
Votre flux de travail complet pour éditer des vidéos et des audios, ajouter des voix off et de la musique, transcrire en texte et publier des productions narrées et sous-titrées
Avec Text to Speech, les histoires peuvent être entendues immédiatement après publication, dans une variété de voix et de styles de livraison


Text to Speech (TTS) transforme le contenu écrit en discours audible. Ces dernières années, avec des avancées significatives en apprentissage automatique, TTS a évolué au point où la synthèse vocale est pratiquement indiscernable de la narration humaine. Le réalisme et l'expressivité atteints par les systèmes modernes TTS offrent un potentiel inégalé, particulièrement pour l'industrie de l'édition.
Pour les éditeurs de nouvelles, le paysage sonore n'est pas seulement un domaine émergent mais une nécessité pour l'engagement. Développer une présence audio a prouvé qu'elle améliore la rétention et la satisfaction des utilisateurs. Alors que la voie traditionnelle impliquerait d'engager des doubleurs ou de faire narrer les reporters, ces méthodes ne sont ni efficaces en temps ni en coût. Avec Text to Speech, les histoires peuvent être vocalisées immédiatement après publication, garantissant que le contenu reste frais, pertinent et de haute qualité.
Comment nous parvenons à une livraison humaine même sur des textes très longs repose sur la façon dont nous avons construit notre modèle. Il est formé pour comprendre ce qui est dit et ajuster la livraison en conséquence. Il le fait en tenant compte non seulement du sens des mots mais aussi du contexte entourant chaque énoncé.
Les algorithmes traditionnels de génération de parole produisent des énoncés phrase par phrase. Cela demande moins de calculs mais semble immédiatement robotique. Les émotions et l'intonation doivent souvent s'étendre et résonner sur plusieurs phrases pour lier une pensée particulière. Le ton et le rythme transmettent l'intention, ce qui rend la parole humaine. Plutôt que de générer chaque énoncé séparément, notre modèle prend en compte le contexte environnant, maintenant un flux et une prosodie appropriés sur l'ensemble du matériel généré. Cette profondeur émotionnelle, couplée à une qualité audio de premier ordre, offre aux utilisateurs l'outil de narration le plus authentique et captivant.
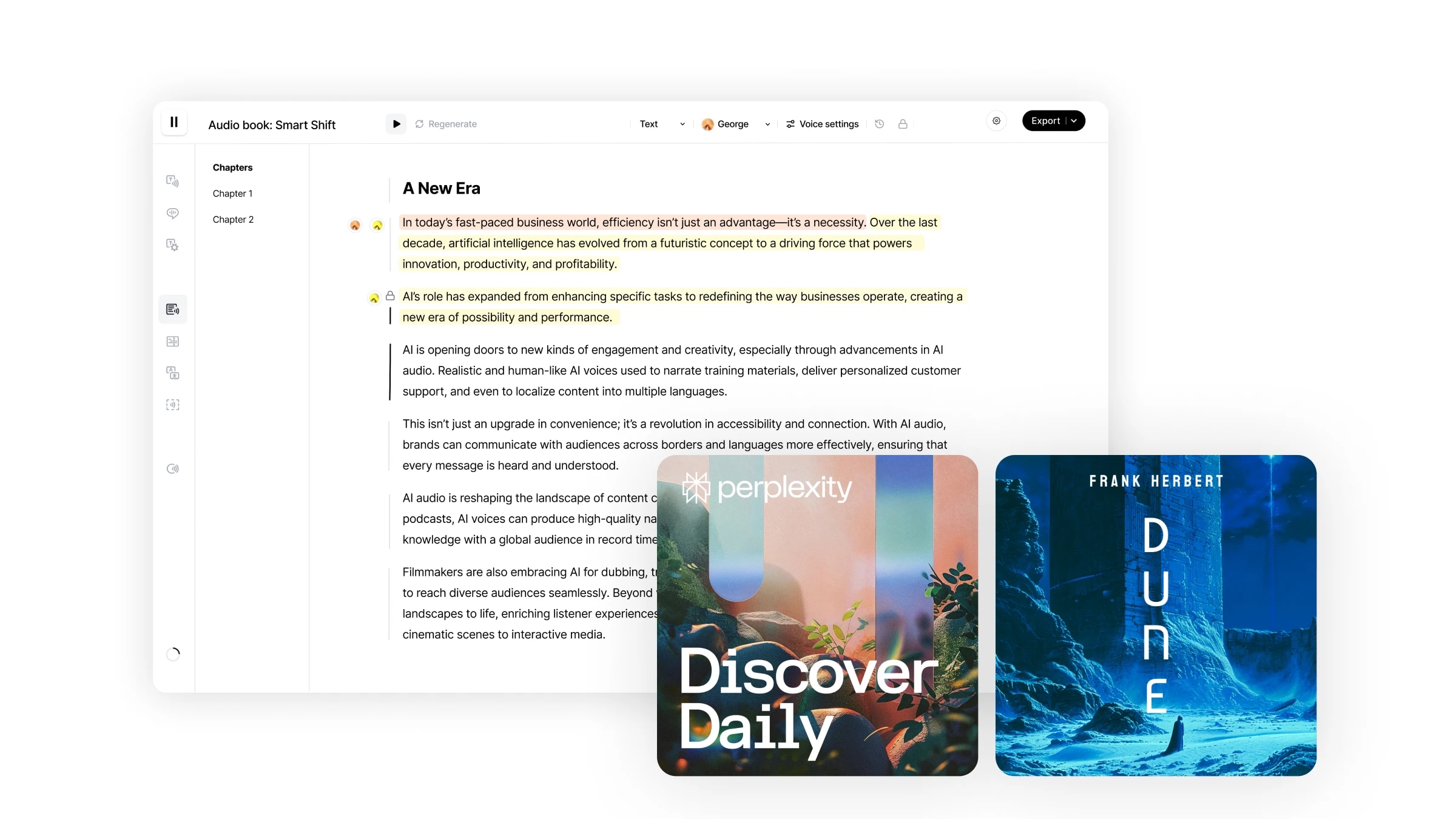
Studio est notre flux de travail de bout en bout pour créer des livres audio en quelques minutes. Il offre un niveau de contrôle sans précédent sur vos créations audio avec la possibilité de régénérer des morceaux audio spécifiques, d'assigner différents locuteurs à des fragments de texte particuliers, d'importer directement des fichiers de plusieurs formats, et plus encore.
Naviguer dans Studio est facile et intuitif.
Studio offre une expérience utilisateur simple, semblable à l'utilisation de Google Docs, avec une interface intuitive centrée sur l'utilisateur supportant une variété de fonctionnalités d'édition :
Votre flux de travail complet pour éditer des vidéos et des audios, ajouter des voix off et de la musique, transcrire en texte et publier des productions narrées et sous-titrées
Studio se tient aux côtés de Synthèse vocale, VoiceLab, et Voice Library, servant de solution complète pour la synthèse audio long format. De plus, il est parfaitement intégré avec Professional Voice Cloning, Voice Library, et notre modèle multilingue.
Chez ElevenLabs, notre engagement envers l'innovation a conduit au lancement d'un nouveau modèle multilingue. Cela permet de traduire et vocaliser le même récit en jusqu'à 28 langues. Pour les éditeurs, cela signifie une portée mondiale sans précédent, avec des histoires résonnant à travers différentes cultures et régions, le tout dans une voix cohérente et unifiée.
Les langues supportées incluent désormais : Anglais, Coréen, Néerlandais, Chinois, Turc, Suédois, Indonésien, Philippin, Japonais, Ukrainien, Grec, Tchèque, Finnois, Roumain, Danois, Bulgare, Malais, Slovaque, Croate, Arabe classique, Polonais, Allemand, Espagnol, Français, Italien, Hindi, Portugais et Tamoul.
Notre outil propriétaire Voice Design offre une expérience transformative pour les éditeurs. Il facilite la création de voix complètement uniques basées sur des paramètres sélectionnés, tels que l'âge, le sexe et l'accent. Chaque voix générée est unique, garantissant que les éditeurs peuvent choisir une voix particulière pour devenir synonyme de leur marque ou publication.
Clonage vocal professionnel (PVC) chez ElevenLabs offre une autre couche de personnalisation. En clonant les voix des reporters d'une publication, nous pouvons produire des histoires audio dans leurs tons uniques. Cela offre non seulement de l'authenticité mais réduit également considérablement les coûts et le temps consacrés aux processus d'enregistrement traditionnels. De plus, notre modèle multilingue est compatible avec le clonage vocal professionnel, garantissant qu'une voix de reporter peut désormais parler toutes les langues supportées.

Utilisez votre voix pour vos doublages vidéo, voix off, lecture d'articles, podcasts ou livres audio.
Écoutez un épisode de podcast généré avec notre outil de clonage vocal professionnel :
Pour les éditeurs, le clonage vocal professionnel (PVC) offre de nombreux avantages :
Combinée à la technologie Text to Voice, les éditeurs disposent d'un ensemble d'outils de pointe pour produire un contenu auditif riche, varié et mondial. Adopter les capacités de la technologie de clonage vocal professionnel est une démarche progressive pour les éditeurs, ouvrant une myriade d'opportunités.
L'avenir de l'édition ne réside pas seulement dans le mot écrit mais dans la manière dont ces mots sont transmis. Avec des outils comme Text to Voice, les éditeurs ont le potentiel de révolutionner leur diffusion de contenu, garantissant accessibilité, unicité et portée mondiale. Chez ElevenLabs, nous sommes à l'avant-garde de cette transformation, offrant une technologie qui ouvre la voie à une expérience auditive plus riche et diversifiée.
Mise à jour : à partir de janvier 2025, Projects s'appelle désormais Studio et est disponible pour tous les utilisateurs gratuits.

Demand for digital tour guides rises with 10k+ tours taken and an average of 53 minutes listening time per session

Supporting 10,000+ research conversations with natural, trustworthy voices
Propulsé par ElevenLabs Agents