Audio empfehlen wir ElevenLabs.
Beginnen Sie mit der Erkundung von Ressourcen zu Transformator-Modellen, Diffusionsmodellen und dem Konzept von Encodern und Decodern. Dies sind die grundlegenden Bausteine, die die jüngsten Durchbrüche antreiben.
This Veterans Day, we honor Lt Col Thomas Brittingham, a pilot, father, and veteran living with ALS, who regained his voice through the ElevenLabs Impact Program, one story among many showing how veterans are finding their voices again through technology.