RAGを50%高速化するための工夫
- 公開日
- 最終更新日
聴くこの記事を聴く
RAGは、大規模な知識ベースに基づいてLLMの応答を補強し、AIエージェントの精度を向上させます。知識ベース全体をLLMに送信するのではなく、RAGはクエリを埋め込み、最も関連性の高い情報を取得し、モデルにコンテキストとして渡します。私たちのシステムでは、まずクエリの書き換えステップを追加し、対話履歴を正確で自己完結型のクエリにまとめてから取得します。
非常に小さな知識ベースの場合、すべてを直接プロンプトに渡す方が簡単です。しかし、知識ベースが大きくなると、RAGはモデルを圧倒せずに応答の精度を保つために不可欠です。
多くのシステムはRAGを外部ツールとして扱いますが、私たちはこれをリクエストパイプラインに直接組み込み、すべてのクエリで実行されるようにしました。これにより一貫した精度が保証されますが、遅延のリスクも生じます。
クエリの書き換えが遅延を引き起こした理由
ほとんどのユーザーリクエストは以前のターンを参照するため、システムは対話履歴を正確で自己完結型のクエリにまとめる必要があります。
例えば:
- ユーザーが次のように尋ねた場合:「ピークトラフィックのパターンに基づいて、これらの制限をカスタマイズできますか?」
- システムはこれを次のように書き換えます:「エンタープライズプランのAPIレート制限は特定のトラフィックパターンに合わせてカスタマイズできますか?」
書き換えにより、「その制限」などの曖昧な参照が取得システムで使用できる自己完結型のクエリに変わり、最終応答のコンテキストと精度が向上します。しかし、外部ホストのLLMに依存することで、その速度と稼働時間に大きく依存することになりました。このステップだけでRAGの遅延の80%以上を占めていました。
モデルレースでの解決方法
クエリの書き換えをレースとして再設計しました:
- 複数のモデルを並行して使用。各クエリは、セルフホストのQwen 3-4Bおよび3-30B-A3Bモデルを含む複数のモデルに同時に送信されます。最初に有効な応答を返したものが勝ちます。
- 会話を途切れさせないフォールバック。1秒以内にモデルが応答しない場合、ユーザーの生メッセージにフォールバックします。精度は低くなるかもしれませんが、停滞を避け、継続性を確保します。
.webp&w=3840&q=95)
パフォーマンスへの影響
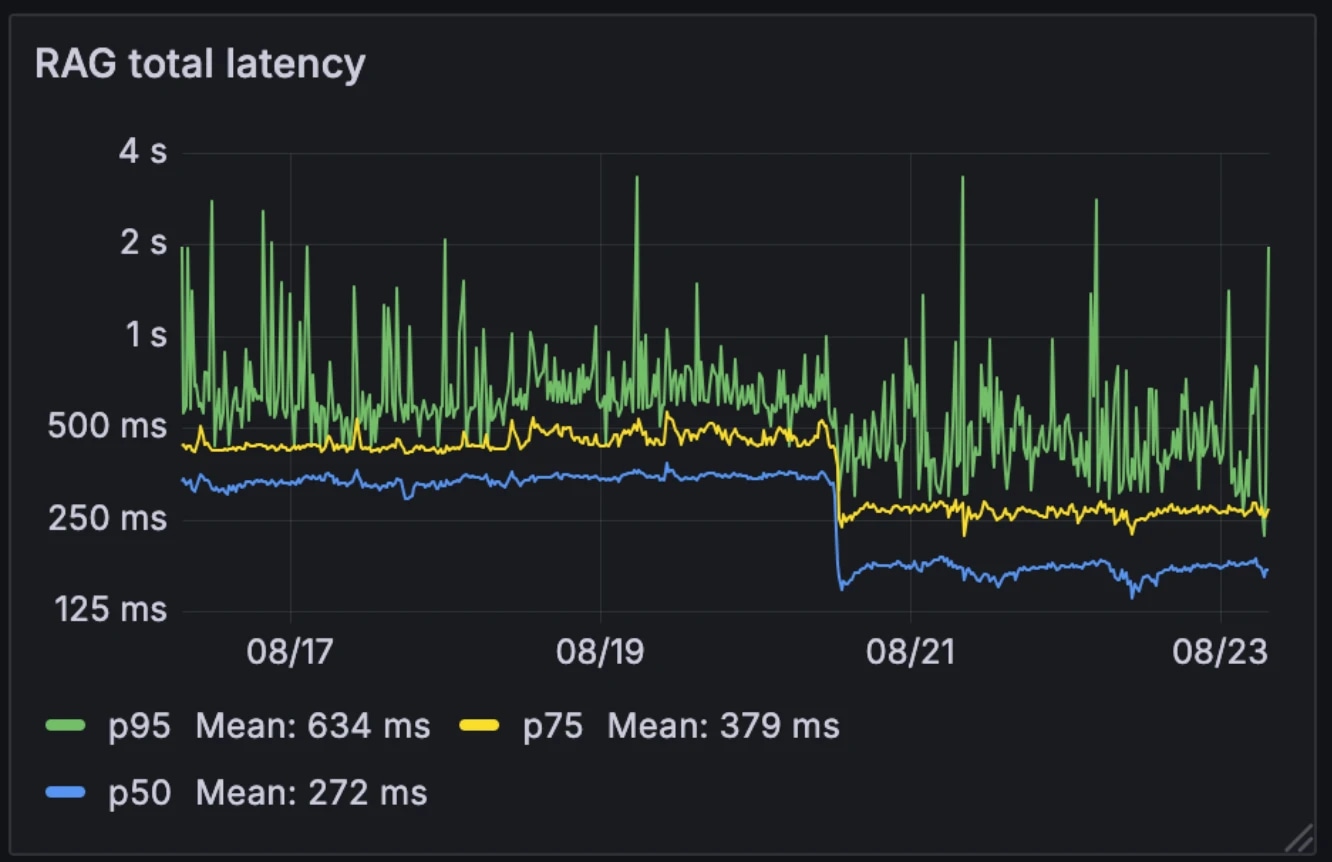
この新しいアーキテクチャにより、RAGの中央値遅延が326msから155msに半減しました。多くのシステムがRAGを外部ツールとして選択的にトリガーするのに対し、私たちはすべてのクエリで実行しています。中央値の遅延が155msに下がったことで、このオーバーヘッドは無視できるレベルになりました。
遅延の前後:
- 中央値:326ms → 155ms
- p75:436ms → 250ms
- p95:629ms → 426ms
このアーキテクチャにより、モデルの変動性に対するシステムの耐性も向上しました。外部ホストのモデルはピーク時に遅くなることがありますが、内部モデルは比較的一貫しています。モデルを競わせることで、この変動性を平滑化し、予測不可能な個々のモデルのパフォーマンスをより安定したシステムの動作に変えます。
例えば、先月、LLMプロバイダーの一つが停止した際も、会話はセルフホストのモデルでシームレスに続きました。他のサービスのためにすでにこのインフラを運用しているため、追加の計算コストは無視できる程度です。
なぜ重要なのか
200ms未満のRAGクエリ書き換えは、会話型エージェントの主要なボトルネックを取り除きます。その結果、大規模なエンタープライズ知識ベースを扱う際でも、コンテキストを把握しつつリアルタイムで動作するシステムが実現します。取得のオーバーヘッドがほぼ無視できるレベルに減少したことで、会話型エージェントはパフォーマンスを損なうことなくスケールできます。



.webp&w=3840&q=80)
