Success Evaluation
Define custom criteria to assess conversation quality, goal achievement, and customer satisfaction.
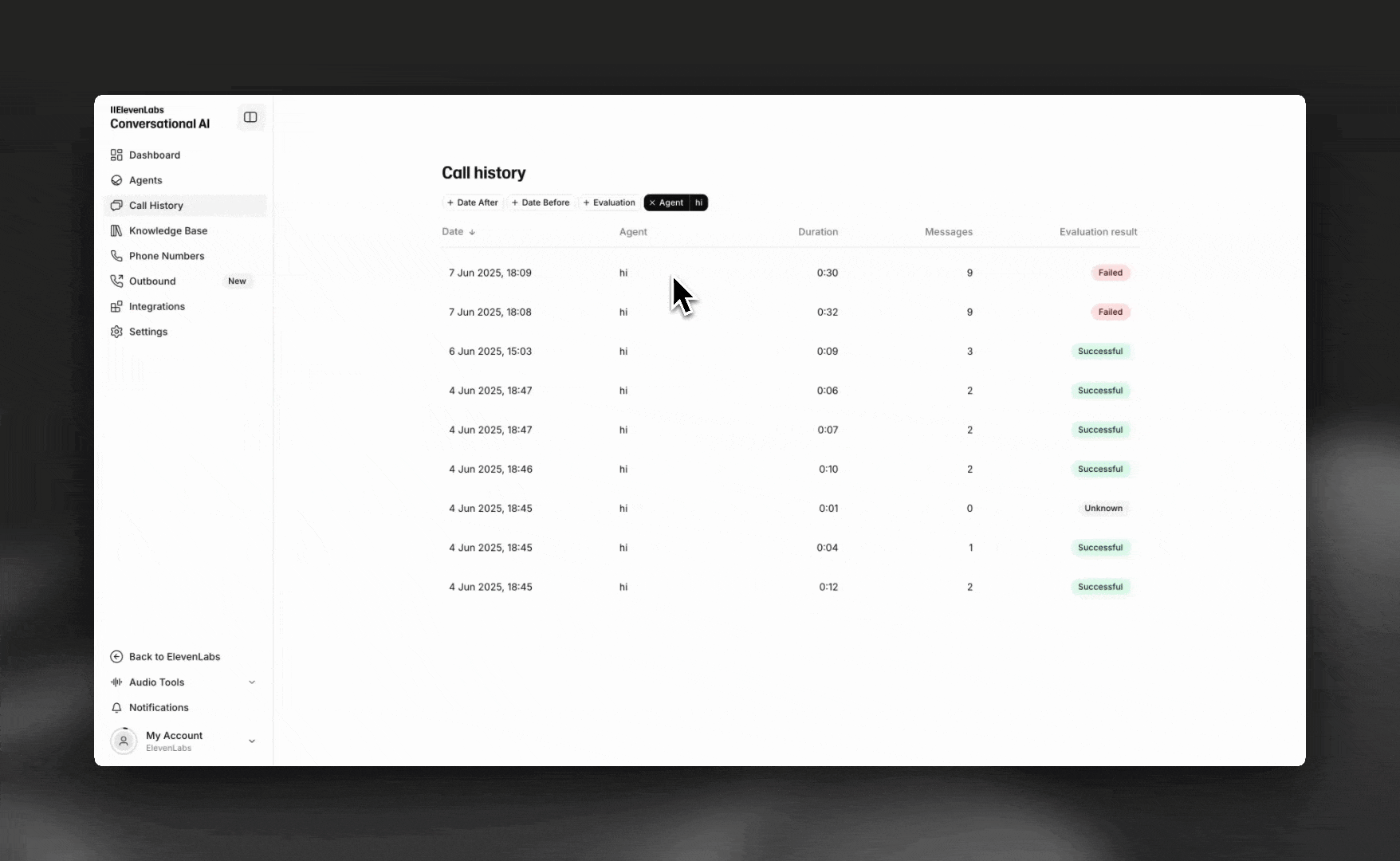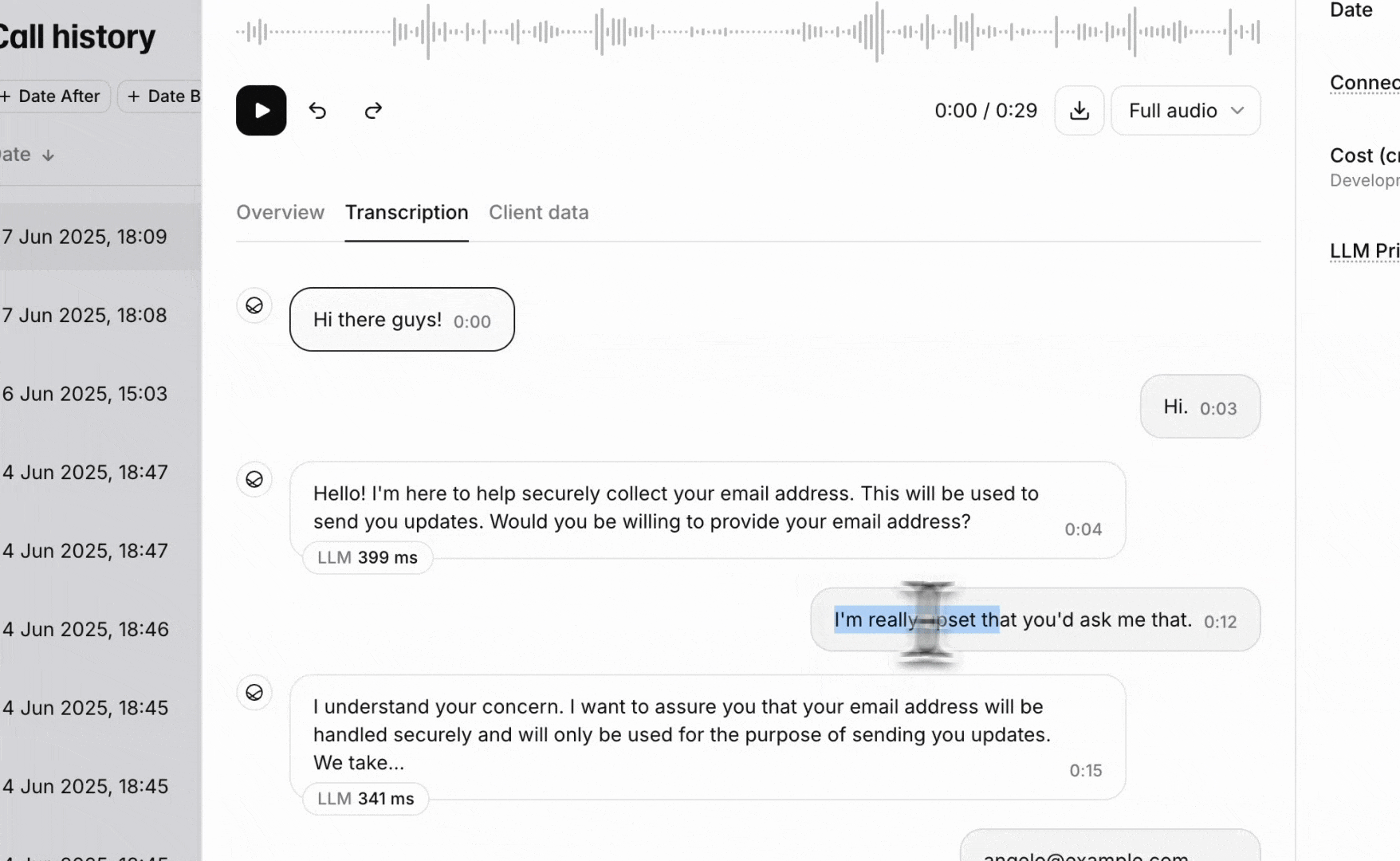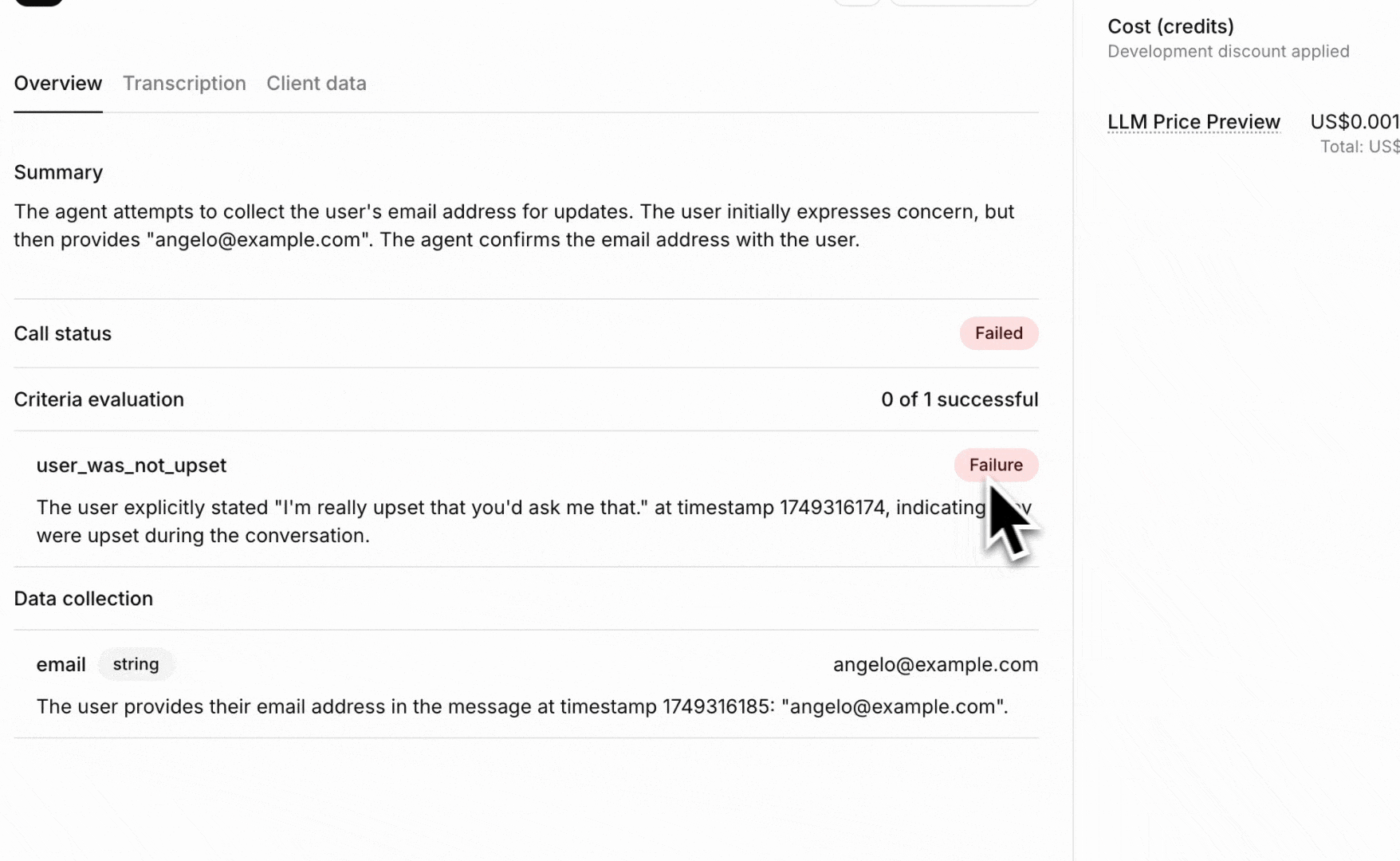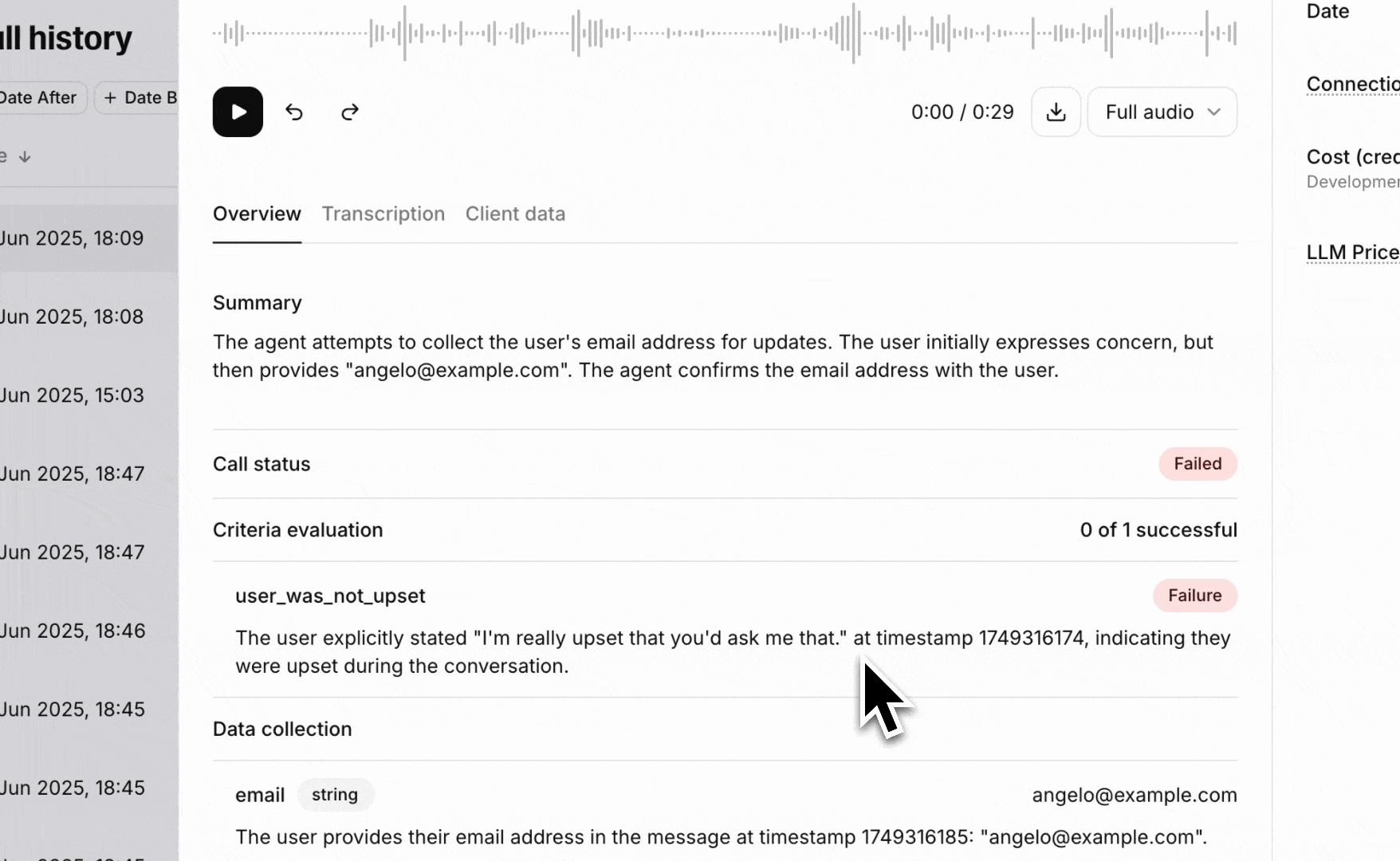
Success evaluation allows you to define custom goals and success metrics for your conversations. Each criterion is evaluated against the conversation transcript and returns a result of success, failure, or unknown, along with a detailed rationale.
Success evaluation uses LLM-powered analysis to assess conversation quality against your specific business objectives. This enables systematic performance measurement and quality assurance across all customer interactions.
Each evaluation criterion analyzes the conversation transcript using a custom prompt and returns:
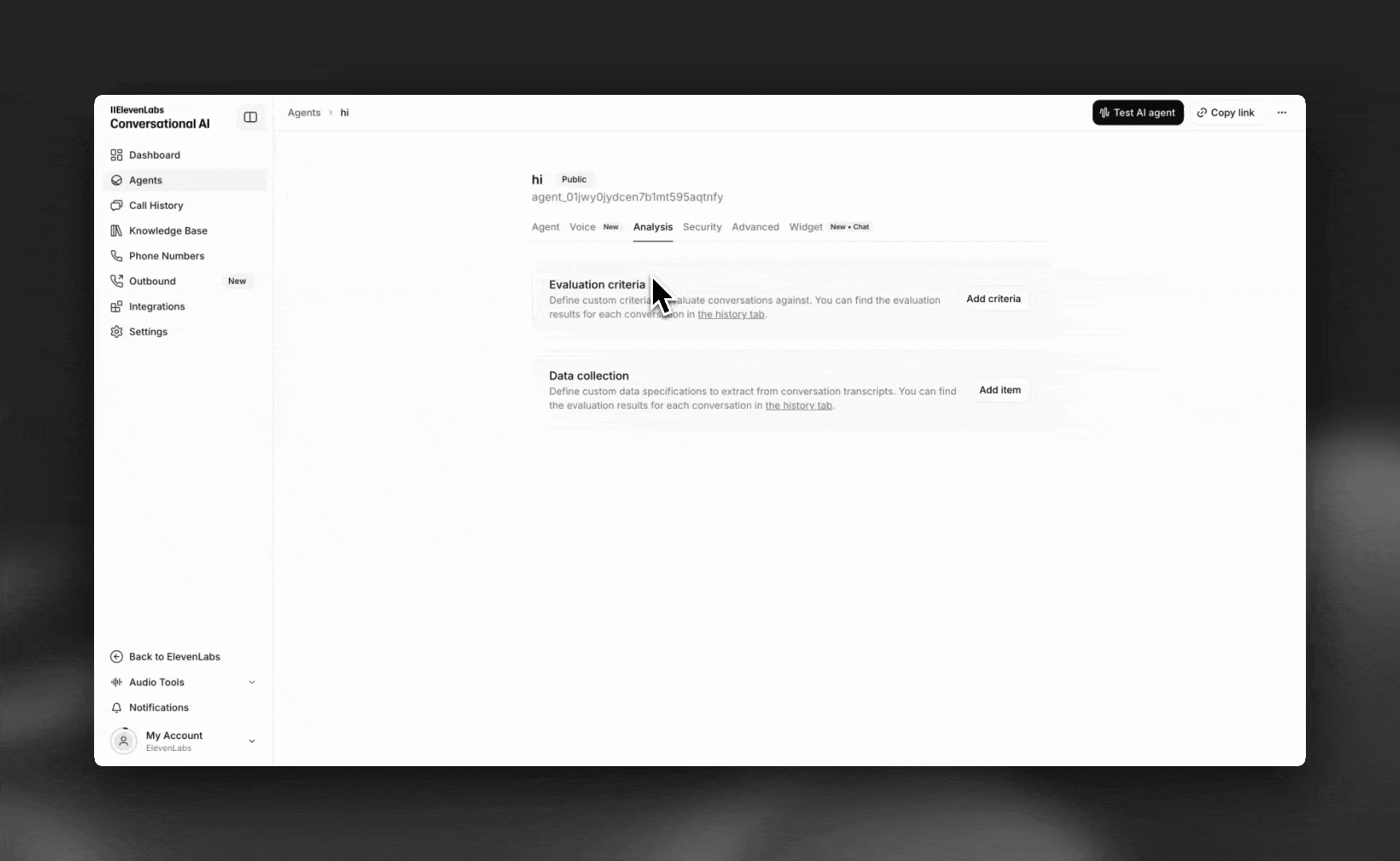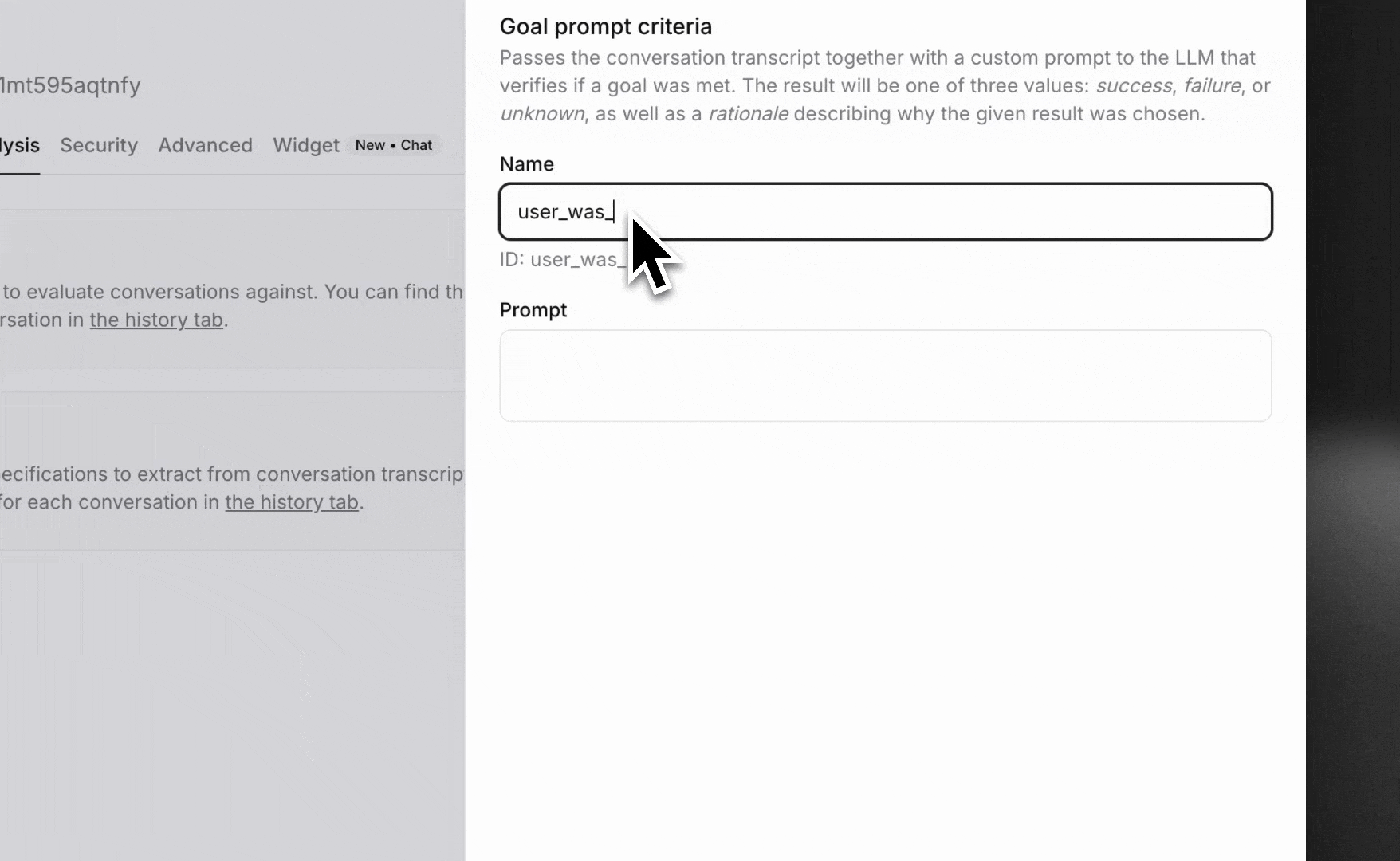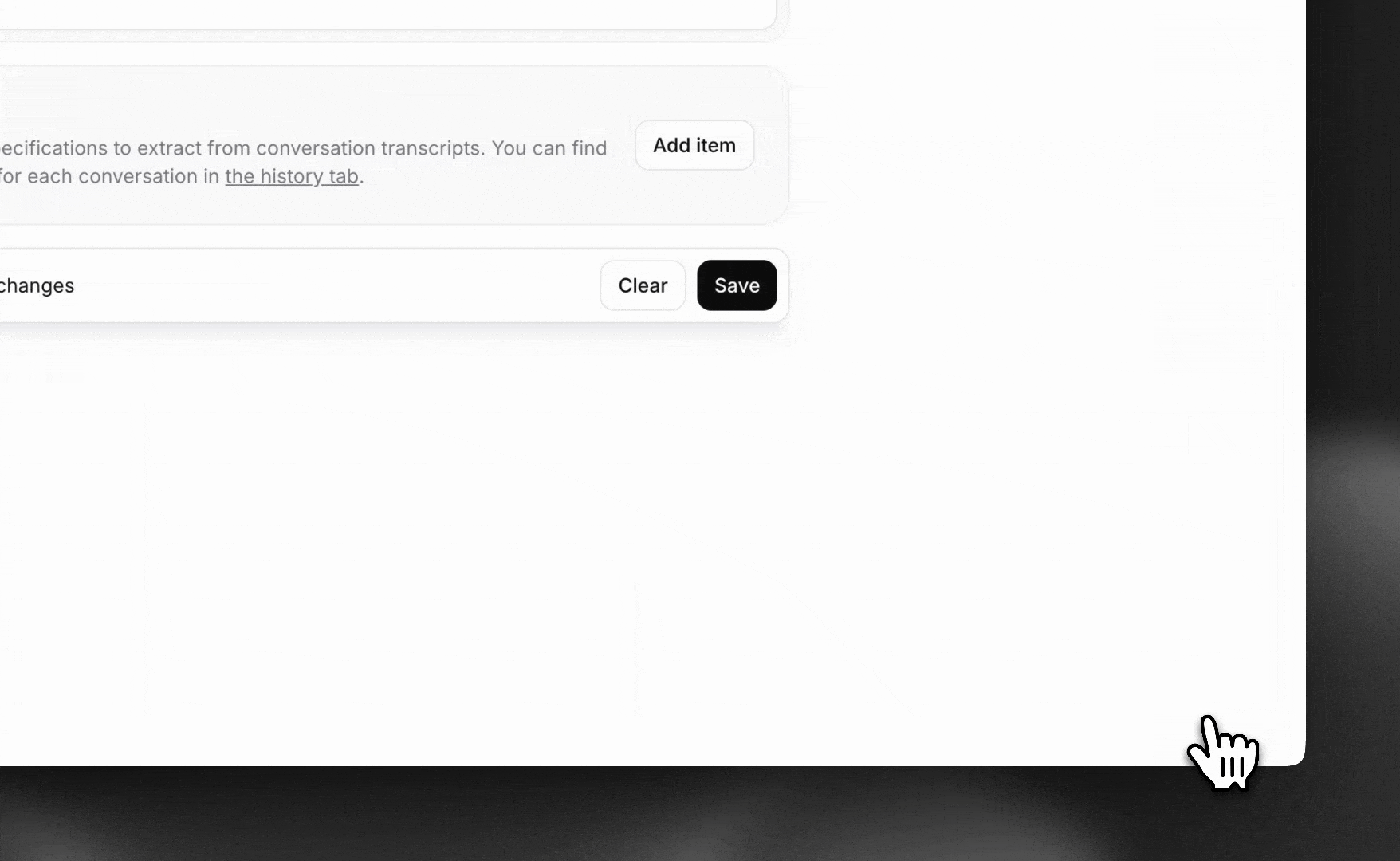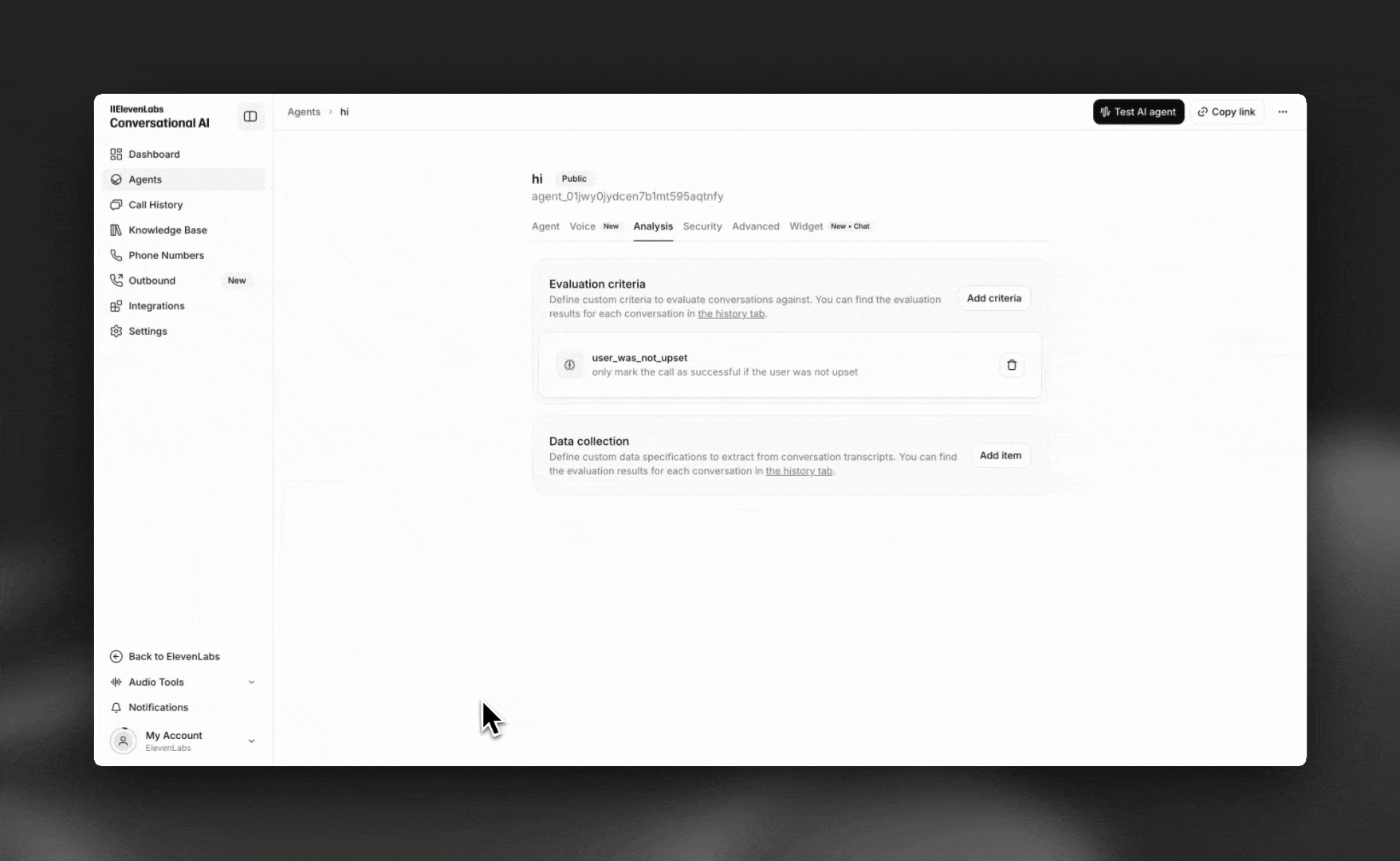
success, failure, or unknownGoal prompt criteria pass the conversation transcript along with a custom prompt to an LLM to verify if a specific goal was met. This is the most flexible type of evaluation and can be used for complex business logic.
Examples:
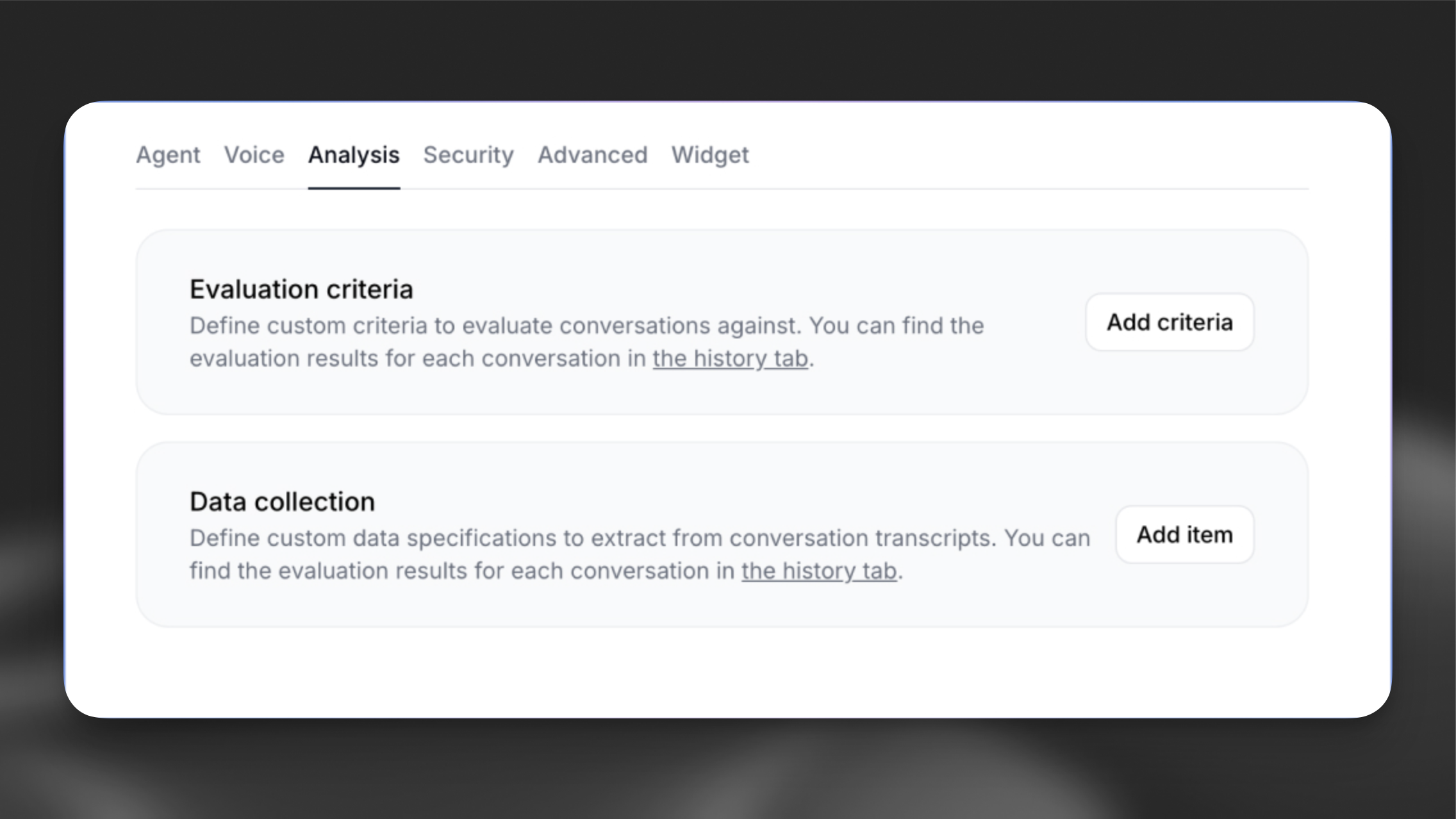
Navigate to your agent’s dashboard and select the Analysis tab to configure evaluation criteria.
The unknown result is returned when the LLM cannot determine success or failure from the transcript. This often happens with:
Monitor unknown results to identify areas where your criteria prompts may need refinement.
Measure issue resolution rates, customer satisfaction, and support quality metrics to improve service delivery.
Track goal achievement, objection handling, and conversion rates across sales conversations.
Ensure agents follow required procedures and capture necessary consent or disclosure confirmations.
Identify coaching opportunities and measure improvement in agent performance over time.
Success evaluation results are available through Post-call Webhooks for integration with external systems and analytics platforms.