Wie wir RAG um 50 % schneller gemacht haben
- Verfasst von
- Michal Korbela
- Veröffentlicht
- Zuletzt aktualisiert
AnhörenArtikel anhören
RAG verbessert die Genauigkeit von KI-Agenten, indem es LLM-Antworten in großen Wissensdatenbanken verankert. Anstatt die gesamte Wissensdatenbank an das LLM zu senden, bettet RAG die Abfrage ein, ruft die relevantesten Informationen ab und übergibt sie als Kontext an das Modell. In unserem System fügen wir zuerst einen Schritt zur Abfrageumschreibung hinzu, indem wir den Dialogverlauf in eine präzise, eigenständige Abfrage zusammenfassen, bevor die Abfrage erfolgt.
Bei sehr kleinen Wissensdatenbanken kann es einfacher sein, alles direkt in den Prompt zu geben. Aber sobald die Wissensdatenbank größer wird, wird RAG unerlässlich, um die Antworten genau zu halten, ohne das Modell zu überfordern.
Viele Systeme behandeln RAG als externes Tool, wir haben es jedoch direkt in die Anforderungs-Pipeline integriert, sodass es bei jeder Abfrage läuft. Dies gewährleistet konsistente Genauigkeit, birgt jedoch auch ein Latenzrisiko.
Warum uns die Abfrageumschreibung verlangsamt hat
Die meisten Benutzeranfragen beziehen sich auf vorherige Runden, daher muss das System den Dialogverlauf in eine präzise, eigenständige Abfrage zusammenfassen.
Zum Beispiel:
- Wenn der Benutzer fragt:„Können wir diese Grenzen basierend auf unseren Spitzenverkehrsmustern anpassen?“
- Das System schreibt dies um zu:„Können die API-Ratenlimits des Enterprise-Plans für spezifische Verkehrsmuster angepasst werden?“
Die Umschreibung verwandelt vage Referenzen wie „diese Limits“ in eigenständige Abfragen, die von Abrufsystemen verwendet werden können, um den Kontext und die Genauigkeit der endgültigen Antwort zu verbessern. Aber die Abhängigkeit von einem einzigen extern gehosteten LLM schuf eine harte Abhängigkeit von dessen Geschwindigkeit und Verfügbarkeit. Dieser Schritt allein machte mehr als 80 % der RAG-Latenz aus.
Wie wir es mit Model Racing behoben haben
Wir haben die Abfrageumschreibung so umgestaltet, dass sie als Rennen läuft:
- Mehrere Modelle parallel. Jede Abfrage wird gleichzeitig an mehrere Modelle gesendet, einschließlich unserer selbst gehosteten Qwen 3-4B und 3-30B-A3B Modelle. Die erste gültige Antwort gewinnt.
- Fallbacks, die Gespräche am Laufen halten. Wenn kein Modell innerhalb einer Sekunde antwortet, greifen wir auf die Rohnachricht des Benutzers zurück. Sie mag weniger präzise sein, aber sie vermeidet Staus und gewährleistet Kontinuität.
.webp&w=3840&q=95)
Die Auswirkungen auf die Leistung
Diese neue Architektur halbierte die mittlere RAG-Latenz von 326 ms auf 155 ms. Im Gegensatz zu vielen Systemen, die RAG selektiv als externes Tool auslösen, führen wir es bei jeder Abfrage aus. Mit einer mittleren Latenz von 155 ms ist der Aufwand dafür vernachlässigbar.
Latenz vorher und nachher:
- Median: 326 ms → 155 ms
- p75: 436 ms → 250 ms
- p95: 629 ms → 426 ms
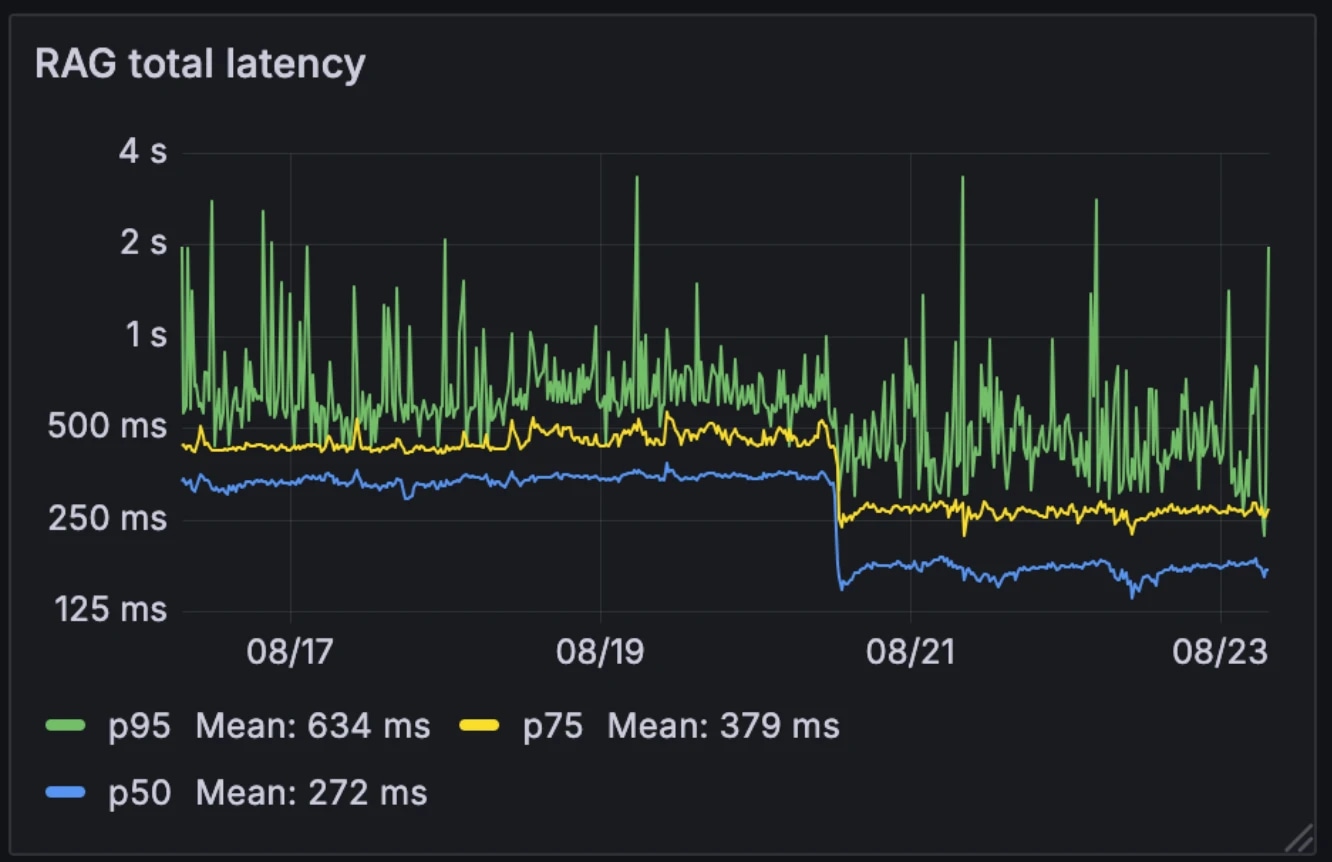
Die Architektur machte das System auch widerstandsfähiger gegenüber Modellvariabilität. Während extern gehostete Modelle während der Spitzenzeiten langsamer werden können, bleiben unsere internen Modelle relativ konstant. Das Rennen der Modelle glättet diese Variabilität und verwandelt unvorhersehbare individuelle Modellleistungen in ein stabileres Systemverhalten.
Zum Beispiel, als einer unserer LLM-Anbieter letzten Monat einen Ausfall hatte, liefen die Gespräche nahtlos auf unseren selbst gehosteten Modellen weiter. Da wir diese Infrastruktur bereits für andere Dienste betreiben, sind die zusätzlichen Rechenkosten vernachlässigbar.
Warum es wichtig ist
Die Umschreibung von RAG-Abfragen unter 200 ms beseitigt einen großen Engpass für Konversationsagenten. Das Ergebnis ist ein System, das sowohl kontextbewusst als auch in Echtzeit bleibt, selbst bei großen Unternehmenswissensdatenbanken. Mit auf nahezu vernachlässigbarem Niveau reduziertem Abrufaufwand können Konversationsagenten skalieren, ohne die Leistung zu beeinträchtigen.



.webp&w=3840&q=80)
