Der Weg zur Echtzeit-Synchronisation
- Veröffentlicht
- Zuletzt aktualisiert
AnhörenArtikel anhören
Für manche erinnert Echtzeit-Synchronisation an den Babelfisch aus Per Anhalter durch die Galaxis.
Solange wir keine Gehirnwellen lesen können, müssen wir den gesprochenen Worten zuhören und sie in die Zielsprache übersetzen. Jedes Wort direkt beim Sprechen zu übersetzen, bringt echte Herausforderungen mit sich.
Stellen Sie sich vor, Sie möchten von Englisch auf Spanisch übersetzen. Der Sprecher beginnt mit „The“. Im Spanischen wird „The“ je nach Geschlecht mit „El“ oder „La“ übersetzt. Wir können „The“ also nicht sicher übersetzen, bevor wir mehr gehört haben.
Stellen Sie sich ein Szenario vor, in dem Sie von Englisch nach Spanisch übersetzen möchten. Der Sprecher beginnt mit „The“. Auf Spanisch wird „The“ mit „El“ für maskuline Wörter und „La“ für feminine Wörter übersetzt. Wir können „The“ also nicht mit Sicherheit übersetzen, bis wir mehr hören.

Stellen Sie sich vor, der Sprecher fährt fort mit „The running water“. Jetzt haben wir genug Informationen, um die ersten drei Wörter mit „El agua corriente“ zu übersetzen. Angenommen, der Satz geht weiter mit „The running water is too cold for swimming“, sind wir gut aufgestellt.
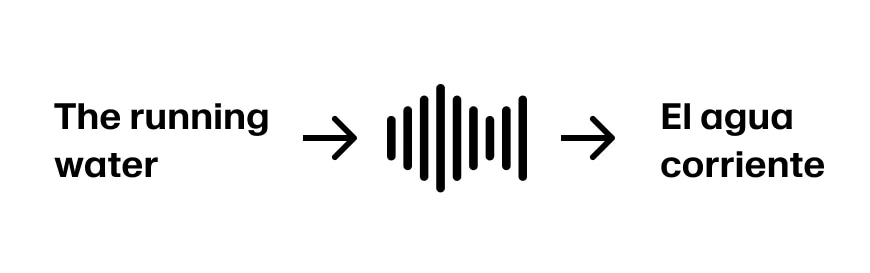
Aber wenn der Sprecher fortfährt mit „The running water buffalo…“, müssen wir zurückgehen.
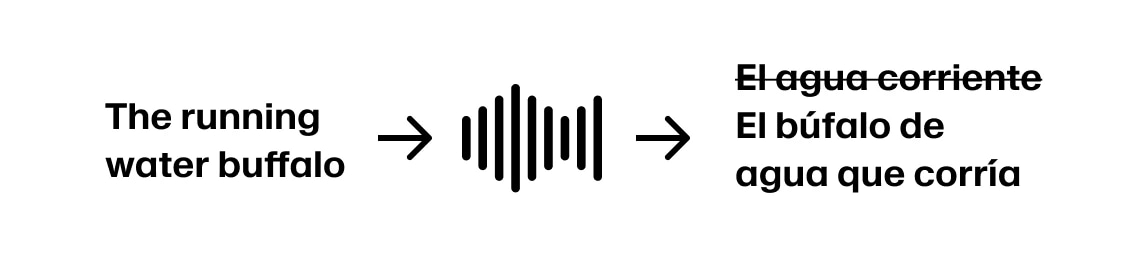
Diese „
Für manche Anwendungsfälle akzeptieren Sie vielleicht, dass Sie nach einem zu schnellen Start beim Synchronisieren zurückrudern müssen. In anderen Fällen können Sie sich für mehr Latenz und damit höhere Genauigkeit entscheiden. Da eine gewisse Latenz bei allenSynchronisation-Anwendungen unvermeidbar ist, definieren wir „Echtzeit-Synchronisation“ als einen Dienst, bei dem Sie Audio kontinuierlich streamen und übersetzte Inhalte zurückerhalten.
Für einige Anwendungsfälle sind Sie möglicherweise bereit, zu akzeptieren, dass Sie zurückgehen müssen, nachdem Sie zu schnell mit dem Synchronisieren begonnen haben. Für andere können Sie sich entscheiden, eine Verzögerung für mehr Genauigkeit hinzuzufügen. Da eine gewisse Verzögerung bei allen Synchronisationsanwendungen inhärent ist, definieren wir „Echtzeit“-Synchronisation als einen Dienst, durch den Sie kontinuierlich Audio streamen und übersetzte Inhalte zurückerhalten können.

Die besten kommerziellen Anwendungen für Echtzeit-Synchronisation sind dort, wo
Die besten kommerziellen Anwendungen der Echtzeit-Synchronisation sind diejenigen, bei denen
- Es ein globales Publikum gibt
- Es sich um Live-Inhalte handelt
- Es akzeptabel ist, eine gewisse Verzögerung in der Übertragung zu haben
Sport
Forbes berichtete 2019, dass die NBA 500 Millionen Dollar mit internationalen TV-Rechten verdient. Die NFL veranstaltet jetzt Spiele inBrasilien, England, Deutschland und Mexiko, da sie die internationale Expansion als zentralen Umsatztreiber der Zukunft sieht.
Vor Ort arbeiten meist mehrere Kamera- und Tontechniker, die ihr Material an eine Produktionsstätte senden. Dort wird zwischen Kameras umgeschaltet, der Ton gemischt, Grafiken eingeblendet und Kommentare hinzugefügt. Oft wird absichtlich eine zusätzliche Verzögerung eingebaut, um auf unpassende Inhalte reagieren zu können.
Das Hauptsignal geht an das Sende-Netzwerk, das eigene Marken und Werbung einfügt und den Inhalt an lokale Netzwerke verteilt. Schließlich gelangt das Signal über Kabel, Satellit oder Streaming-Dienste zum Endnutzer.
Der Hauptproduktionsfeed wird an das Rundfunknetz gesendet, das sein eigenes Branding und Werbung hinzufügt und die Inhalte an seine lokalen Netzwerke verteilt. Schließlich teilen die letzten Meilenanbieter die Inhalte über Kabel, Satellitenfeeds und Streaming-Dienste mit den Verbrauchern.

Sportunternehmen legen größten Wert auf ein hochwertiges Produkt. Entscheidend ist, die Emotion und das Timing der Kommentatoren einzufangen. „Er schießt, er trifft!“ muss mit Begeisterung vermittelt werden.
Unsere KI-Stimmen-Klonen-Modelle, die unseren Synchronisationsdienst unterstützen, können die Emotion und den Vortrag des Originals einfangen. Anders als bei der Übersetzung führt mehr Kontext nicht immer zu besseren Ergebnissen. Allerdings erreichen wir noch nicht das emotionale Niveau eines spanischen Fußballkommentators.
Jeder Stimmenklon ist ein Durchschnitt seiner Eingaben. Wenn Sie eine nüchterne Aussage wie „Sie müssen jetzt aggressiver werden, es bleiben nur noch zwei Minuten.“ mit „Er schießt, er trifft!“ kombinieren, ergibt sich ein mittlerer Ausdruck.
Jeder Sprachklon ist ein Durchschnitt seiner Eingaben. Wenn Sie eine Zeile kombinieren, die flach geliefert wird, wie „Sie müssen aggressiver sein, da nur noch zwei Minuten verbleiben.“ mit „Er schießt, er trifft!“, wird der resultierende Klon die durchschnittliche Darbietung der beiden sein.

Nachrichtenübertragung
Wie beim „Live“-Sport durchläuft auch die Nachrichtenübertragung eine Produktionskette mit Verzögerungen. Aus Gesprächen mit Medienunternehmen wissen wir: Die Emotion zu treffen ist zwar wichtig, aber weniger kritisch und meist einfacher, da Nachrichtensprecher sehr konstant sprechen. Entscheidend ist, dass die Übersetzung präzise und nuanciert ist.
Neben möglichen Ausfällen des automatisierten Übersetzungsdienstes gibt es Begriffe, die sich nicht direkt übertragen lassen. Zum Beispiel:
"Die Gemeinschaft versammelte sich zu einem Gedenktag, bei dem Überlebende ihre Geschichten teilten und Älteste traditionelle Gebete für Heilung abhielten."
Spanisch: "La comunidad se reunió para un día conmemorativo, donde los sobrevivientes compartieron sus historias y los ancianos realizaron oraciones tradicionales para la sanación."
Obwohl technisch korrekt, haben „survivors“ und „sobrevivientes“ in Kontexten historischer Traumata unterschiedliche Bedeutungen – im Englischen steht es oft für Widerstandskraft und Würde, während „sobrevivientes“ eher das Opfersein betont. Ebenso unterscheidet sich „performed prayers“ von „realizaron oraciones“ in der Wertung – „performed“ hebt die Zeremonie hervor, „realizaron“ klingt eher nach einem Ablauf.
Bonus – Der Weg zur Konversations-Synchronisation
Für natürliche Gespräche zwischen Menschen, die nicht dieselbe Sprache sprechen, braucht es nahezu sofortige Übersetzung.
Mit den Vorhersagewahrscheinlichkeiten für das nächste Token von LLMs lässt sich in Echtzeit abschätzen, wie ein Satz weitergeht.
Durch die Verwendung der nächsten Token-Vorhersagewahrscheinlichkeiten von LLMs haben Sie ein Echtzeitmodell der Wahrscheinlichkeit, wohin ein Satz geht.

Bildquelle - Hugging Face "How to generate text"
Sie finden das spannend und möchten mit uns an der Zukunft von KI-Audio arbeiten? Entdecken Sie
Finden Sie das interessant und möchten mit uns an der Zukunft der KI-Audio arbeiten? Entdecken Sie offene Stellen hier.

.jpg&w=3840&q=80)
.png&w=3840&q=80)
