Customer stories

DeepBrain AI integrates ElevenLabs to scale voice-powered avatars and multilingual video
AI-generated videos created with avatars & dubbed voice have grown 7x
Vi distribuerar vår egen generativa modell som låter användare designa helt nya syntetiska röster
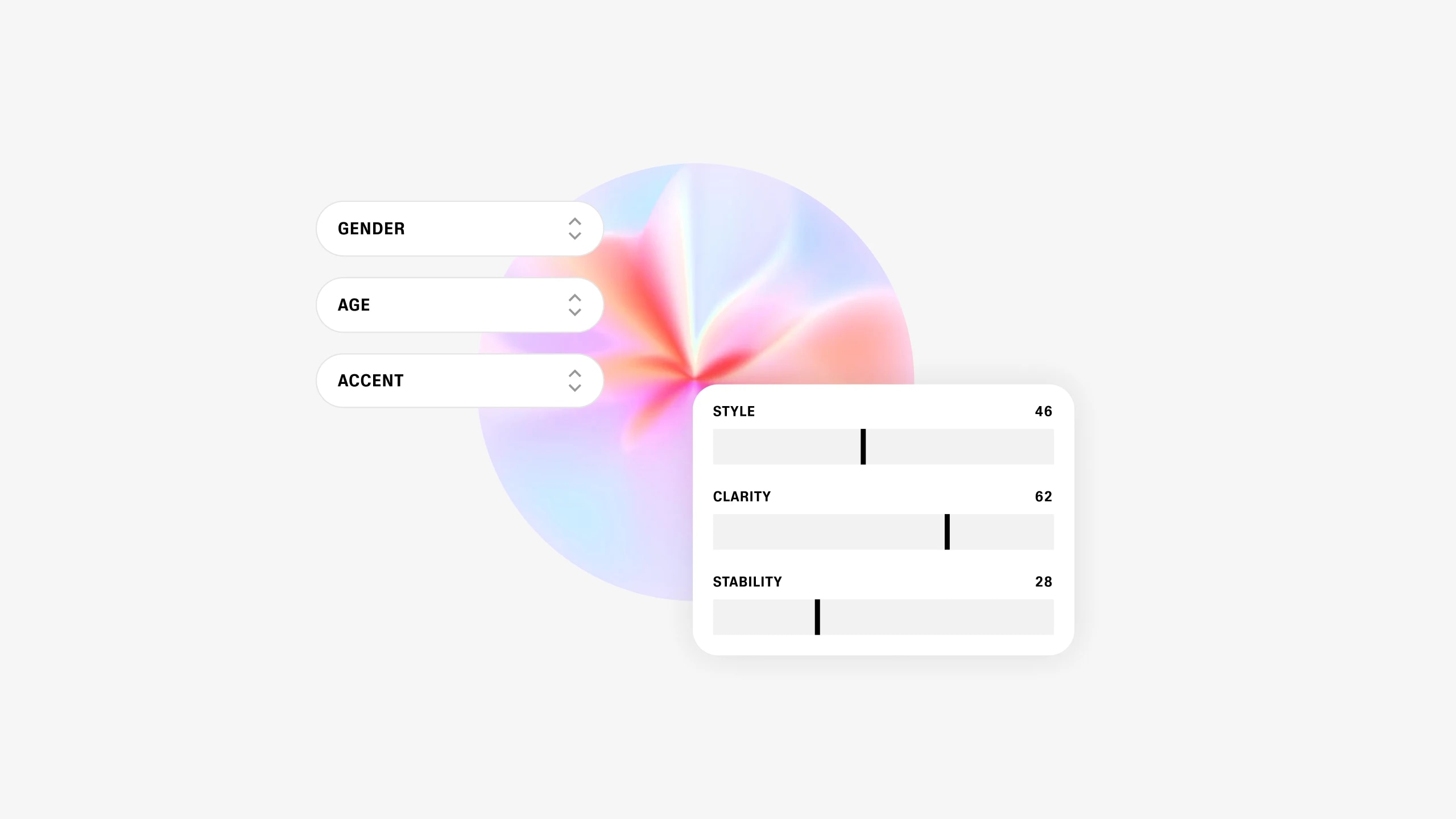
Nyligen verkar det som att alla pratar om generativ AI. Djup inlärningsdrivna stora språk- och text-till-bild-modeller som ChatGPT, Stable Diffusion, DALL-E och Midjourney har orsakat mycket uppståndelse i teknikvärlden och utanför. Många inkluderar dem bland de viktigaste senaste utvecklingarna inom AI. Oavsett om du håller med eller inte, verkar den allmänna känslan vara att något mycket allsmäktigt har dykt upp. Under 2023 kommer vi att höra om modeller som kan hjälpa dig att rita eller skapa videor. Ungefär som frågor om vad som är den senaste bästa smarttelefonen, kommer vi snart att fråga om vad som är den senaste och bästa grundmodellen. Men trots all denna spänning känner vi att det finns ett område inom generativ media som fortfarande är kraftigt underhypad: röst AI. Det är också det område vi vill bli ledande inom. På Eleven litar vi på potentialen som frigörs av tekniker för djupinlärning varje dag för att driva vår verklighetstrogna text till tal , och AI-röstkloning verktyg. Och nu distribuerar vi också vår egen generativa modell som låter dig designa helt nya syntetiska röster från grunden.
Våra användare tar till plattformen dagligen för att väcka sina karaktärer levande - oavsett om det är för ljudböcker, spel eller fanfiction. Vi insåg att vår nuvarande högtalarbank är för liten för att alla ska kunna hitta de röster som matchar deras innehållsbehov samtidigt som de förblir exklusiva för varje användare. Vår lösning var att låta dig designa helt nya syntetiska röster.
Vi hade en idé om hur vi skulle gå till väga när vi packade upp de metoder vi för närvarande använder för talsyntes och röstkloning. Båda processerna kräver ett sätt att koda egenskaperna hos en viss röst. Högtalarinbäddningar är vad som bär denna identitet - de är en vektorrepresentation av en talares röst. Vi insåg att vi kunde ta prov från distributionen av högtalarinbäddningar genom att träna en dedikerad modell för att låta oss skapa oändligt många nya röster.
Eftersom våra användare mestadels letar efter specifika talegenskaper, behövde vi lägga till en viss grad av kontroll över processen. Vi utökade vår modell med konditionering för att generera röster baserat på deras egenskaper. Modellen låter dig nu ställa in vissa grundläggande parametrar som fastställer den nya röstens kärnidentitet: kön, ålder, accent, tonhöjd och talstil. Med andra ord, varje gång du trycker på "generera", även om du väljer samma basparametrar, du får en helt ny röst som inte fanns förut.
Nedan följer några exempel på röster som kan utformas på detta sätt:
'Design Voice' kommer att bli tillgänglig på vår plattform i februari, som en del av Voice Lab.
Våra verktyg kan redan producera tal som är lika verklighetstrogna som alla människors och vi förväntar oss att sfären för potentiella tillämpningar för konstgjorda röster bara kommer att expandera. Många av dessa nya applikationer, inklusive inspelning av ljud för nyhetspublikationer eller reklamfilmer, kommer att kräva att en röst begränsas till, och identifieras med, ett visst varumärke eller användningsfall och inte används någon annanstans. Andra användningsfall, som storytelling och videospel, prioriterar flexibilitet och friheten att experimentera från tidigt i utvecklingen. Så i stället för att skapa en gigantisk uppsättning virtuella högtalare, satte vi oss för att låta användarna ha sista ordet om vilka röster som bäst passar deras syften.
Boka Författare får nu inte bara möjligheten att enkelt konvertera sitt verk till ljud utan de behåller också den konstnärliga kontrollen över att utforma skräddarsydda berättarröst. Detta ger publiken intressanta nya sätt att interagera med publikationer, och det ökar avsevärt antalet böcker vi kommer att kunna njuta av att lyssna på.
Nyheter förlag har i allt högre grad vågat sig på ljud och att välja distinkta röster för att representera sina publikationer är en viktig uppgift - många lyssnare värdesätter såväl form som substans. Lika viktigt är att publicister nu kan vara säkra på att en viss röst representerar dem, och dem ensamma.
Videospel Utvecklare kan nu uttrycka en uppsjö av annars tysta NPC:er med alla nödvändiga verktyg tillgängliga till hands. De kan inte bara vara mer kostnadseffektiva utan att kompromissa med kvaliteten utan de kan nu också designa röster som kommer att vara helt unika för de virtuella världar de skapar.
Reklam Creatives behöver voiceovers för att passa särskilda kampanjer, så att kunna designa resonansfulla och specialbyggda berättarröst i början av utvecklingen är en avsevärd fördel. De kan nu experimentera med flera röster och leveransstilar direkt och utan att använda ytterligare resurser.
Från Kreatörer producerar alla typer av ljud- och videoinnehåll till företags- tjänstemän som vill tala om företagskommunikation, möjligheterna att designa övertygande ljud som är både unikt och skräddarsytt för ett specifikt användningsfall är nu oändliga.
På samma sätt som röstkloning väcker farhågor om konsekvenserna av dess potentiella missbruk, oroar allt fler människor att spridningen av AI-teknik kommer att äventyra proffs försörjning. På Eleven ser vi en framtid där röstskådespelare kan licensiera sina röster för att träna talmodeller för specifik användning, i utbyte mot avgifter. Kunder och studior kommer fortfarande gärna att ha professionell rösttalang i sina projekt och att använda AI kommer helt enkelt att bidra till snabbare handläggningstider och större frihet att experimentera och skapa riktning i tidig utveckling. Tekniken kommer att förändra hur talat ljud utformas och spelas in, men det faktum att röstskådespelare inte längre behöver vara fysiskt närvarande under varje session ger dem verkligen friheten att vara involverade i fler projekt vid en tidpunkt, samt att verkligen föreviga deras röster.
Utöver detta är anledningen till att vi är glada att en mängd böcker, nyheter, oberoende spel och annat innehåll vars författare och utvecklare annars inte skulle ha råd med inspelningskostnader nu kommer att bli tillgängliga via ett annat medium. Med denna ökade tillgång kommer möjligheten att bredda publiken i varje enskilt fall.
På Eleven är vi fullt engagerade både i att respektera immateriella rättigheter och att implementera skydd mot potentiellt missbruk av vår teknik:
I framtiden planerar vi att kombinera funktionerna hos våra röstgenererande och röstkloningsmodeller för att tillåta användare att förbättra sina egna röster. Du kommer att kunna klona din röst och sedan manipulera den till önskad effekt. Om du är rädd att din naturliga talstil är lite monoton, kommer du att kunna lägga till variation till den. Om du verkligen ogillar att bli inspelad kommer du att kunna manipulera utmatningen så att den låter mer naturlig. Varje person som behöver producera ljud med sin egen röst för något syfte, vare sig det är en förinspelad presentation eller ett ljudmeddelande, kommer att kunna göra det med hjälp av vår uppsättning verktyg, med ett klick på en knapp.
När 2022 närmade sig sitt slut vill vi tacka våra beta-användare för ditt fortsatta deltagande och för din feedback. Många av funktionerna vi utvecklar beror på din input och dina förslag. Vi kunde inte vara gladare över att ha dig ombord och vi önskar er alla ett Gott Nytt År.
Eleven Labs Beta
Gå här att registrera dig för vår betaplattform och prova det själv. Vi gör ständigt förbättringar och all användarinsikt är mycket värdefull för oss i detta tidiga skede.
AI-generated videos created with avatars & dubbed voice have grown 7x

The Dutch DJ, producer, and founder uses ElevenLabs to create voice content anywhere - backstage, in transit, or between shows
Drivs av ElevenLabs Conversational AI