Jak przyspieszyliśmy RAG o 50%
- Autor
- Michal Korbela
- Opublikowano
- Ostatnia aktualizacja
PosłuchajPosłuchaj tego artykułu
RAG poprawia dokładność agentów AI, opierając odpowiedzi LLM na dużych bazach wiedzy. Zamiast wysyłać całą bazę wiedzy do LLM, RAG osadza zapytanie, pobiera najbardziej istotne informacje i przekazuje je jako kontekst do modelu. W naszym systemie najpierw dodajemy krok przepisywania zapytań, łącząc historię dialogu w precyzyjne, samodzielne zapytanie przed pobraniem.
Dla bardzo małych baz wiedzy prościej jest przekazać wszystko bezpośrednio do promptu. Ale gdy baza wiedzy rośnie, RAG staje się niezbędny, aby utrzymać dokładność odpowiedzi bez przeciążania modelu.
Wiele systemów traktuje RAG jako narzędzie zewnętrzne, jednak my wbudowaliśmy go bezpośrednio w pipeline zapytań, aby działał przy każdym zapytaniu. To zapewnia stałą dokładność, ale także stwarza ryzyko opóźnień.
Dlaczego przepisywanie zapytań nas spowalniało
Większość zapytań użytkowników odnosi się do wcześniejszych tur, więc system musi łączyć historię dialogu w precyzyjne, samodzielne zapytanie.
Na przykład:
- Jeśli użytkownik pyta:„Czy możemy dostosować te limity do naszych szczytowych wzorców ruchu?"
- System przepisuje to na:„Czy limity API planu Enterprise mogą być dostosowane do specyficznych wzorców ruchu?”
Przepisywanie zamienia niejasne odniesienia jak „te limity” na samodzielne zapytania, które systemy pobierania mogą używać, poprawiając kontekst i dokładność ostatecznej odpowiedzi. Ale poleganie na jednym zewnętrznie hostowanym LLM stworzyło silną zależność od jego szybkości i dostępności. Ten krok sam w sobie odpowiadał za ponad 80% opóźnień RAG.
Jak to naprawiliśmy dzięki model racing
Przeprojektowaliśmy przepisywanie zapytań, aby działało jako wyścig:
- Wiele modeli równolegle. Każde zapytanie jest wysyłane do wielu modeli jednocześnie, w tym naszych samodzielnie hostowanych modeli Qwen 3-4B i 3-30B-A3B. Pierwsza poprawna odpowiedź wygrywa.
- Zapasowe rozwiązania, które utrzymują płynność rozmów. Jeśli żaden model nie odpowie w ciągu jednej sekundy, wracamy do surowej wiadomości użytkownika. Może być mniej precyzyjna, ale unika zacięć i zapewnia ciągłość.
.webp&w=3840&q=95)
Wpływ na wydajność
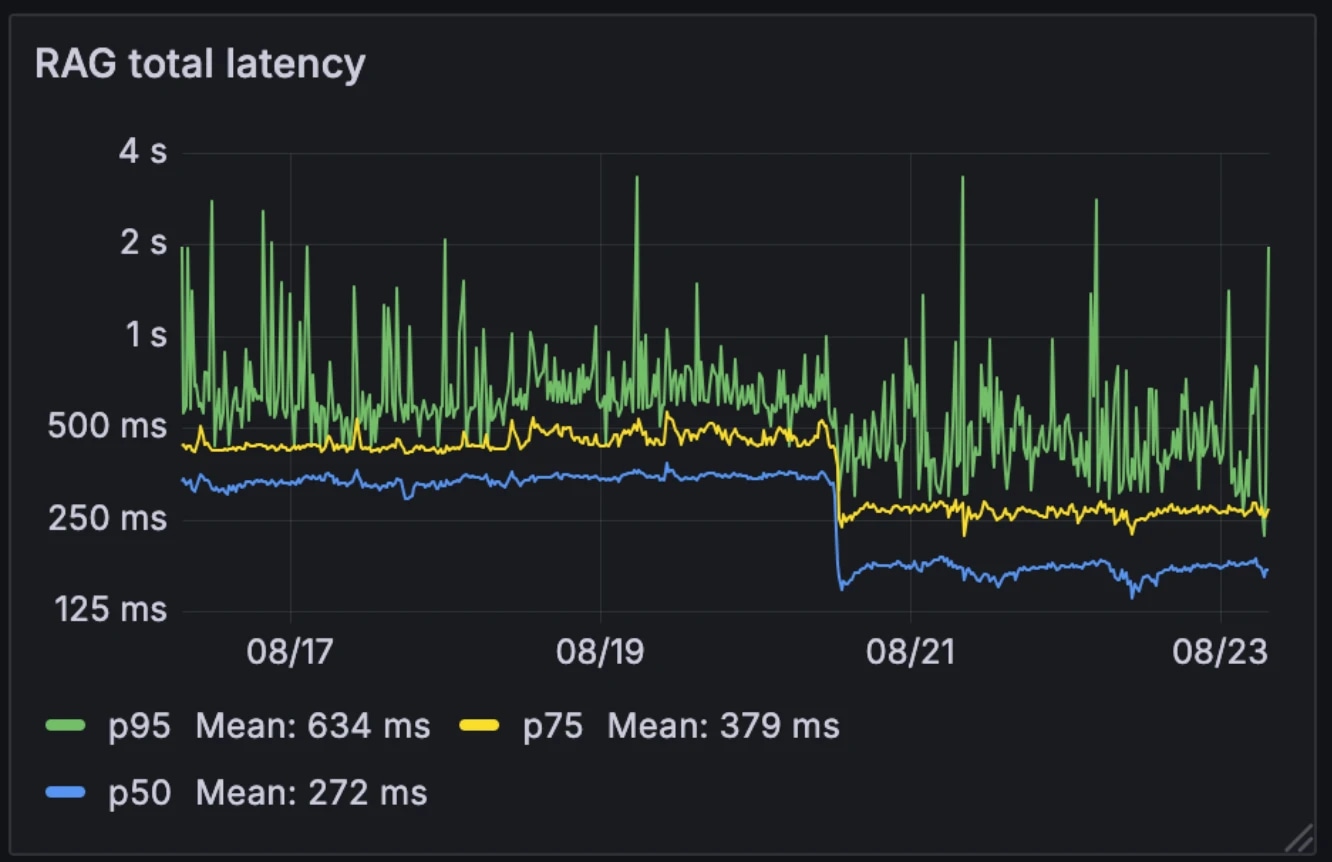
Ta nowa architektura zmniejszyła medianę opóźnień RAG o połowę, z 326ms do 155ms. W przeciwieństwie do wielu systemów, które uruchamiają RAG selektywnie jako narzędzie zewnętrzne, my uruchamiamy go przy każdym zapytaniu. Z medianą opóźnień na poziomie 155ms, dodatkowe obciążenie jest znikome.
Opóźnienia przed i po:
- Mediana: 326ms → 155ms
- p75: 436 ms → 250 ms
- p95: 629 ms → 426 ms
Architektura również uczyniła system bardziej odpornym na zmienność modeli. Podczas gdy modele hostowane zewnętrznie mogą zwalniać w godzinach szczytu, nasze wewnętrzne modele pozostają stosunkowo stabilne. Wyścigi modeli wygładzają tę zmienność, przekształcając nieprzewidywalną wydajność pojedynczych modeli w bardziej stabilne zachowanie systemu.
Na przykład, gdy jeden z naszych dostawców LLM doświadczył awarii w zeszłym miesiącu, rozmowy kontynuowały się płynnie na naszych samodzielnie hostowanych modelach. Ponieważ już obsługujemy tę infrastrukturę dla innych usług, dodatkowy koszt obliczeniowy jest znikomy.
Dlaczego to ważne
Przepisywanie zapytań RAG poniżej 200ms usuwa główną przeszkodę dla agentów konwersacyjnych. Rezultatem jest system, który pozostaje zarówno świadomy kontekstu, jak i działa w czasie rzeczywistym, nawet przy dużych bazach wiedzy przedsiębiorstw. Dzięki zmniejszeniu obciążenia pobierania do niemal znikomego poziomu, agenci konwersacyjni mogą się skalować bez kompromisów w wydajności.



.webp&w=3840&q=80)
