Como projetamos o RAG para ser 50% mais rápido
- Escrito por
- Michal Korbela
- Publicado
- Última atualização
OuvirOuça este artigo
O RAG melhora a precisão para agentes de IA ao basear as respostas de LLM em grandes bases de conhecimento. Em vez de enviar toda a base de conhecimento para o LLM, o RAG incorpora a consulta, recupera as informações mais relevantes e as passa como contexto para o modelo. Em nosso sistema, adicionamos primeiro uma etapa de reescrita de consultas, colapsando o histórico de diálogo em uma consulta precisa e autossuficiente antes da recuperação.
Para bases de conhecimento muito pequenas, pode ser mais simples passar tudo diretamente no prompt. Mas, uma vez que a base de conhecimento cresce, o RAG se torna essencial para manter as respostas precisas sem sobrecarregar o modelo.
Muitos sistemas tratam o RAG como uma ferramenta externa, no entanto, nós o incorporamos diretamente no pipeline de solicitações para que ele funcione em todas as consultas. Isso garante precisão consistente, mas também cria um risco de latência.
Por que a reescrita de consultas nos atrasou
A maioria das solicitações dos usuários faz referência a turnos anteriores, então o sistema precisa colapsar o histórico de diálogo em uma consulta precisa e autossuficiente.
Por exemplo:
- Se o usuário perguntar:“Podemos personalizar esses limites com base nos nossos padrões de pico de tráfego?"
- O sistema reescreve isso para:“Os limites de taxa da API do plano Enterprise podem ser personalizados para padrões de tráfego específicos?”
A reescrita transforma referências vagas como “esses limites” em consultas autossuficientes que os sistemas de recuperação podem usar, melhorando o contexto e a precisão da resposta final. Mas depender de um único LLM hospedado externamente criou uma dependência rígida de sua velocidade e tempo de atividade. Esta etapa sozinha representava mais de 80% da latência do RAG.
Como resolvemos isso com model racing
Redesenhamos a reescrita de consultas para funcionar como uma corrida:
- Múltiplos modelos em paralelo. Cada consulta é enviada para vários modelos ao mesmo tempo, incluindo nossos modelos Qwen 3-4B e 3-30B-A3B auto-hospedados. A primeira resposta válida vence.
- Fallbacks que mantêm as conversas fluindo. Se nenhum modelo responder em um segundo, voltamos à mensagem bruta do usuário. Pode ser menos precisa, mas evita interrupções e garante continuidade.
.webp&w=3840&q=95)
O impacto no desempenho
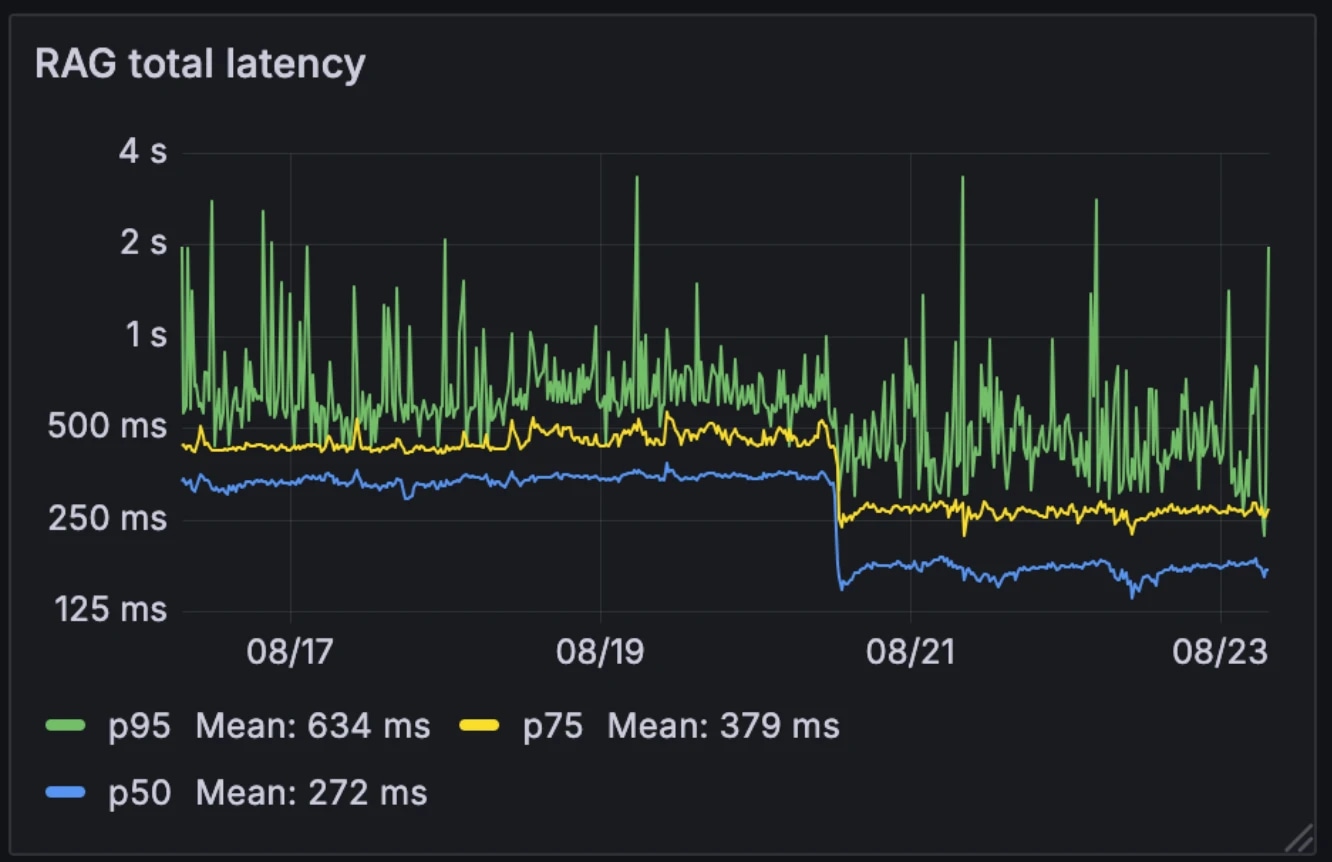
Esta nova arquitetura reduziu a latência média do RAG pela metade, de 326ms para 155ms. Ao contrário de muitos sistemas que acionam o RAG seletivamente como uma ferramenta externa, nós o executamos em todas as consultas. Com a latência média reduzida para 155ms, o custo adicional de fazer isso é insignificante.
Latência antes e depois:
- Média: 326ms → 155ms
- p75: 436ms → 250ms
- p95: 629ms → 426ms
A arquitetura também tornou o sistema mais resiliente à variabilidade dos modelos. Enquanto modelos hospedados externamente podem desacelerar durante horas de pico, nossos modelos internos permanecem relativamente consistentes. A corrida dos modelos suaviza essa variabilidade, transformando o desempenho imprevisível de modelos individuais em um comportamento de sistema mais estável.
Por exemplo, quando um de nossos provedores de LLM sofreu uma interrupção no mês passado, as conversas continuaram sem problemas em nossos modelos auto-hospedados. Como já operamos essa infraestrutura para outros serviços, o custo adicional de computação é insignificante.
Por que isso importa
A reescrita de consultas RAG abaixo de 200ms remove um grande gargalo para agentes conversacionais. O resultado é um sistema que permanece tanto consciente do contexto quanto em tempo real, mesmo ao operar sobre grandes bases de conhecimento empresariais. Com a sobrecarga de recuperação reduzida a níveis quase insignificantes, agentes conversacionais podem escalar sem comprometer o desempenho.



.webp&w=3840&q=80)
