Cosa sono gli Audio Tag Eleven v3 — e perché sono importanti
- Scritto da
- Ryan Morrison
- Pubblicato
- Ultimo aggiornamento
AscoltaAscolta questo articolo
Con il rilascio di Eleven v3, il prompting audio è appena diventato una competenza fondamentale. Ora, invece di scrivere o incollare semplicemente le parole che vuoi far dire alla voce IA, puoi usare una nuova funzione — Audio Tag — per controllare tutto, dall’emozione alla resa.
Eleven v3 è una versione alpha anteprima di ricerca del nuovo modello. Richiede più prompt engineering rispetto ai modelli precedenti — ma i risultati sono sorprendenti.
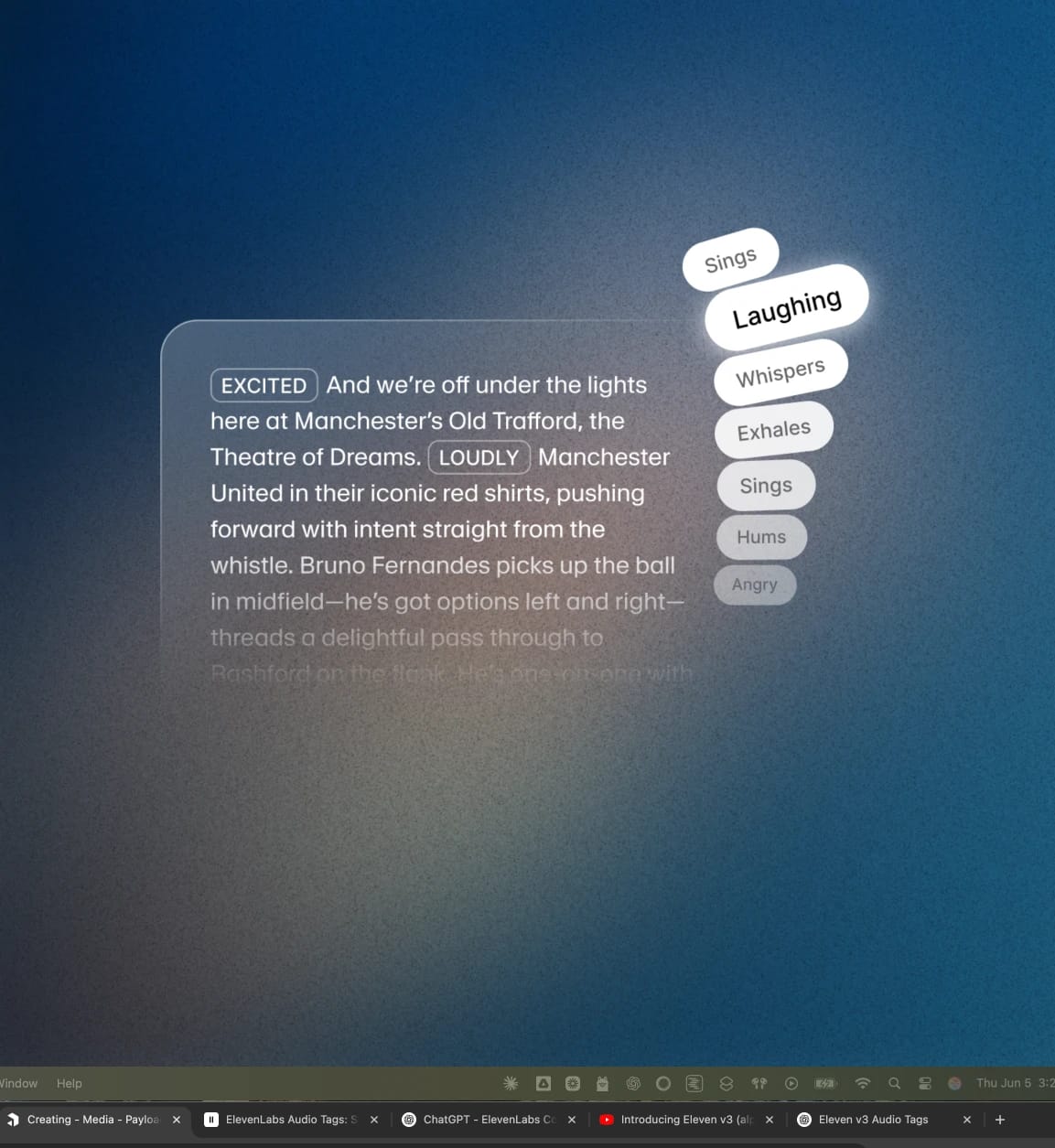
Gli Audio Tag di ElevenLabs sono parole racchiuse tra parentesi quadre che il nuovo modello Eleven v3 può interpretare e usare per guidare l’azione sonora. Possono essere qualsiasi cosa: da [excited], [whispers] e [sighs] fino a [gunshot], [clapping] e [explosion].
I Tag Audio ti permettono di modellare il suono delle voci IA, inclusi segnali non verbali come tono, pause e ritmo. Che tu stia creando
Dirigere la performance con gli Audio Tag
Puoi inserire gli Audio Tag ovunque nel tuo script per modellare la resa in tempo reale. Puoi anche combinare più tag nello stesso script o addirittura nella stessa frase. I tag si dividono in categorie principali:
Emozioni
Questi tag ti aiutano a impostare il tono emotivo della voce — che sia cupo, intenso o allegro. Ad esempio puoi usare uno o più tra [sad], [angry], [happily] e [sorrowful].


Indicazioni di resa
Questi riguardano più il tono e la performance. Puoi usare questi tag per regolare volume ed energia in scene che richiedono delicatezza o forza. Esempi: [whispers], [shouts] e anche [x accent].


Reazioni umane
Il parlato naturale include reazioni. Puoi usarle per aggiungere realismo inserendo momenti spontanei nel discorso. Ad esempio: [laughs], [clears throat] e [sighs].


Basato su un modello più espressivo
Alla base di queste funzionalità c’è la nuova architettura di v3. Il modello comprende il contesto del testo in modo più profondo, quindi riesce a seguire meglio segnali emotivi, cambi di tono e passaggi tra speaker. Insieme agli Audio Tag, questo permette una maggiore espressività rispetto a quanto fosse possibile prima in
Ora puoi anche creare dialoghi multi-personaggio che sembrano spontanei — gestendo interruzioni, cambi di umore e sfumature conversazionali con pochissimo prompting.
Disponibile ora
Le Clonazioni Vocali Professionali (PVC) al momento non sono completamente ottimizzate per Eleven v3, quindi la qualità della clonazione potrebbe essere inferiore rispetto ai modelli precedenti. In questa fase di anteprima di ricerca, ti consigliamo di trovare una
Eleven v3 è disponibile nell’interfaccia ElevenLabs e offriamo l’80% di sconto fino alla fine di giugno. La Public API per Eleven v3 (alpha) è anche disponibile. Che tu stia sperimentando o lavorando su larga scala, ora è il momento di scoprire cosa puoi fare.
Come creare gli Audio Tag

Creare parlato IA che interpreta — e non si limita a leggere — dipende dalla padronanza degli Audio Tag. Abbiamo preparato sette guide pratiche e concise che mostrano come tag come [SUSSURRA], [RIDE PIANO], oppure [accento francese] ti permettono di modellare contesto, emozione, ritmo e persino dialoghi multi-personaggio con un solo modello.
Scopri la serie
- Consapevolezza della situazione – Tag come
[SUSSURRA],[URLO], e[SOSPIRO]permettono a Eleven v3 di reagire al momento — aumentando la tensione, smorzando avvertimenti o creando suspense con una pausa. - Performance del personaggio – Da
[voce da pirata]a[accento francese], i tag trasformano la narrazione in interpretazione. Cambia personaggio a metà frase e dirigi performance complete senza cambiare modello. - Contesto emotivo – Segnali come
[sospiro],[entusiasta], oppure[stanco]guidano le emozioni momento per momento, aggiungendo tensione, sollievo o umorismo — senza bisogno di nuove registrazioni. - Intelligenza narrativa – Raccontare storie è questione di tempi. Tag come
[pausa],[meraviglia], oppure[tono drammatico]controlla ritmo ed enfasi così - Dialogo multi-personaggio – Scrivi battute sovrapposte e scambi rapidi con
[interrompe],[si sovrappone], o cambi di tono. Un solo modello, tante voci — conversazioni naturali in un’unica sessione. - Controllo della resa – Regola ritmo ed enfasi nei dettagli. Tag come
[pausa],[frettoloso], oppure[prolungato]ti danno precisione sul tempo, trasformando il testo in interpretazione. - Emulazione di accenti – Cambia regione al volo —
[accento americano],[accento britannico],[accento sud degli Stati Uniti]e altri ancora — per un parlato ricco di sfumature culturali senza cambiare modello.
.webp&w=3840&q=80)
.webp&w=3840&q=80)
