
Customer Stories

Tutore deploys conversational agents for corporate language training using ElevenLabs
90% of Tutore’s placement interviews are now conducted by AI agents, accelerating onboarding and reducing costs
Miesiąc po premierze Scribe wciąż udowadnia, że to najdokładniejszy model speech to text na rynku.

W zaledwie miesiąc od premiery nasz model speech to text Scribe przyciągnął tysiące firm dzięki swojej dokładności. Od napisów w mediach po call center i transkrypcje medyczne – Scribe szybko stał się wyborem deweloperów.
Niezależne analizy potwierdziły nasze wyniki – Scribe wypada lepiej niż wszystkie modele, w tym nowe modele transkrypcji 4o od OpenAI. Na przykład, według benchmarku Analiza AI Scribe ma niższy Word Error Rate niż 4o i 4o mini, średnio:
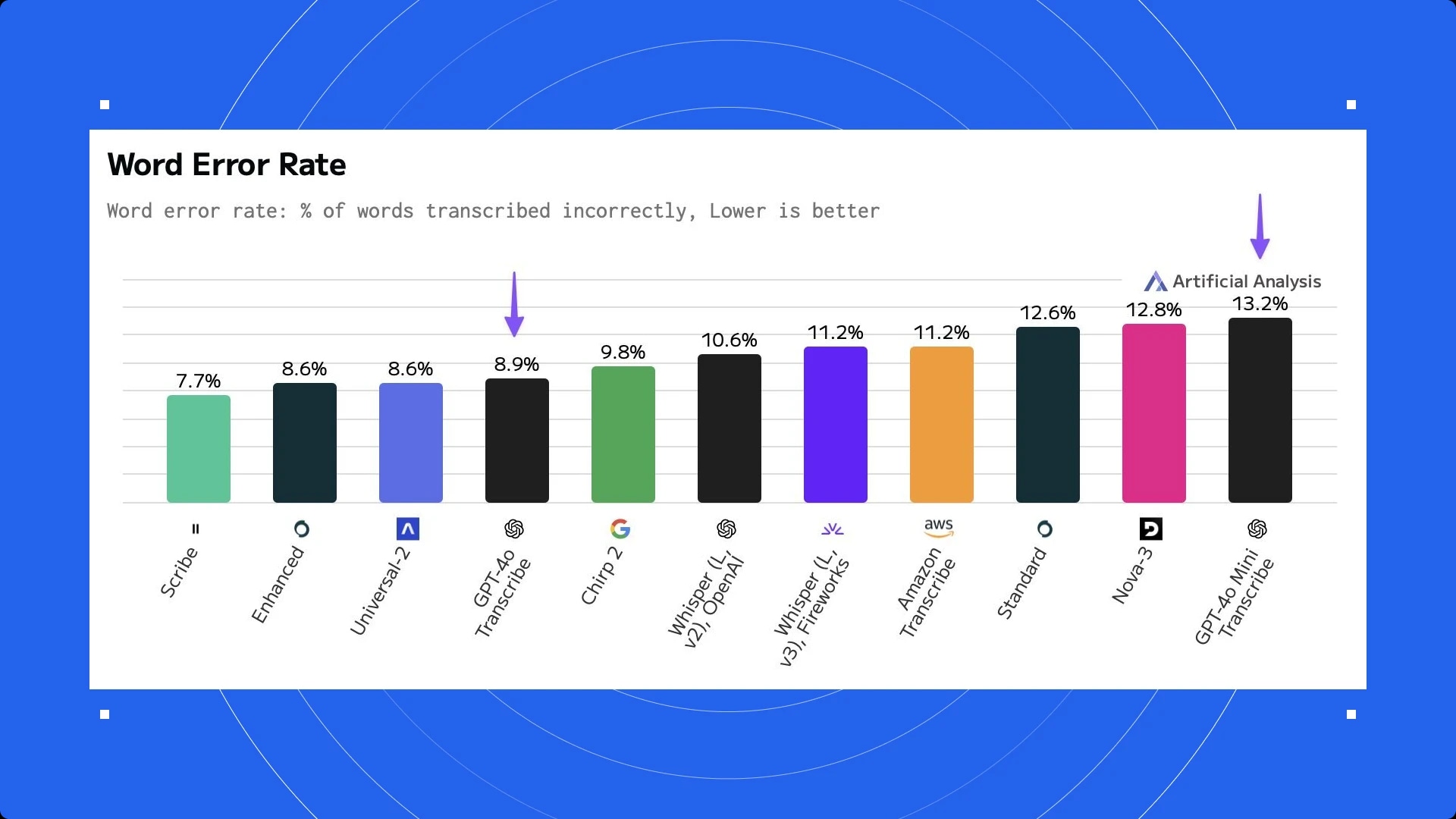
Scribe wypada lepiej lub na równi z modelami 4o i 4o mini w benchmarkach OpenAI w 11 z 15 testowanych języków. Na przykład w japońskim i hindi Scribe jest znacznie lepszy od obu modeli OpenAI według ich własnych testów:
Tworząc Scribe, postawiliśmy na praktyczność dla klientów, nawet jeśli czasem wpływa to na wyniki w branżowych benchmarkach. Na przykład:
Dlatego warto patrzeć na końcowe wyniki, gdy myślisz o wydajności. Na przykład w angielskim model OpenAI 4o Speech to Text wypada podobnie do Scribe w benchmarkach, ale porównanie transkrypcji pokazuje przewagę Scribe.
W tej analizie transkrypcji z brytyjskiego posiedzenia parlamentu widać, że Scribe nie popełnia błędów, dobrze rozpoznaje akcenty, różne barwy głosu i poprawnie oznacza szumy tła oraz śmiech.
Scribe od ElevenLabs (Czas transkrypcji: 4,66 s)
Czy mogę zapytać szanownego pana jakie działania są podejmowane, by to miejsce było bardziej dostępne, zwłaszcza dla naszych kolegów z niepełnosprawnościami?Brawo, brawo. (szmery na sali) Przepraszam, to chyba przez moje pochodzenie z Antypodów. Czy mógłby pan powtórzyć pytanie? Nie zrozumiałem.(śmiech na sali) Wow. O, wow. Dziś bardzo popularny. Yyy, mówiłem, że kilku posłów z niepełnosprawnościami ma trudności z poruszaniem się po niektórych częściach budynku. Skoro trwa remont, co można zrobić, by osoby z niepełnosprawnościami mogły się swobodniej poruszać i miejsce było dostępne?Pan Paul. (śmiech na sali) Bardzo przepraszam. Czy mógłby pan powiedzieć to bardzo powoli po angielsku z Antypodów? Dziękuję. Po prostu odpowiedz cokolwiek. Myślę, że odpowiedź... może będzie łatwiej, jeśli odpowiesz na piśmie kiedy przeczytasz, panie Marszałku. Dobrze, Chris Elmore. (śmiech) Dziękuję, panie wicemarszałku, spróbuję za pierwszym razem.(szmery na sali) O nie. Jesteś Walijczykiem. Czy mogę- czy mogę- bo ja jestem z Walii, więc niech mu Bóg pomoże.
OpenAI 4o (Czas transkrypcji: 5,01 s)
Czy mogę zapytać szanownego pana jakie działania są podejmowane, by to miejsce było bardziej dostępne, zwłaszcza dla naszych kolegów z niepełnosprawnościami?Przepraszam, to chyba przez moje pochodzenie z Antypodów. Czy mógłby pan powtórzyć pytanie? Nie zrozumiałem.No cóż, dziś bardzo popularny. Widzę, że kilku posłów z niepełnosprawnościami ma trudności z poruszaniem się po niektórych częściach budynku. Skoro trwa remont, co można zrobić, by osoby z niepełnosprawnościami mogły się swobodniej poruszać i miejsce było dostępne?Bardzo przepraszam. Czy mógłbyś powiedzieć to bardzo powoli po angielsku z Antypodów?Myślę, że odpowiedź może być łatwiejsza, jeśli odpowiesz na piśmie kiedy to przeczytasz.Dziękuję, panie wicemarszałku. Spróbuję za pierwszym razem.Bo jestem z Walii, więc niech mu Bóg pomoże.
Każdy postęp w AI to ogromna szansa dla osób jąkających się. Jąkanie, genetyczne zaburzenie mowy, dotyczy ok. 1% ludzi i stanowi wyzwanie dla systemów rozpoznawania mowy. W badaniu, gdzie jąkanie pojawiało się w prawie co czwartym słowie, Scribe osiągnął średnio 98,7% dokładności. To kolejny dowód, że Scribe wyznacza standardy i jest modelem dla każdej firmy.
Scribe sprawdza się w firmach dzięki funkcjom stworzonym z myślą o ich potrzebach.
Wypróbuj Scribe, nasz produkt webowy jest darmowy do 9 kwietnia. Ceny Scribe są bardzo konkurencyjne – od 0,22$/godz. dla firm. Jeśli chcesz, napisz do naszego zespołu, chętnie pokażemy demo i pokażemy, jak możemy pomóc twojej firmie.
90% of Tutore’s placement interviews are now conducted by AI agents, accelerating onboarding and reducing costs
.webp&w=3840&q=95)
Generate individual vocals, instruments or full tracks with stylistic consistency using a fine-tuned version of our Music model.