Comment nous avons rendu RAG 50% plus rapide
- Rédigé par
- Michal Korbela
- Publié
- Dernière mise à jour
ÉcouterÉcouter cet article
RAG améliore la précision des agents IA en ancrant les réponses des LLM dans de grandes bases de connaissances. Plutôt que d'envoyer toute la base de connaissances au LLM, RAG intègre la requête, récupère les informations les plus pertinentes et les transmet comme contexte au modèle. Dans notre système, nous ajoutons d'abord une étape de réécriture de requête, en condensant l'historique du dialogue en une requête précise et autonome avant la récupération.
Pour de très petites bases de connaissances, il peut être plus simple de tout inclure directement dans l'invite. Mais une fois que la base de connaissances s'agrandit, RAG devient essentiel pour maintenir des réponses précises sans surcharger le modèle.
De nombreux systèmes traitent RAG comme un outil externe, cependant nous l'avons intégré directement dans le pipeline de requêtes pour qu'il fonctionne à chaque requête. Cela garantit une précision constante mais crée également un risque de latence.
Pourquoi la réécriture des requêtes nous ralentissait
La plupart des demandes des utilisateurs font référence à des tours précédents, donc le système doit condenser l'historique du dialogue en une requête précise et autonome.
Par exemple :
- Si l'utilisateur demande :« Pouvons-nous personnaliser ces limites en fonction de nos pics de trafic ? »
- Le système réécrit cela en :« Les limites de taux de l'API du plan Enterprise peuvent-elles être personnalisées pour des modèles de trafic spécifiques ? »
La réécriture transforme des références vagues comme « ces limites » en requêtes autonomes que les systèmes de récupération peuvent utiliser, améliorant le contexte et la précision de la réponse finale. Mais dépendre d'un LLM hébergé à l'extérieur créait une dépendance forte à sa vitesse et sa disponibilité. Cette étape seule représentait plus de 80% de la latence de RAG.
Comment nous avons résolu cela avec la compétition de modèles
Nous avons repensé la réécriture des requêtes pour qu'elle fonctionne comme une course :
- Plusieurs modèles en parallèle. Chaque requête est envoyée à plusieurs modèles en même temps, y compris nos modèles Qwen 3-4B et 3-30B-A3B auto-hébergés. La première réponse valide l'emporte.
- Solutions de secours qui maintiennent la fluidité des conversations. Si aucun modèle ne répond en une seconde, nous revenons au message brut de l'utilisateur. Il peut être moins précis, mais il évite les blocages et assure la continuité.
.webp&w=3840&q=95)
L'impact sur la performance
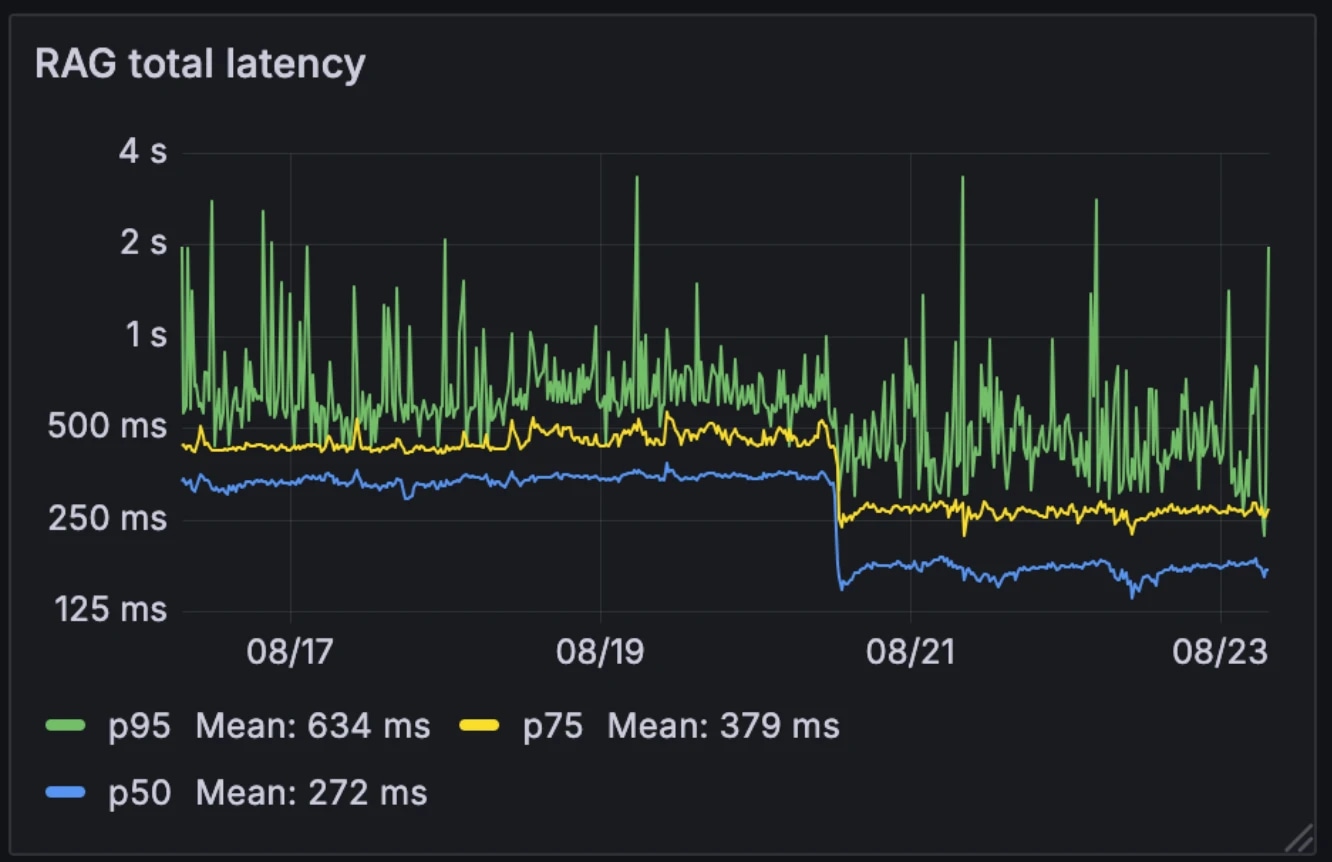
Cette nouvelle architecture a réduit de moitié la latence médiane de RAG, passant de 326ms à 155ms. Contrairement à de nombreux systèmes qui déclenchent RAG de manière sélective comme un outil externe, nous l'exécutons à chaque requête. Avec une latence médiane réduite à 155ms, le surcoût de cette opération est négligeable.
Latence avant et après :
- Médiane : 326ms → 155ms
- p75 : 436ms → 250ms
- p95 : 629ms → 426ms
L'architecture a également rendu le système plus résilient face à la variabilité des modèles. Alors que les modèles hébergés à l'extérieur peuvent ralentir pendant les heures de pointe, nos modèles internes restent relativement constants. La compétition entre les modèles atténue cette variabilité, transformant des performances individuelles imprévisibles en un comportement système plus stable.
Par exemple, lorsqu'un de nos fournisseurs de LLM a connu une panne le mois dernier, les conversations ont continué sans interruption sur nos modèles auto-hébergés. Puisque nous exploitons déjà cette infrastructure pour d'autres services, le coût supplémentaire de calcul est négligeable.
Pourquoi c'est important
La réécriture des requêtes RAG en moins de 200ms élimine un obstacle majeur pour les agents conversationnels. Le résultat est un système qui reste à la fois conscient du contexte et en temps réel, même lorsqu'il fonctionne sur de grandes bases de connaissances d'entreprise. Avec une surcharge de récupération réduite à des niveaux presque négligeables, les agents conversationnels peuvent évoluer sans compromettre la performance.



.webp&w=3840&q=80)
