
Ihr kompletter Workflow zum Bearbeiten von Videos und Audio, Hinzufügen von Voiceovers und Musik, Transkribieren in Text und Veröffentlichen von erzählten, untertitelten Produktionen
Mit Text to Speech können Geschichten sofort nach der Veröffentlichung in verschiedenen Stimmen und Sprechstilen gehört werden


Text to Speech (TTS)-Technologie verwandelt schriftliche Inhalte in hörbare Sprache. In den letzten Jahren, mit erheblichen Fortschritten im maschinellen Lernen, TTS Technologie hat sich so weit entwickelt, dass synthetisierte Sprache praktisch nicht mehr von menschlicher Erzählung zu unterscheiden ist. Der Realismus und die Ausdruckskraft, die moderne TTS Systeme bieten, eröffnen besonders für die Verlagsbranche enormes Potenzial.
Für Nachrichtenverlage ist die akustische Landschaft nicht nur ein aufstrebendes Feld, sondern eine Voraussetzung für Engagement. Der Ausbau einer Audio-Präsenz hat sich als förderlich für Benutzerbindung und Zufriedenheit erwiesen. Während der traditionelle Weg darin besteht, Sprecher zu engagieren oder Reporter zu bitten, zu erzählen, sind diese Methoden weder zeit- noch kosteneffizient. Mit Text to Speech können Geschichten sofort nach der Veröffentlichung vertont werden, was sicherstellt, dass der Inhalt frisch, relevant und von hoher Qualität bleibt.
Wie wir menschliche Darbietung selbst bei sehr langen Texten erreichen, liegt an der Art und Weise, wie wir unser Modell aufgebaut haben. Es ist darauf trainiert, zu verstehen, was gesagt wird und die Darbietung entsprechend anzupassen. Es berücksichtigt dabei nicht nur die Bedeutung der Wörter, sondern auch den Kontext jeder Äußerung.
Traditionelle Sprachgenerierungsalgorithmen erzeugen Äußerungen satzweise. Dies ist rechnerisch weniger anspruchsvoll, wirkt aber sofort robotisch. Emotionen und Intonation müssen oft über mehrere Sätze hinweg reichen, um einen bestimmten Gedankengang zusammenzuführen. Ton und Tempo vermitteln Absicht, was Sprache überhaupt erst menschlich klingen lässt. Anstatt jede Äußerung separat zu erzeugen, berücksichtigt unser Modell den umgebenden Kontext und erhält den angemessenen Fluss und die Prosodie über das gesamte generierte Material. Diese emotionale Tiefe, gepaart mit erstklassiger Audioqualität, bietet Nutzern das authentischste und überzeugendste Erzählwerkzeug.
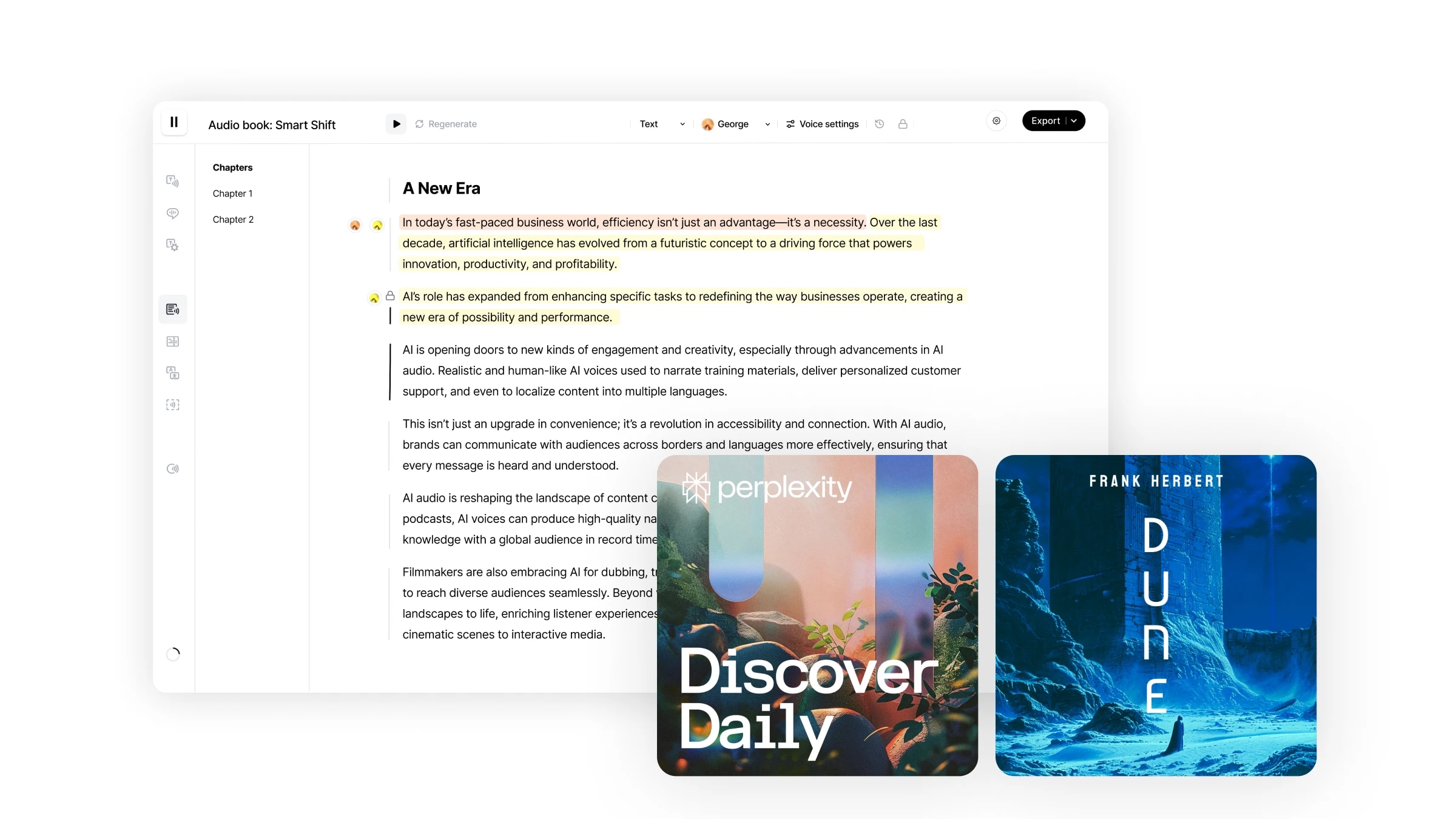
Studio ist unser End-to-End-Workflow zur Erstellung von Hörbüchern in Minuten. Es bietet ein beispielloses Maß an Kontrolle über Ihre Audiokreationen mit der Möglichkeit, spezifische Audioabschnitte neu zu generieren, verschiedene Sprecher bestimmten Textfragmenten zuzuweisen, mehrere Dateiformate direkt zu importieren und mehr.
Die Navigation in Studio ist einfach und intuitiv.
Studio bietet eine unkomplizierte Benutzererfahrung, ähnlich wie Google Docs, mit einer intuitiven, benutzerzentrierten Oberfläche, die eine Vielzahl von Bearbeitungsfunktionen unterstützt:
Ihr kompletter Workflow zum Bearbeiten von Videos und Audio, Hinzufügen von Voiceovers und Musik, Transkribieren in Text und Veröffentlichen von erzählten, untertitelten Produktionen
Studio steht neben Sprachsynthese, VoiceLab, und Voice Library, und dient als umfassende Lösung für Langform-Audiosynthese. Darüber hinaus ist es nahtlos integriert mit Professional Voice Cloning, Voice Library und unserem mehrsprachigen Modell.
Bei ElevenLabs hat unser Engagement für Innovation zur Einführung eines neuen mehrsprachigen Modells geführt. Dies ermöglicht es, dass dieselbe Erzählung in bis zu 28 Sprachen übersetzt und vertont werden kann. Für Verlage bedeutet dies eine beispiellose globale Reichweite, mit Geschichten, die in verschiedenen Kulturen und Regionen Anklang finden, alles in einer konsistenten und einheitlichen Stimme.
Unterstützte Sprachen sind jetzt: Englisch, Koreanisch, Niederländisch, Chinesisch, Türkisch, Schwedisch, Indonesisch, Filipino, Japanisch, Ukrainisch, Griechisch, Tschechisch, Finnisch, Rumänisch, Dänisch, Bulgarisch, Malaiisch, Slowakisch, Kroatisch, Klassisches Arabisch, Polnisch, Deutsch, Spanisch, Französisch, Italienisch, Hindi, Portugiesisch und Tamil.
Unser proprietäres Voice Design Tool bietet eine transformative Erfahrung für Verlage. Es erleichtert die Erstellung völlig einzigartiger Stimmen basierend auf ausgewählten Parametern wie Alter, Geschlecht und Akzent. Jede generierte Stimme ist einzigartig, was sicherstellt, dass Verlage eine bestimmte Stimme wählen können, die mit ihrer Marke oder Veröffentlichung gleichgesetzt wird.
Professionelles Voice Cloning (PVC) Technologie bei ElevenLabs bietet eine weitere Ebene der Anpassung. Durch das Klonen der Stimmen von Reportern einer Veröffentlichung können wir Audiogeschichten in ihren einzigartigen Tönen produzieren. Dies bietet nicht nur Authentizität, sondern reduziert auch erheblich die Kosten und die Zeit, die für traditionelle Aufnahmeprozesse aufgewendet werden. Darüber hinaus ist unser mehrsprachiges Modell mit Professional Voice Cloning kompatibel, sodass die Stimme eines Reporters nun alle unterstützten Sprachen sprechen kann.

Automatisieren Sie Voiceovers für Videos, Werbung, Podcasts und mehr – mit Ihrer eigenen Stimme.
Hören Sie sich eine Podcast-Episode an, die mit unserem Professional Voice Cloning-Tool erstellt wurde:
Für Verlage bietet Professional Voice Cloning (PVC) zahlreiche Vorteile:
In Kombination mit Text to Voice-Technologie sind Verlage mit einem hochmodernen Toolkit ausgestattet, um reichhaltige, vielfältige und globale akustische Inhalte zu produzieren. Die Übernahme der Fähigkeiten der Professional Voice Cloning-Technologie ist ein fortschrittlicher Schritt für Verlage und eröffnet eine Vielzahl von Möglichkeiten.
Die Zukunft des Verlagswesens liegt nicht nur im geschriebenen Wort, sondern darin, wie diese Worte vermittelt werden. Mit Tools wie Text to Voice haben Verlage das Potenzial, ihre Inhaltsbereitstellung zu revolutionieren, um Zugänglichkeit, Einzigartigkeit und globale Reichweite sicherzustellen. Bei ElevenLabs stehen wir an der Spitze dieser Transformation und bieten Technologie, die den Weg für ein reichhaltigeres, vielfältigeres Hörerlebnis ebnet.
Update: Ab Januar 2025 heißt Projects jetzt Studio und ist für alle kostenlosen Nutzer verfügbar.

Demand for digital tour guides rises with 10k+ tours taken and an average of 53 minutes listening time per session

Supporting 10,000+ research conversations with natural, trustworthy voices
Bereitgestellt von ElevenLabs Agenten