Multi-voice support
Multi-voice support
Enable your AI agent to switch between different voices for multi-character conversations and enhanced storytelling.
Multi-voice support
Enable your AI agent to switch between different voices for multi-character conversations and enhanced storytelling.
Multi-voice support allows your ElevenLabs agent to dynamically switch between different ElevenLabs voices during a single conversation. This powerful feature enables:
When multi-voice support is enabled, your agent can use XML-style markup to switch between configured voices during text generation. The agent automatically returns to the default voice when no specific voice is specified.
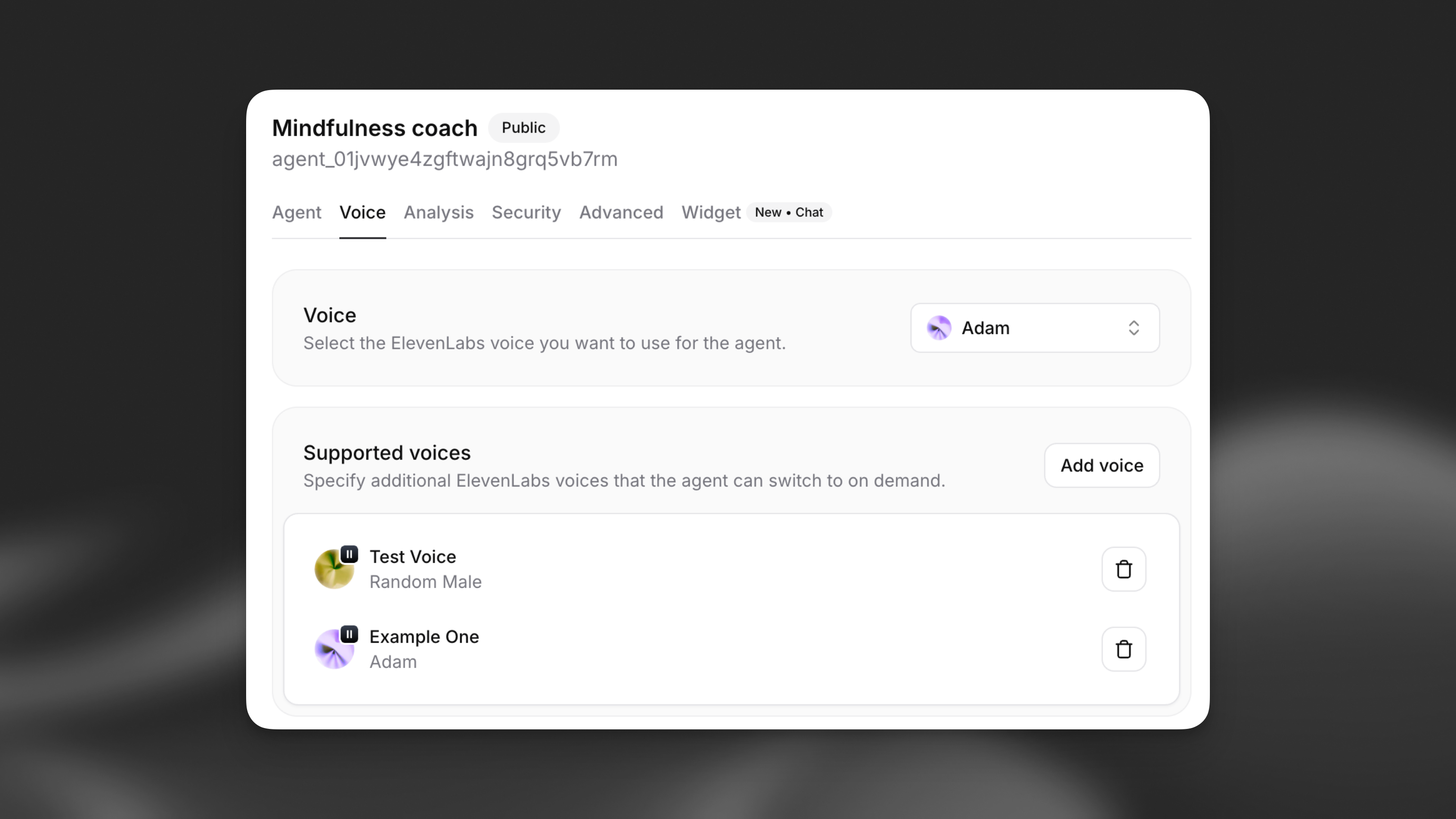
Each supported voice has the following properties:
Open your agent in the dashboard, navigate to the Voice tab, and locate the Multi-voice support section. Click Add voice to configure a new supported voice.
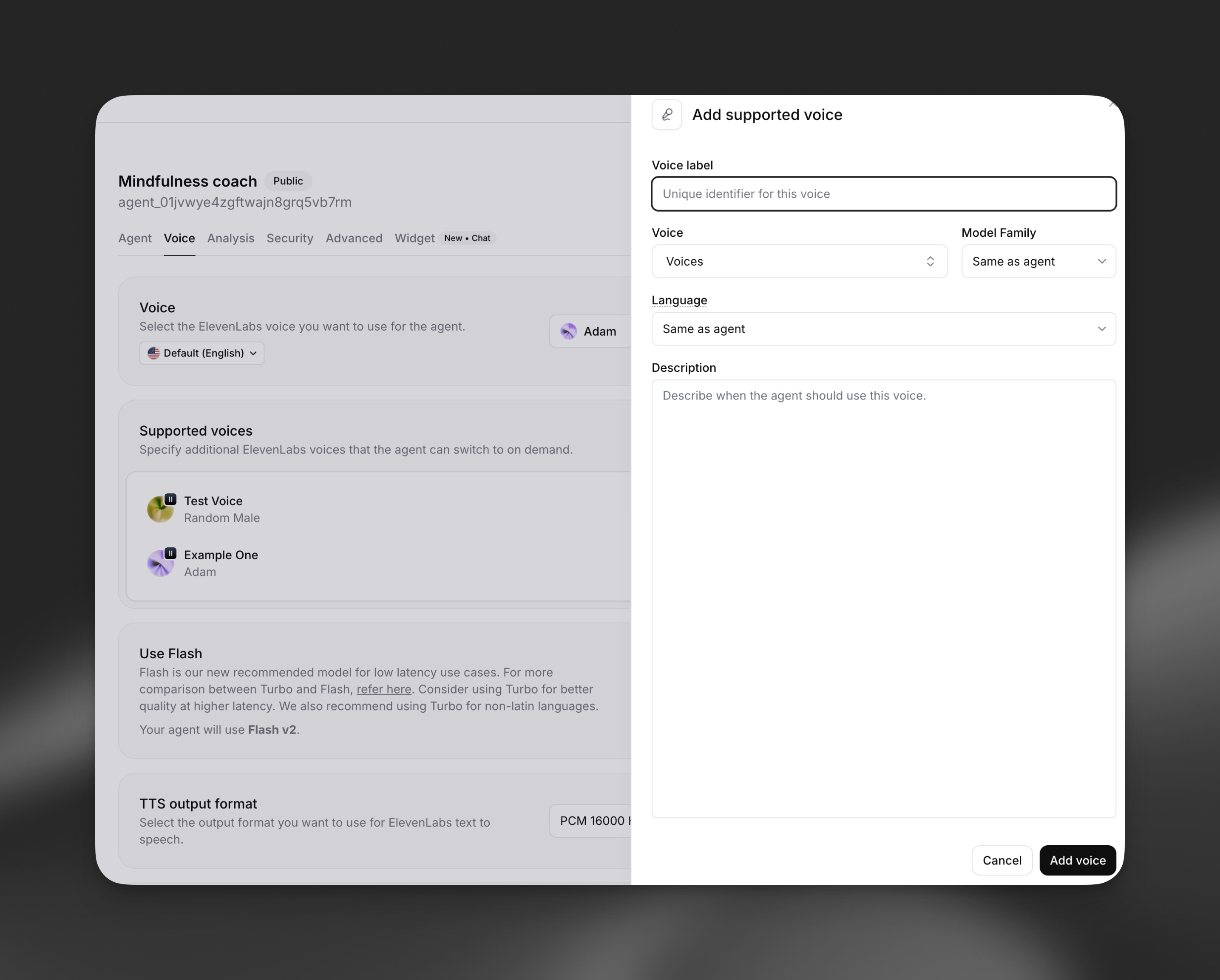
A unique identifier that the LLM uses to reference this voice. Choose descriptive labels like: - Character names: “Alice”, “Bob”, “Narrator” - Languages: “Spanish”, “French”, “German” - Emotions: “Happy”, “Sad”, “Excited” - Roles: “Teacher”, “Student”, “Guide”
Override the agent’s default model family for this specific voice: - Flash: Fastest eneration, optimized for real-time use - Turbo: Balanced speed and quality - Multilingual: Highest quality, best for non-English languages - Same as agent: Use agent’s default setting
Specify a different language for this voice, useful for: - Multilingual conversations - Language tutoring applications - Region-specific pronunciations
Provide context for when the agent should use this voice. Examples:
Your agent uses XML-style tags to switch between voices:
Key points:
VOICE_LABEL with the exact label you configuredWhen you configure supported voices, the system automatically adds instructions to your agent’s prompt:
If the agent uses a voice label that hasn’t been configured, the text will be spoken using the default voice. The XML tags will be ignored.
Yes, you can switch voices within a single response. Each tagged section will use the specified voice, while untagged text uses the default voice.
Voice switching adds minimal overhead. The first use of each voice in a conversation may have slightly higher latency as the voice is initialized.
Yes, you can configure multiple labels that use the same ElevenLabs voice but with different model families, languages, or contexts.
Provide clear examples in your system prompt and test thoroughly. You can include specific scenarios where voice switching should occur and examples of the XML markup format.