Introducing Multimodal Conversational AI
- Written by
- Angelo Giacco
- Published
ListenListen to this article
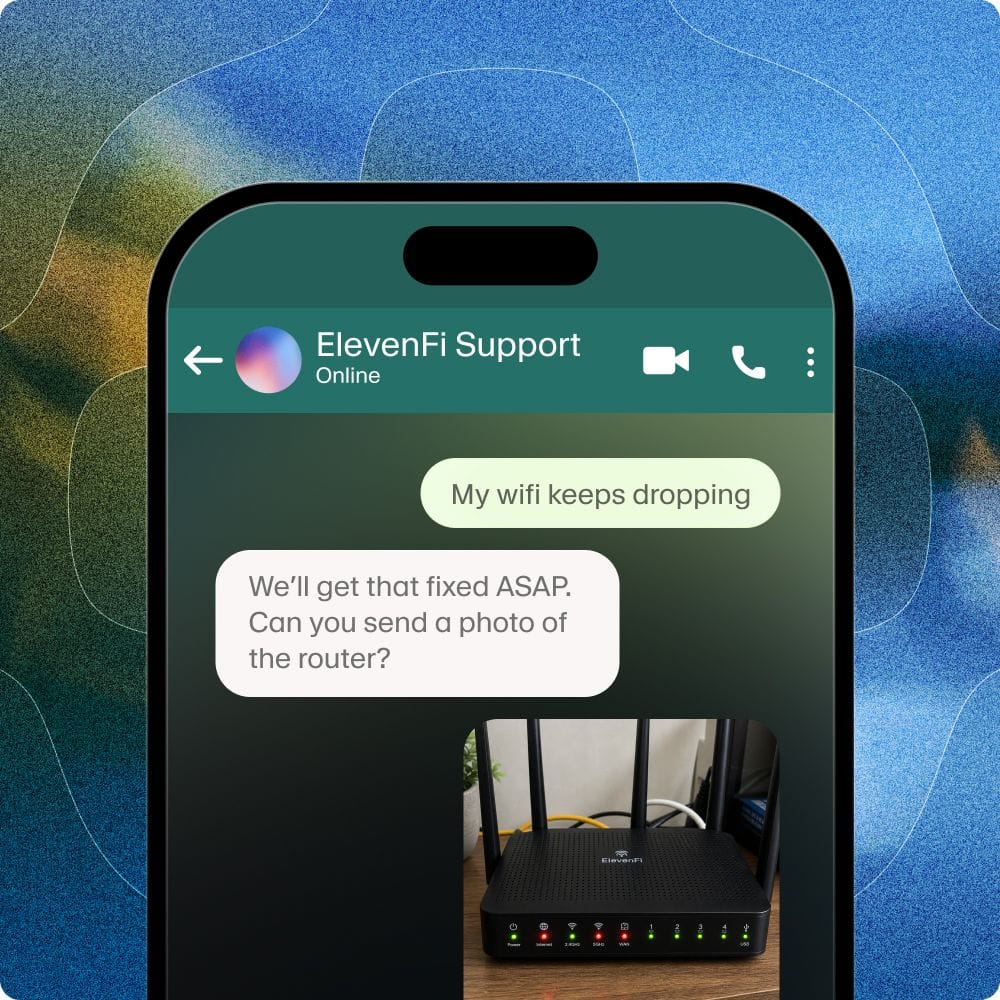
Today, ElevenLabs is excited to announce a significant enhancement to our Conversational AI platform: the introduction of true text and voice multimodality. Our AI agents can now understand and process both spoken language and typed text inputs concurrently. This capability is designed to create more natural, flexible, and effective interactions for a wide range of use cases.
Addressing Limitations in Voice-Only Interactions
While voice offers a powerful and intuitive means of communication, voice-only AI agents can encounter challenges in certain situations. We have observed common failure modes in business deployments, such as:
- Transcription Inaccuracies: Capturing specific alphanumeric data like email addresses, IDs, or tracking numbers perfectly through voice alone can be difficult. Errors can lead to significant downstream issues, such as looking up incorrect customer records.
- User Experience for Complex Inputs: Requesting users to verbally provide lengthy sequences of numbers, like credit card details, can be a frustrating and error-prone experience.
The Power of Multimodality: Text and Voice Together
By enabling agents to process both text and voice, we empower users to choose the input method best suited to the information they need to convey. This hybrid approach allows for smoother, more robust conversations. Users can speak naturally and then, when precision is paramount or typing is more convenient, seamlessly switch to text input within the same interaction.
Core Benefits
The introduction of text and voice multimodality offers several key advantages:
- Increased Interaction Accuracy: Allows users to type information that is difficult to articulate or prone to transcription errors.
- Enhanced User Experience: Provides flexibility, making interactions feel more natural and less constrained, particularly for sensitive or complex data entry.
- Improved Task Completion Rates: Reduces errors and frustration, leading to more successful outcomes.
- More Natural Conversational Flow: Allows for effortless transitions between input types, mimicking human conversational adaptability.
Key Features
Our multimodal Conversational AI includes the following functionalities:
- Simultaneous Processing: Agents can interpret and respond to a combination of voice and text inputs in real-time.
- Easy Configuration: Text input can be enabled with a simple setting in the widget configuration.
- Text-Only Mode: Agents can be configured to operate as traditional text-based chatbots if required.
Seamless Integration and Deployment
This new multimodal functionality is natively supported across our platform:
- Widget: Deployable with a single line of HTML.
- SDKs: Full support for developers looking to integrate deeply.
- WebSocket: Real-time, bidirectional communication with multimodal capabilities.
Building on a Leading Platform
Multimodal interactions benefit from all the existing innovations within our Conversational AI platform:
- Industry-Leading Voices: Access to the highest quality voices in over 32 languages.
- Advanced Speech Models: Leveraging our state-of-the-art speech-to-text and text-to-speech technologies.
- Global Infrastructure: Already deployed everywhere with Twilio and SIP trunking infrastructure.
Getting Started
To begin using text and voice multimodality with your ElevenLabs Conversational AI agents:
- Navigate to your widget configuration settings.
- Enable the "Allow Text Input" option.
We believe that text+voice multimodality will significantly enhance the capabilities and user experience of Conversational AI. We look forward to seeing how our users leverage this powerful new feature.
.jpg&w=3840&q=80)