Come abbiamo reso RAG il 50% più veloce
- Scritto da
- Michal Korbela
- Pubblicato
- Ultimo aggiornamento
AscoltaAscolta questo articolo
RAG migliora la precisione degli agenti IA collegando le risposte degli LLM a grandi knowledge base. Invece di inviare tutta la knowledge base all’LLM, RAG crea un embedding della query, recupera le informazioni più rilevanti e le passa come contesto al modello. Nel nostro sistema, aggiungiamo prima una fase di riscrittura della query, condensando la cronologia del dialogo in una domanda precisa e autonoma prima del recupero.
Per knowledge base molto piccole, può essere più semplice inserire tutto direttamente nel prompt. Ma quando la knowledge base cresce, RAG diventa essenziale per mantenere le risposte accurate senza sovraccaricare il modello.
Molti sistemi trattano RAG come uno strumento esterno, ma noi lo abbiamo integrato direttamente nella pipeline delle richieste così da eseguirlo su ogni query. Questo garantisce precisione costante, ma introduce anche un rischio di latenza.
Perché la riscrittura delle query ci rallentava
La maggior parte delle richieste degli utenti fa riferimento a turni precedenti, quindi il sistema deve condensare la cronologia del dialogo in una domanda precisa e autonoma.
Ad esempio:
- Se l’utente chiede: “Possiamo personalizzare quei limiti in base ai nostri picchi di traffico?”
- Il sistema la riscrive così: “I limiti di rate API del piano Enterprise possono essere personalizzati per specifici pattern di traffico?”
La riscrittura trasforma riferimenti vaghi come “quei limiti” in domande autonome che i sistemi di retrieval possono usare, migliorando il contesto e la precisione della risposta finale. Ma affidarsi a un solo LLM esterno creava una forte dipendenza dalla sua velocità e disponibilità. Solo questo passaggio rappresentava oltre l’80% della latenza di RAG.
Come abbiamo risolto con il model racing
Abbiamo riprogettato la riscrittura delle query come una gara:
- Più modelli in parallelo. Ogni query viene inviata a più modelli contemporaneamente, inclusi i nostri Qwen 3-4B e 3-30B-A3B self-hosted. Vince la prima risposta valida.
- Fallback che mantengono fluida la conversazione. Se nessun modello risponde entro un secondo, usiamo il messaggio originale dell’utente. Può essere meno preciso, ma evita blocchi e garantisce continuità.
.webp&w=3840&q=95)
L’impatto sulle prestazioni
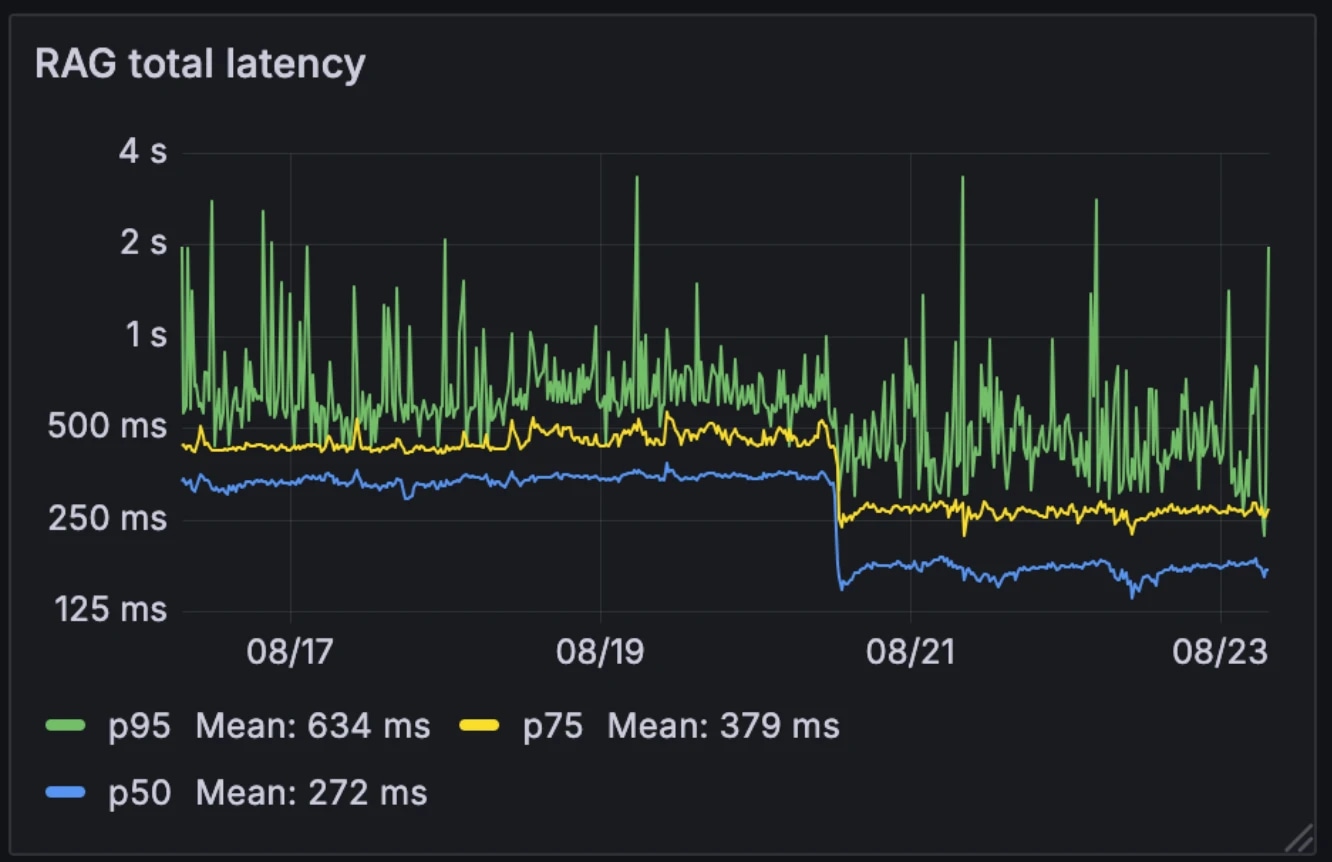
Questa nuova architettura ha dimezzato la latenza mediana di RAG, da 326ms a 155ms. A differenza di molti sistemi che attivano RAG solo in alcuni casi come strumento esterno, noi lo eseguiamo su ogni query. Con una latenza mediana di 155ms, il carico aggiuntivo è trascurabile.
Latenza prima e dopo:
- Mediana: 326ms → 155ms
- p75: 436ms → 250ms
- p95: 629ms → 426ms
L’architettura ha anche reso il sistema più resistente alle variazioni dei modelli. Mentre i modelli esterni possono rallentare nelle ore di punta, i nostri modelli interni restano abbastanza costanti. Il model racing riduce questa variabilità, trasformando le prestazioni imprevedibili dei singoli modelli in un comportamento di sistema più stabile.
Ad esempio, quando uno dei nostri provider LLM ha avuto un’interruzione il mese scorso, le conversazioni sono proseguite senza problemi sui nostri modelli self-hosted. Dato che già gestiamo questa infrastruttura per altri servizi, il costo computazionale aggiuntivo è trascurabile.
Perché è importante
Riscrivere le query RAG in meno di 200ms elimina un grande collo di bottiglia per gli agenti conversazionali. Il risultato è un sistema che resta sempre contestuale e in tempo reale, anche su knowledge base aziendali molto grandi. Con il carico del retrieval ridotto a livelli quasi trascurabili, gli agenti conversazionali possono scalare senza compromettere le prestazioni.



.webp&w=3840&q=80)
