रियल-टाइम डबिंग का सफर
- प्रकाशित
- आखिरी बार अपडेट किया गया
सुनेंइस आर्टिकल को सुनें
कुछ लोगों के लिए, रियल-टाइम डबिंग 'हिचहाइकर गाइड टू द गैलेक्सी' के बेबेलफिश की छवि को उभारती है।
जब तक हम दिमागी तरंगें पढ़ना नहीं सीख जाते, हमें बोलने वाले के शब्द सुनकर उन्हें अपनी पसंदीदा भाषा में ट्रांसलेट करना होगा। हर शब्द को जैसे ही वो बोले, वैसे ही ट्रांसलेट करने में कई मुश्किलें आती हैं।
सोचिए आपको इंग्लिश से स्पैनिश में ट्रांसलेट करना है। स्पीकर ने बोला "The"। स्पैनिश में "The" को मर्दाना शब्दों के लिए "El" और औरतों के लिए "La" कहते हैं। तो जब तक हमें आगे के शब्द न मिलें, हम "The" को सही तरीके से ट्रांसलेट नहीं कर सकते।
कल्पना करें कि आप अंग्रेजी से स्पेनिश में अनुवाद करना चाहते हैं। वक्ता 'The' से शुरू करता है। स्पेनिश में, 'The' का अनुवाद 'El' होता है पुरुषवाचक शब्दों के लिए और 'La' होता है स्त्रीवाचक शब्दों के लिए। इसलिए हम 'The' का निश्चित रूप से अनुवाद नहीं कर सकते जब तक हमें और जानकारी न मिले।

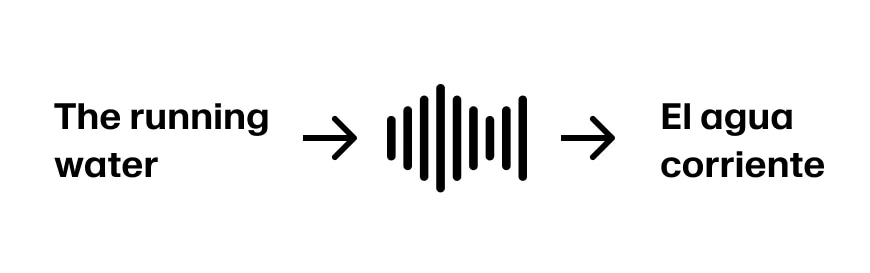
कल्पना करें कि वक्ता जारी रखता है 'The running water'। अब हमारे पास पहले तीन शब्दों का अनुवाद 'El agua corriente' करने के लिए पर्याप्त जानकारी है। मान लें कि वाक्य जारी रहता है 'The running water is too cold for swimming' तो हम सही दिशा में हैं।
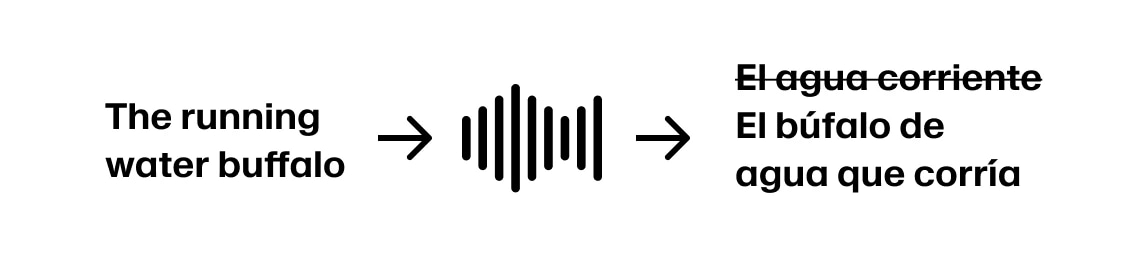
लेकिन अगर वक्ता जारी रखता है 'The running water buffalo...' तो हमें पीछे हटना पड़ेगा।
ये "
कुछ मामलों में, आप मान सकते हैं कि जल्दी डबिंग शुरू करने के बाद आपको पीछे जाकर सुधारना पड़ सकता है। बाकी मामलों में, आप ज्यादा सटीकता के लिए थोड़ी देरी जोड़ सकते हैं। चूंकि हर डबिंग केस में थोड़ी देरी होती ही है, हम "रीयल-टाइम" डबिंग को ऐसी सर्विस मानते हैं जिसमें आप लगातार ऑडियो स्ट्रीम कर सकते हैं और तुरंत ट्रांसलेटेड कंटेंट पा सकते हैं।
कुछ उपयोग मामलों के लिए, आप स्वीकार कर सकते हैं कि आपको जल्दी डबिंग शुरू करने के बाद पीछे हटना पड़ेगा। अन्य मामलों में, आप अधिक सटीकता के लिए विलंब जोड़ सकते हैं। चूंकि कुछ विलंब सभी डबिंग उपयोग मामलों में अंतर्निहित होता है, हम 'रियल-टाइम' डबिंग को एक सेवा के रूप में परिभाषित करते हैं जिसके माध्यम से आप लगातार ऑडियो स्ट्रीम कर सकते हैं और अनुवादित सामग्री प्राप्त कर सकते हैं।

रीयल-टाइम डबिंग के सबसे अच्छे कमर्शियल इस्तेमाल वे हैं जहाँ
रियल-टाइम डबिंग के सर्वोत्तम व्यावसायिक अनुप्रयोग वे हैं जहाँ
- एक वैश्विक दर्शक है
- यह लाइव सामग्री है
- प्रसारण में कुछ विलंब स्वीकार्य है
खेल
फोर्ब्स ने 2019 में रिपोर्ट किया कि NBA अंतरराष्ट्रीय टीवी अधिकारों में $500m कमा रहा है। NFL अब ब्राज़ील, इंग्लैंड, जर्मनी और मेक्सिको में खेल आयोजित कर रहा है क्योंकि यह भविष्य में अंतरराष्ट्रीय विस्तार को एक मुख्य राजस्व चालक के रूप में देखता है।
आमतौर पर कई कैमरा और साउंड ऑपरेटर साइट पर होते हैं, जो अपनी फुटेज प्रोडक्शन फैसिलिटी को भेजते हैं। वहां कैमरा फीड्स बदली जाती हैं, ऑडियो मिक्स होता है, ग्राफिक्स जोड़े जाते हैं और कमेंट्री डाली जाती है। कभी-कभी जानबूझकर थोड़ी और देरी भी जोड़ते हैं ताकि गाली-गलौज या अनचाही चीजें सेंसर की जा सकें।
मुख्य प्रोडक्शन फीड ब्रॉडकास्ट नेटवर्क को भेजी जाती है, जो अपनी ब्रांडिंग और विज्ञापन जोड़कर कंटेंट को लोकल नेटवर्क्स तक पहुंचाते हैं। आखिर में, केबल, सैटेलाइट और स्ट्रीमिंग सर्विसेज के जरिए कंटेंट दर्शकों तक पहुंचता है।
मुख्य प्रोडक्शन फीड को प्रसारण नेटवर्क को भेजा जाता है जो अपनी ब्रांडिंग और विज्ञापन जोड़ते हैं और सामग्री को अपने स्थानीय नेटवर्क में वितरित करते हैं। अंत में, अंतिम मील प्रदाता केबल, सैटेलाइट फीड्स और स्ट्रीमिंग सेवाओं के माध्यम से उपभोक्ताओं के साथ सामग्री साझा करते हैं।

स्पोर्ट्स कंपनियों के लिए सबसे जरूरी है कि वे क्वालिटी प्रोडक्ट दें, और उनका मानना है कि क्वालिटी का राज है ब्रॉडकास्टर्स की भावना और टाइमिंग को सही से पकड़ना। "He shoots, he scores!" को जोश के साथ सुनाना जरूरी है।
हमारे वॉइस क्लोनिंग मॉडल्स, जो हमारी डबिंग सर्विस की नींव हैं, ओरिजिनल स्पीकर की भावना और डिलीवरी को पकड़ सकते हैं। ट्रांसलेशन के मुकाबले, ज्यादा कॉन्टेक्स्ट हमेशा बेहतर रिजल्ट नहीं देता। लेकिन हम अभी भी स्पैनिश फुटबॉल कमेंटेटर जैसी भावना तक नहीं पहुंचे हैं!
हर वॉइस क्लोन अपने इनपुट्स का औसत होता है। अगर आप एक सपाट लाइन "They are going to need to be more aggressive with only two minutes remaining." को "He shoots, he scores!" जैसी जोशीली लाइन के साथ मिलाते हैं, तो क्लोन दोनों का औसत डिलीवरी देगा।
प्रत्येक वॉइस क्लोन अपने इनपुट्स का औसत होता है। यदि आप एक पंक्ति को जोड़ते हैं जो सपाट रूप से प्रस्तुत की गई है जैसे 'उन्हें अधिक आक्रामक होने की आवश्यकता होगी क्योंकि केवल दो मिनट शेष हैं।' के साथ 'वह शूट करता है, वह स्कोर करता है!', तो परिणामी क्लोन दोनों की औसत प्रस्तुति होगी।

न्यूज़ ब्रॉडकास्टिंग
जैसे "लाइव" स्पोर्ट्स में होता है, न्यूज़ ब्रॉडकास्टिंग भी एक प्रोडक्शन पाइपलाइन से गुजरती है जिसमें देरी जुड़ती है। मीडिया कंपनियों से हमारी बातचीत में पता चला कि भावना को सही पकड़ना (जरूरी होते हुए भी) उतना मुश्किल नहीं है क्योंकि ज्यादातर न्यूज़कास्टर्स की डिलीवरी बहुत स्थिर होती है। लेकिन ट्रांसलेशन का सटीक और बारीक होना बहुत जरूरी है।
ऑटोमेटेड ट्रांसलेशन सर्विस में गड़बड़ी की संभावना के अलावा, कुछ कॉन्सेप्ट्स का सीधा ट्रांसलेशन नहीं होता। उदाहरण देखें:
"समुदाय एक साथ इकट्ठा हुआ, जहां सर्वाइवर्स ने अपनी कहानियां साझा कीं और बुजुर्गों ने हीलिंग के लिए पारंपरिक प्रार्थनाएं कीं।"
स्पैनिश: "La comunidad se reunió para un día conmemorativo, donde los sobrevivientes compartieron sus historias y los ancianos realizaron oraciones tradicionales para la sanación."
तकनीकी रूप से सही होने के बावजूद, "survivors" और "sobrevivientes" का मतलब ऐतिहासिक ट्रॉमा के संदर्भ में अलग हो सकता है - इंग्लिश में ये अक्सर मजबूती और गरिमा दिखाता है, जबकि "sobrevivientes" पीड़ित होने पर जोर देता है। इसी तरह, "performed prayers" और "realizaron oraciones" में भी फर्क है - "performed" में रस्म की अहमियत है, जबकि "realizaron" ज्यादा औपचारिक लग सकता है।
बोनस - कन्वर्सेशनल डबिंग की ओर
ऐसे लोगों के बीच स्वाभाविक, आमने-सामने बातचीत के लिए, जो एक-दूसरे की भाषा नहीं जानते, लगभग तुरंत ट्रांसलेशन चाहिए।
LLMs के नेक्स्ट टोकन प्रेडिक्शन प्रॉबेबिलिटी का इस्तेमाल करके, आपके पास रीयल-टाइम में यह जानने का तरीका है कि वाक्य आगे किस ओर जा सकता है।
LLMs की अगली टोकन भविष्यवाणी संभावनाओं का उपयोग करके, आपके पास एक वास्तविक समय मॉडल होता है कि एक वाक्य कहाँ जा रहा है।

छवि स्रोत - Hugging Face "How to generate text"
अगर आपको ये दिलचस्प लगा और आप AI ऑडियो के भविष्य पर हमारे साथ काम करना चाहते हैं, तो देखें
क्या यह दिलचस्प लगता है और आप AI ऑडियो के भविष्य पर हमारे साथ काम करना चाहते हैं? यहाँ खुले पदों का अन्वेषण करें.




