
Tu flujo de trabajo completo para editar videos y audio, añadir locuciones y música, transcribir a texto y publicar producciones narradas y subtituladas
Con Text to Speech, las historias pueden escucharse inmediatamente al publicarse, en una variedad de voces y estilos de entonación


Text to Speech La tecnología (TTS), en su esencia, transforma contenido escrito en discurso audible. En los últimos años, con avances significativos en aprendizaje automático, TTS ha evolucionado hasta un punto donde la voz sintetizada es prácticamente indistinguible de la narración humana. El realismo y la expresividad logrados por los modernos TTS ofrecen un potencial inigualable, especialmente para la industria editorial.
Para los editores de noticias, el paisaje sonoro no es solo un campo emergente sino un requisito para la interacción. Desarrollar una presencia de audio ha demostrado mejorar la retención y satisfacción del usuario. Mientras que la ruta tradicional implicaría contratar actores de doblaje o hacer que los reporteros narren, estos métodos no son ni eficientes en tiempo ni en costo. Con Text to Speech, las historias pueden vocalizarse inmediatamente al publicarse, asegurando que el contenido se mantenga fresco, relevante y de alta calidad.
Cómo logramos una entonación humana incluso en textos muy largos se debe a la forma en que hemos construido nuestro modelo. Está entrenado para entender qué se está diciendo y ajustar la entonación en consecuencia. Lo hace teniendo en cuenta no solo el significado de las palabras sino también el contexto que rodea cada enunciado.
Los algoritmos tradicionales de generación de voz producen enunciados de manera individual. Esto es menos exigente computacionalmente pero inmediatamente suena robótico. Las emociones y la entonación a menudo necesitan extenderse y resonar a lo largo de varias oraciones para unir un determinado hilo de pensamiento. El tono y el ritmo transmiten intención, que es realmente lo que hace que la voz suene humana en primer lugar. Así que en lugar de generar cada enunciado por separado, nuestro modelo tiene en cuenta el contexto circundante, manteniendo un flujo y prosodia adecuados en todo el material generado. Esta profundidad emocional, junto con una calidad de audio superior, proporciona a los usuarios la herramienta de narración más genuina y atractiva disponible.
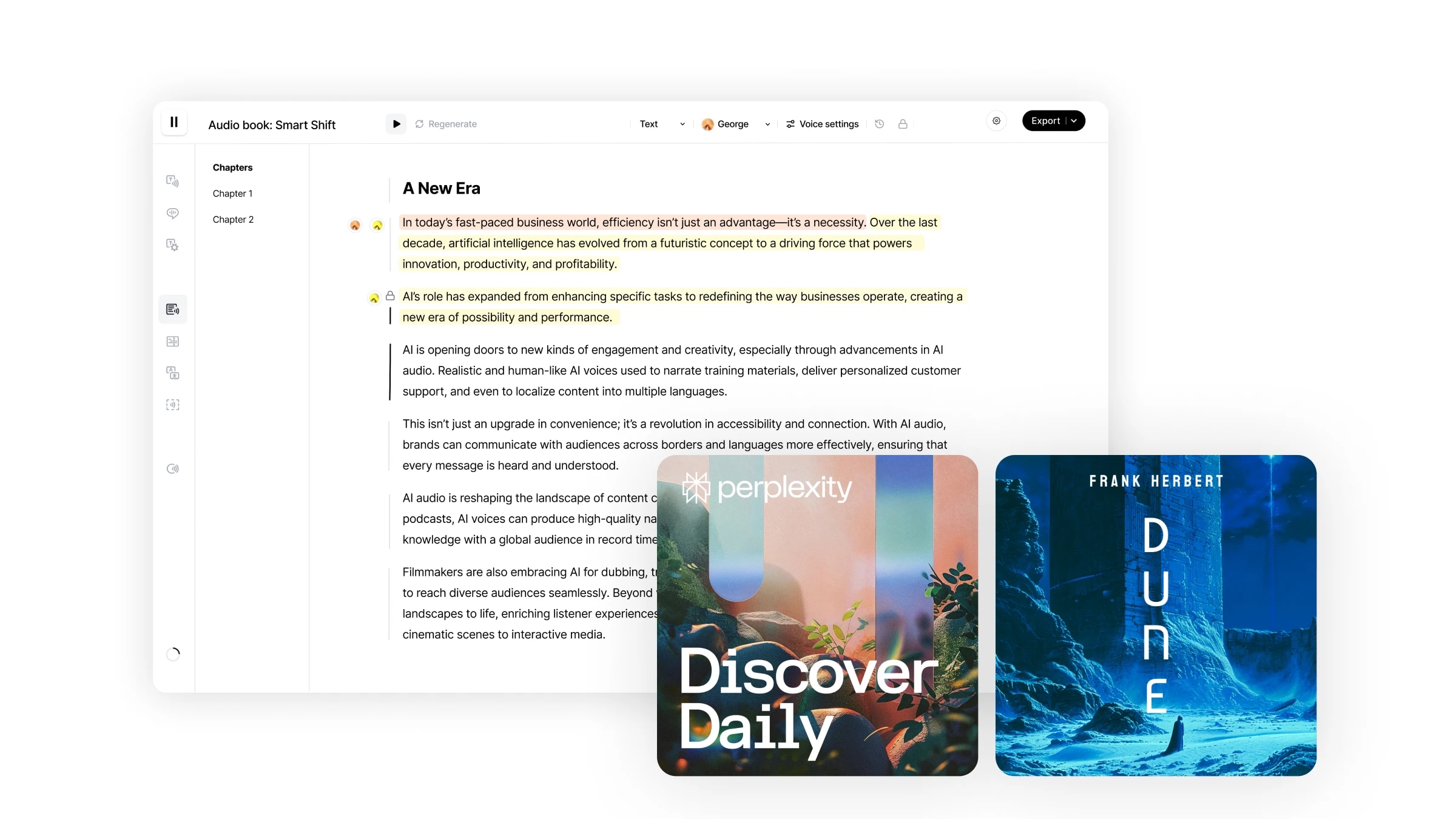
Studio es nuestro flujo de trabajo completo para crear audiolibros en minutos. Ofrece un nivel de control sin precedentes sobre tus creaciones de audio con la capacidad de regenerar fragmentos de audio específicos, asignar diferentes locutores a fragmentos de texto particulares, importar directamente archivos de múltiples formatos y más.
Navegar por Studio es fácil e intuitivo.
Studio proporciona una experiencia de usuario sencilla, similar a usar Google Docs, con una interfaz intuitiva y centrada en el usuario que admite una variedad de funciones de edición:
Tu flujo de trabajo completo para editar videos y audio, añadir locuciones y música, transcribir a texto y publicar producciones narradas y subtituladas
Studio se encuentra junto a Speech Synthesis, VoiceLab, y Voice Library, sirviendo como una solución integral para la síntesis de audio de larga duración. Además, está perfectamente integrado con Professional Voice Cloning, Voice Library y nuestro modelo multilingüe.
En ElevenLabs, nuestro compromiso con la innovación ha llevado al lanzamiento de un nuevo modelo multilingüe. Esto permite que la misma narrativa se traduzca y vocalice en hasta 28 idiomas. Para los editores, esto significa un alcance global sin precedentes, con historias que resuenan en diferentes culturas y regiones, todo en una voz consistente y unificada.
Los idiomas soportados ahora incluyen: Inglés, Coreano, Neerlandés, Chino, Turco, Sueco, Indonesio, Filipino, Japonés, Ucraniano, Griego, Checo, Finés, Rumano, Danés, Búlgaro, Malayo, Eslovaco, Croata, Árabe Clásico, Polaco, Alemán, Español, Francés, Italiano, Hindi, Portugués y Tamil.
Nuestra herramienta Voice Design proporciona una experiencia transformadora para los editores. Facilita la creación de voces completamente únicas basadas en parámetros seleccionados, como edad, género y acento. Cada voz generada es única, asegurando que los editores puedan elegir una voz particular para que se convierta en sinónimo de su marca o publicación.
Professional Voice Cloning (PVC) en ElevenLabs ofrece otra capa de personalización. Al clonar las voces de los reporteros de una publicación, podemos producir historias de audio en sus tonos únicos. Esto no solo proporciona autenticidad sino que también reduce significativamente los costos y el tiempo dedicado a los procesos de grabación tradicionales. Además, nuestro modelo multilingüe es compatible con Professional Voice Cloning, asegurando que la voz de un reportero pueda hablar ahora todos los idiomas soportados.

Automatiza locuciones de vídeo, lecturas de anuncios, pódcasts y mucho más, con tu propia voz
Escucha un episodio de podcast generado con nuestra herramienta de Professional Voice Cloning:
Para los editores, Professional Voice Cloning (PVC) ofrece numerosas ventajas:
Cuando se combina con la tecnología de Texto a Voz, los editores están equipados con un conjunto de herramientas de última generación para producir contenido auditivo rico, variado y global. Adoptar las capacidades de la tecnología de clonación de voz profesional es un movimiento progresivo para los editores, abriendo un sinfín de oportunidades.
El futuro de la publicación no está solo en la palabra escrita sino en cómo se transmiten esas palabras. Con herramientas como Texto a Voz, los editores tienen el potencial de revolucionar la entrega de su contenido, asegurando accesibilidad, singularidad y alcance global. En ElevenLabs, estamos a la vanguardia de esta transformación, ofreciendo tecnología que allana el camino para una experiencia auditiva más rica y diversa.
Actualización: a partir de enero de 2025, Projects ahora se llama Studio y está disponible para todos los usuarios gratuitos.

Demand for digital tour guides rises with 10k+ tours taken and an average of 53 minutes listening time per session

Supporting 10,000+ research conversations with natural, trustworthy voices
Desarrollado por ElevenLabs Agentes