Eleven v3 Audio Tags: Ger situationsmedvetenhet till AI-ljud
- Skriven av
- Ryan Morrison
- Publicerad
- Senast uppdaterad
LyssnaLyssna på den här artikeln
Ljudtaggar är en grundläggande del av den nya
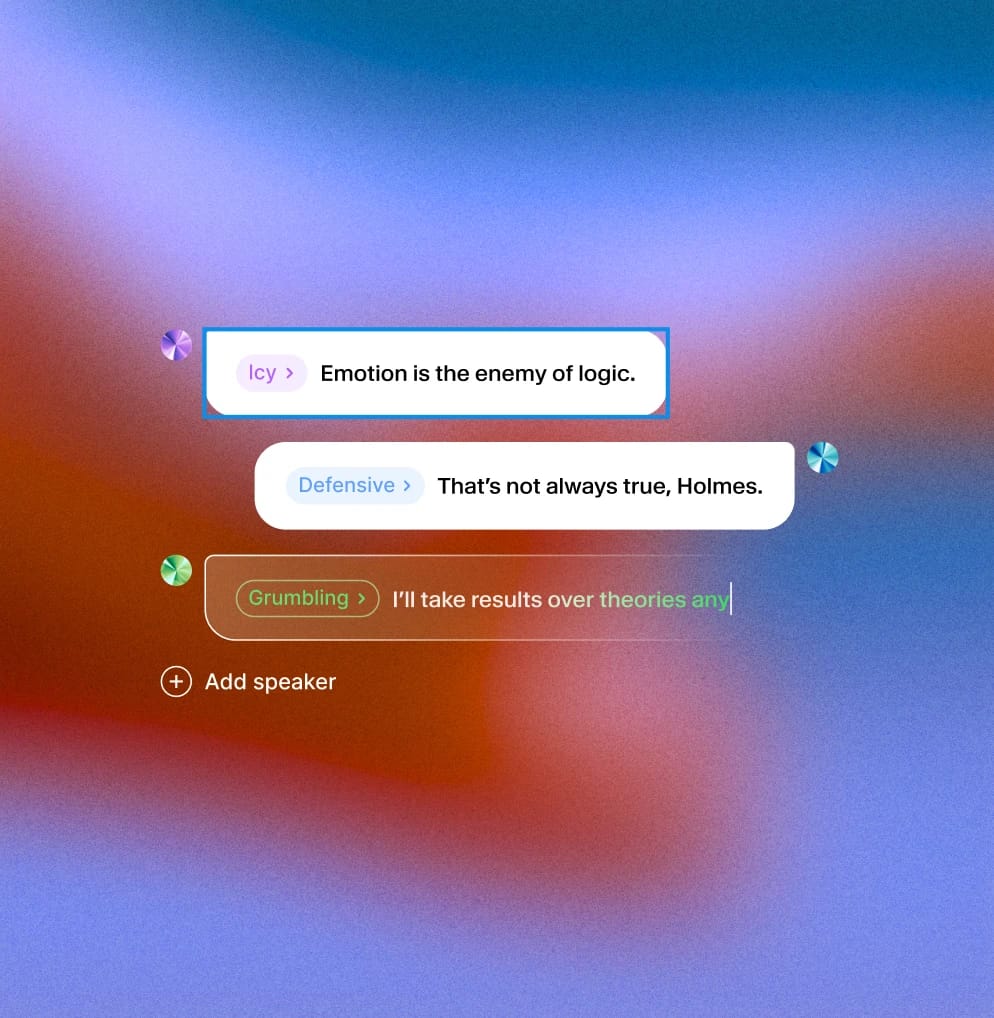
I sin enklaste form är Audio Tags ord inom hakparenteser. Modellen tolkar dessa som instruktioner för framträdandet. Det betyder att du kan justera leveransen mitt i en mening för att spegla känslomässiga skiftningar eller situationella förändringar — vilket ger AI:n en viss situationsmedvetenhet.
Vad är situationsmedvetenhet i AI-tal?


Situationsmedvetenhet innebär att AI:n anpassar sin leverans för att passa stunden. Med Audio Tags styr du inte bara vad modellen säger — utan hur den svarar.
Oavsett om du lägger till brådska med en [SHOUTING]-tagg, mildrar en varning med en [WHISPER], eller signalerar tvekan med [SIGH], förvandlar taggar berättande till framträdande. De är särskilt värdefulla i högkontext- eller dynamiska scener.
Framträdande, inte bara läsning
Föreställ dig att du skriver manus till en Veo 3-highlightvideo av en fotbollsmatch mellan 11 United och 12 United. Du vill att intensiteten ska öka med handlingen: “Han dribblar förbi en försvarare — [EXCITED] här kommer inlägget — [SHOUTING] MÅÅÅL!”
Eller så ger du röst åt ett spännande ögonblick i en
Detta är inte stilistiska tillägg. De definierar ögonblicket och styr hur det känns. Modellen läser inte — den framträder.
Vanliga taggar för situationsanvändning
Audio Tags låter dig simulera en rad känslomässiga och fysiska signaler:
- Känslomässig ton: [EXALTERAD], [NERVÖS], [FRUSTRERAD], [TRÖTT]
- Reaktioner: [GASP], [SUKTAR], [SKRATTAR], [SVÄLJER]
- Volym & energi: [VISKANDE], [SKRIKANDE], [TYST], [HÖGLJUTT]
- Tempo & rytm: [PAUSERAR], [STAMMAR], [HASTIGT]
Taggar kan kombineras för att lägga till nyanser: “[NERVOUSLY] Jag... jag är inte säker på att det här kommer att fungera. [GULPS] Men låt oss försöka ändå.”
Framträdande du kan styra
Eleven v3 stöder dessa taggar med en djupare kontextuell modell. Den kan ändra ton mitt i en replik, hantera avbrott och bibehålla flödet — vilket ger dig en leverans som känns mer naturlig utan att skriva om manuset.
För
Välja rätt röst
Professionella Voice Clones (PVC) är ännu inte helt optimerade för Eleven v3, vilket kan ge sämre kloningskvalitet jämfört med tidigare modeller. Under den här forskningsperioden är det bäst att hitta en Instant