Data collection
Data collection automatically extracts structured information from conversation transcripts using LLM-powered analysis. This enables you to capture valuable data points without manual processing, improving operational efficiency and data accuracy.
Overview
Data collection analyzes conversation transcripts to identify and extract specific information you define. The extracted data is structured according to your specifications and made available for downstream processing and analysis.
Supported data types
Data collection supports four data types to handle various information formats:
- String: Text-based information (names, emails, addresses)
- Boolean: True/false values (agreement status, eligibility)
- Integer: Whole numbers (quantity, age, ratings)
- Number: Decimal numbers (prices, percentages, measurements)
Configuration
Access data collection settings
In the Analysis tab of your agent settings, navigate to the Data collection section.
Add data collection items
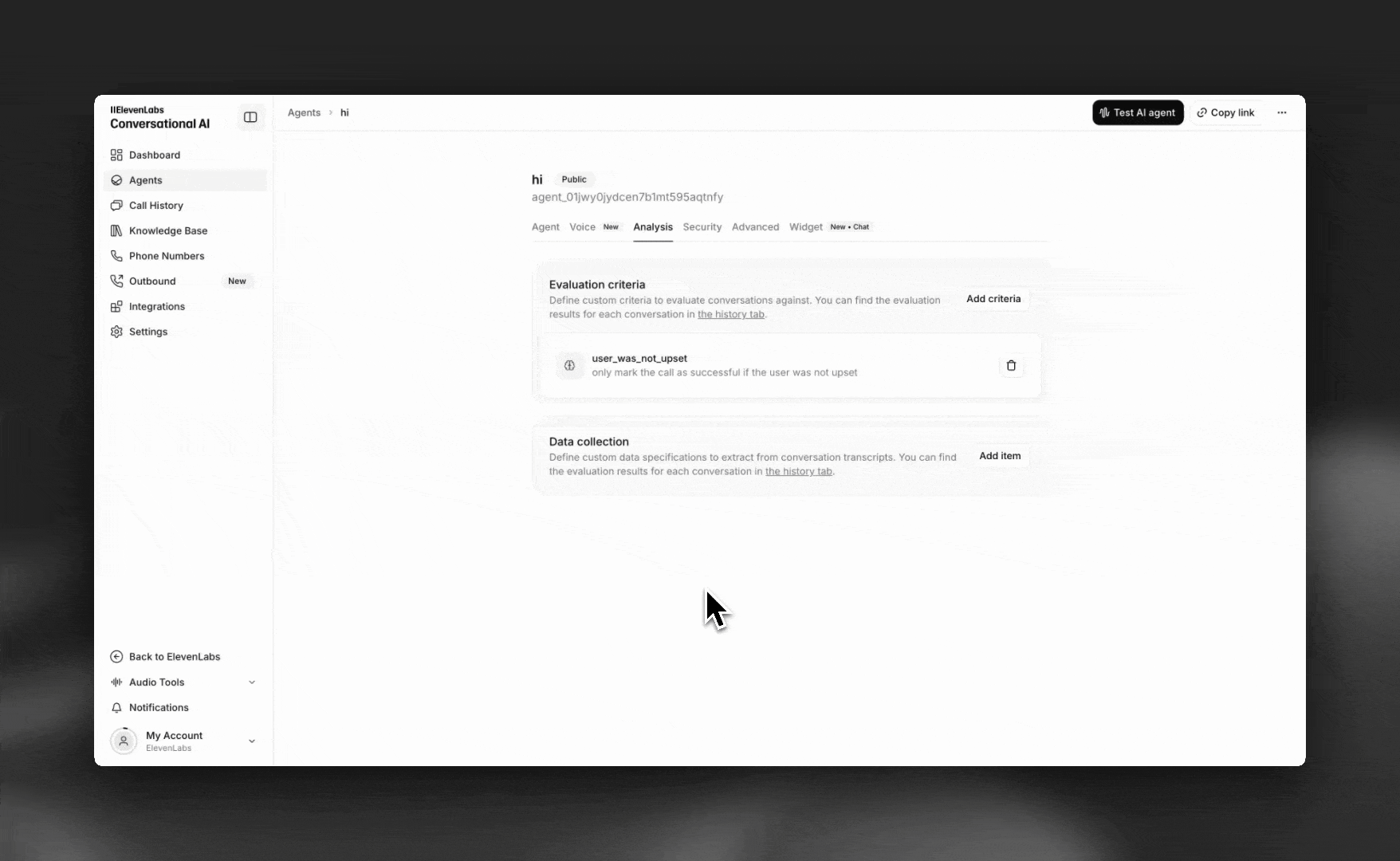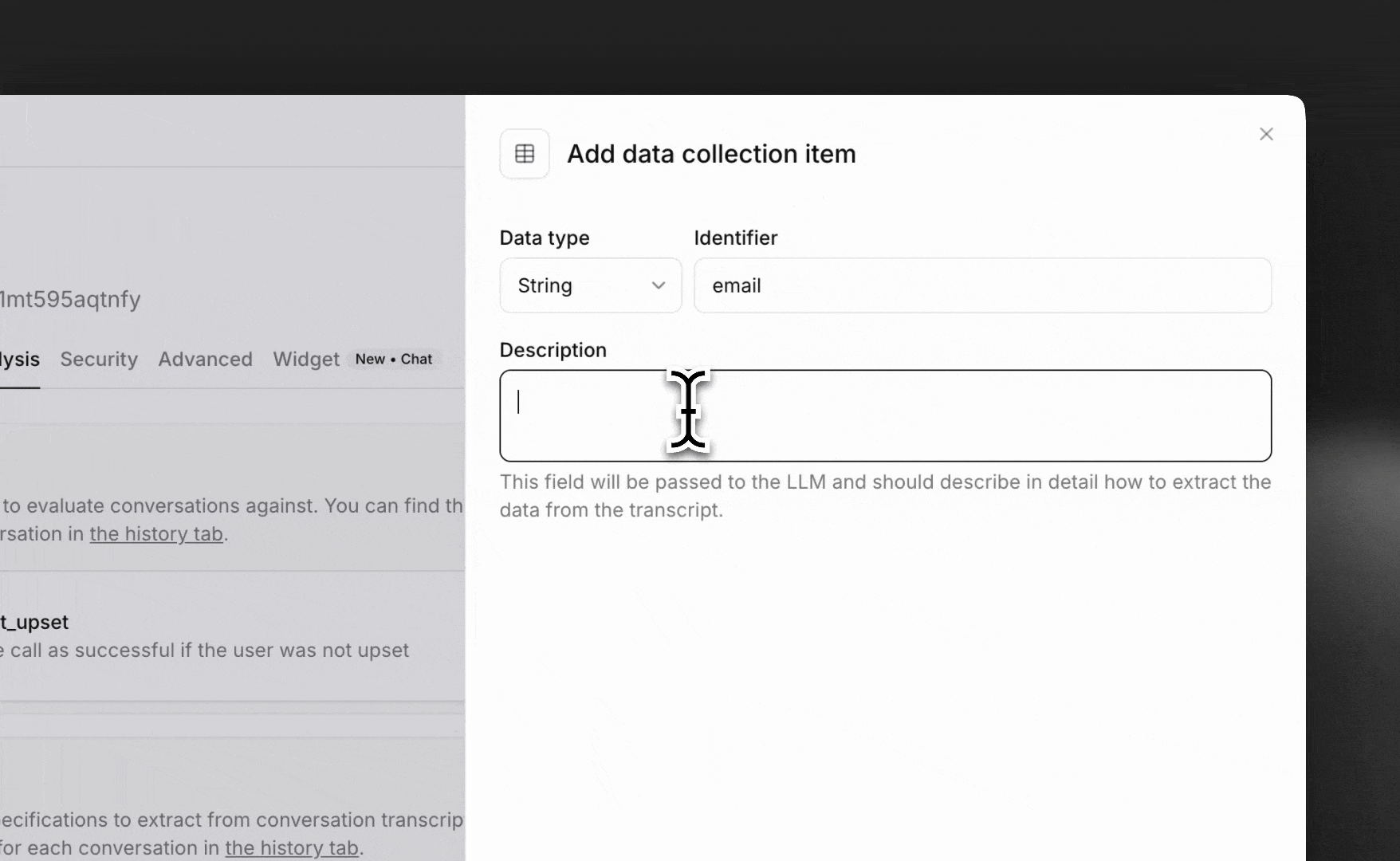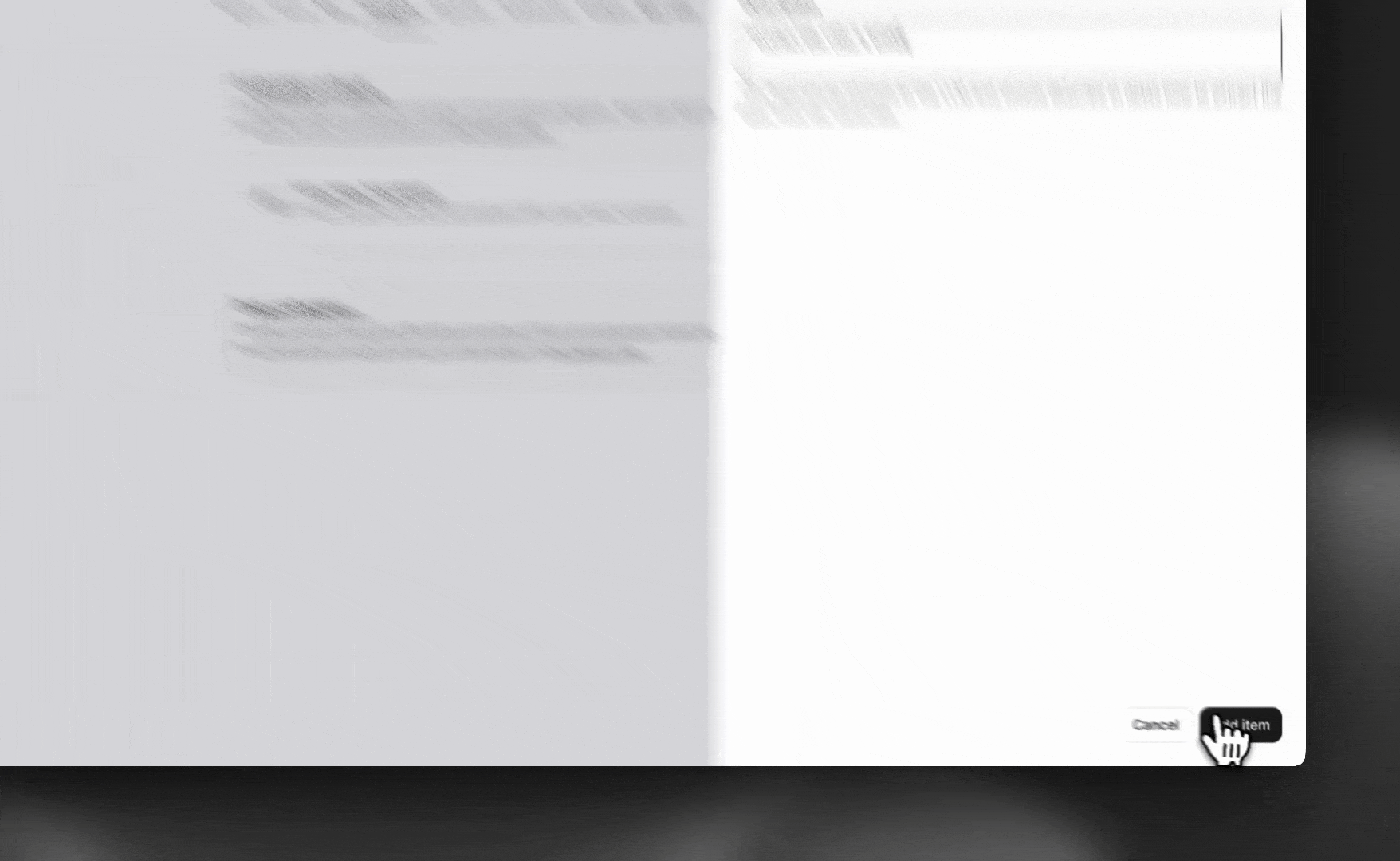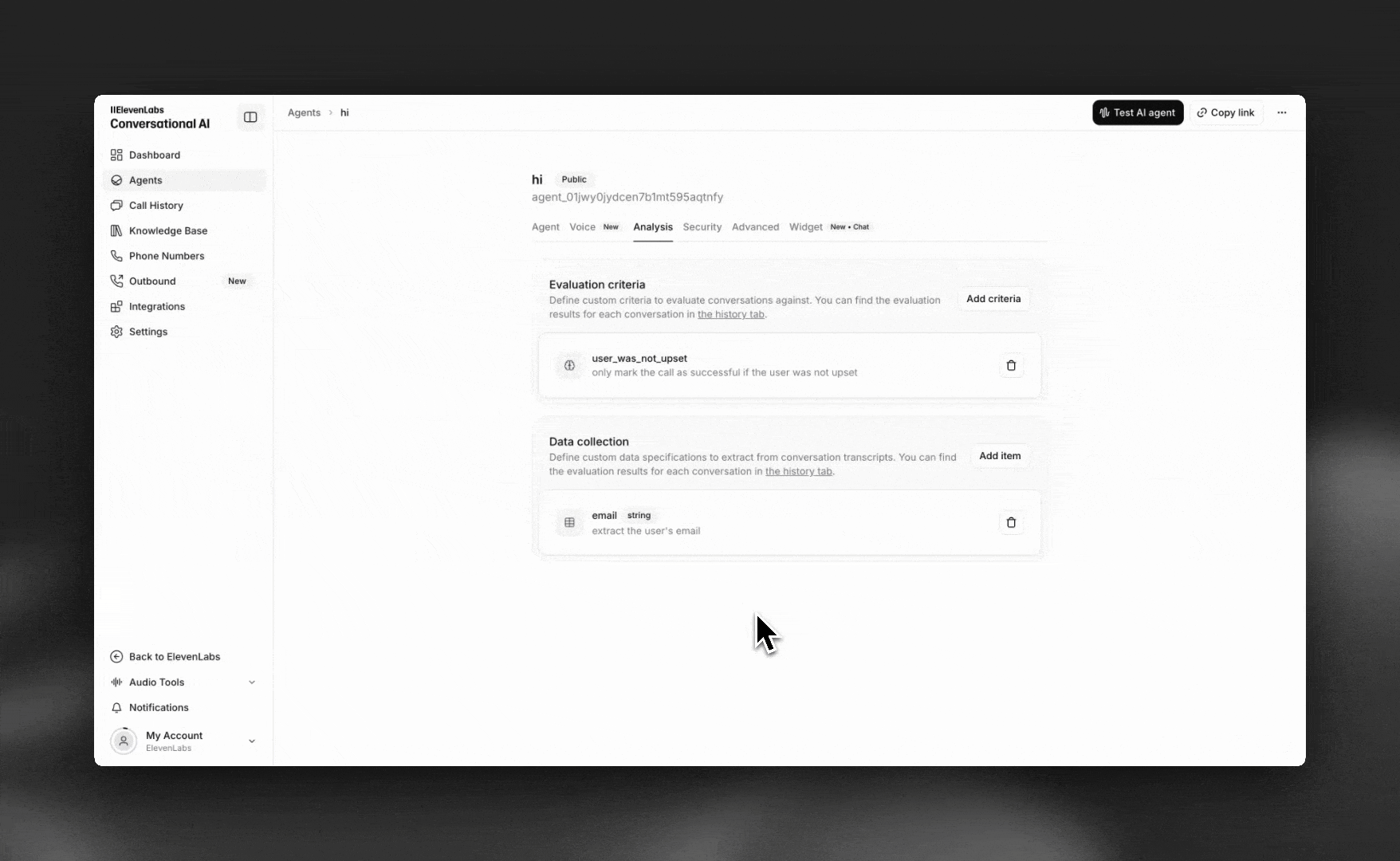
Click Add item to create a new data extraction rule.
Configure each item with:
- Identifier: Unique name for the data field (e.g.,
email,customer_rating) - Data type: Select from string, boolean, integer, or number
- Description: Detailed instructions on how to extract the data from the transcript
The description field is passed to the LLM and should be as specific as possible about what to extract and how to format it.
Data collection items are limited to 40 per agent for Trial and Enterprise plans, and 25 per agent for other plans.
Best Practices
Writing effective extraction prompts
- Be explicit about the expected format (e.g., “email address in the format user@domain.com”)
- Specify what to do when information is missing or unclear
- Include examples of valid and invalid data
- Mention any validation requirements
Common data collection examples
Contact Information:
email: “Extract the customer’s email address in standard format (user@domain.com)”phone_number: “Extract the customer’s phone number including area code”full_name: “Extract the customer’s complete name as provided”
Business Data:
issue_category: “Classify the customer’s issue into one of: technical, billing, account, or general”satisfaction_rating: “Extract any numerical satisfaction rating given by the customer (1-10 scale)”order_number: “Extract any order or reference number mentioned by the customer”
Behavioral Data:
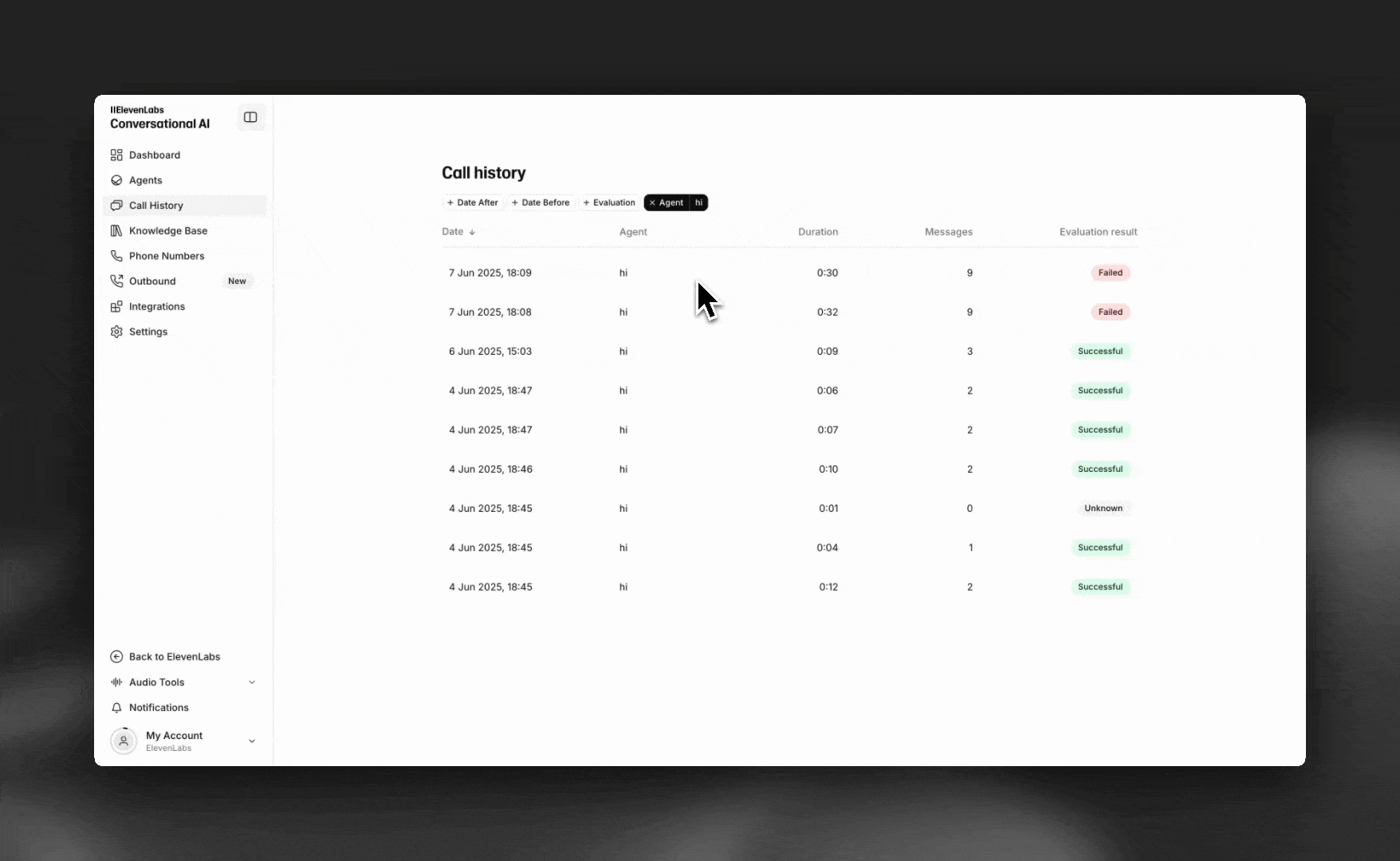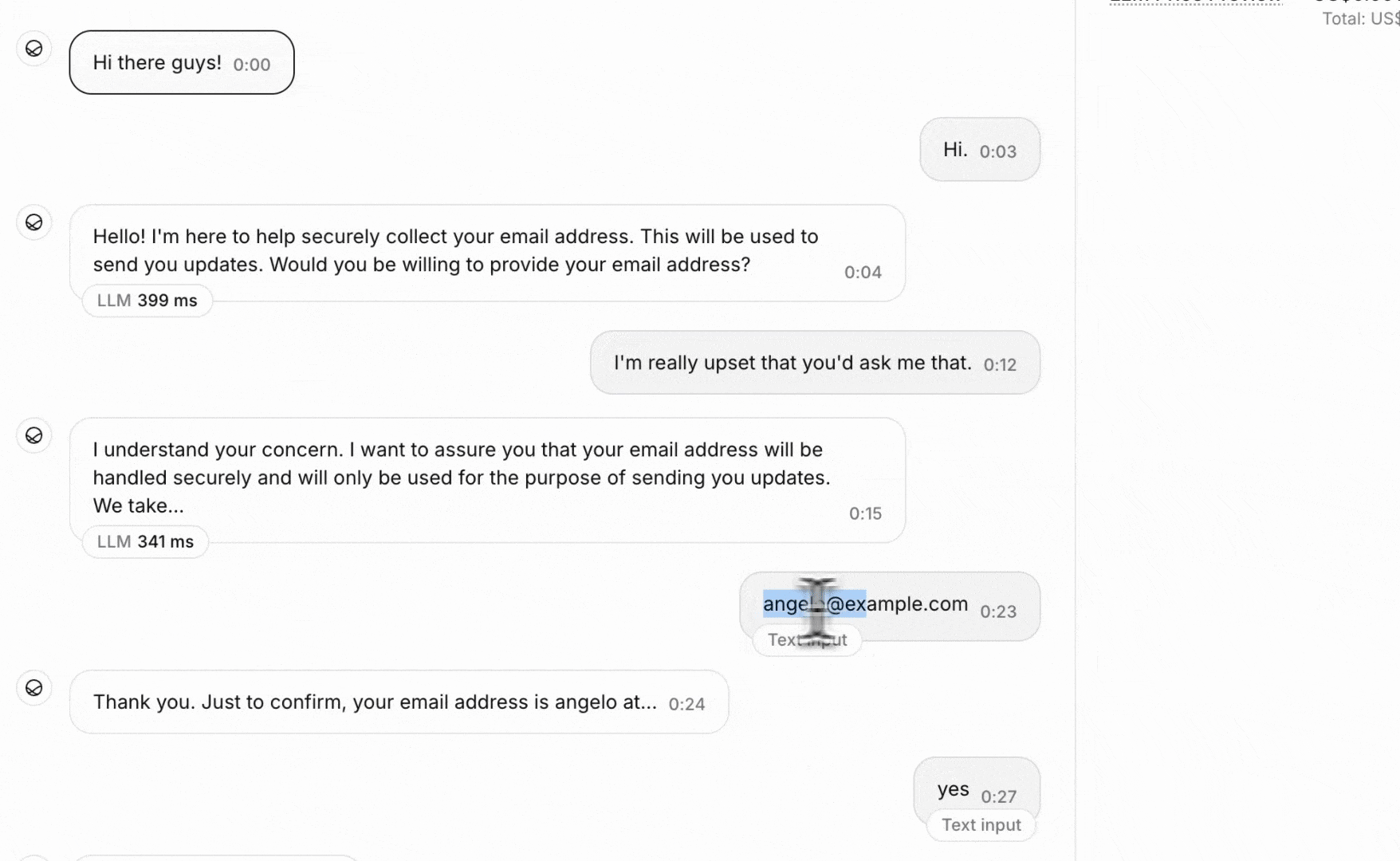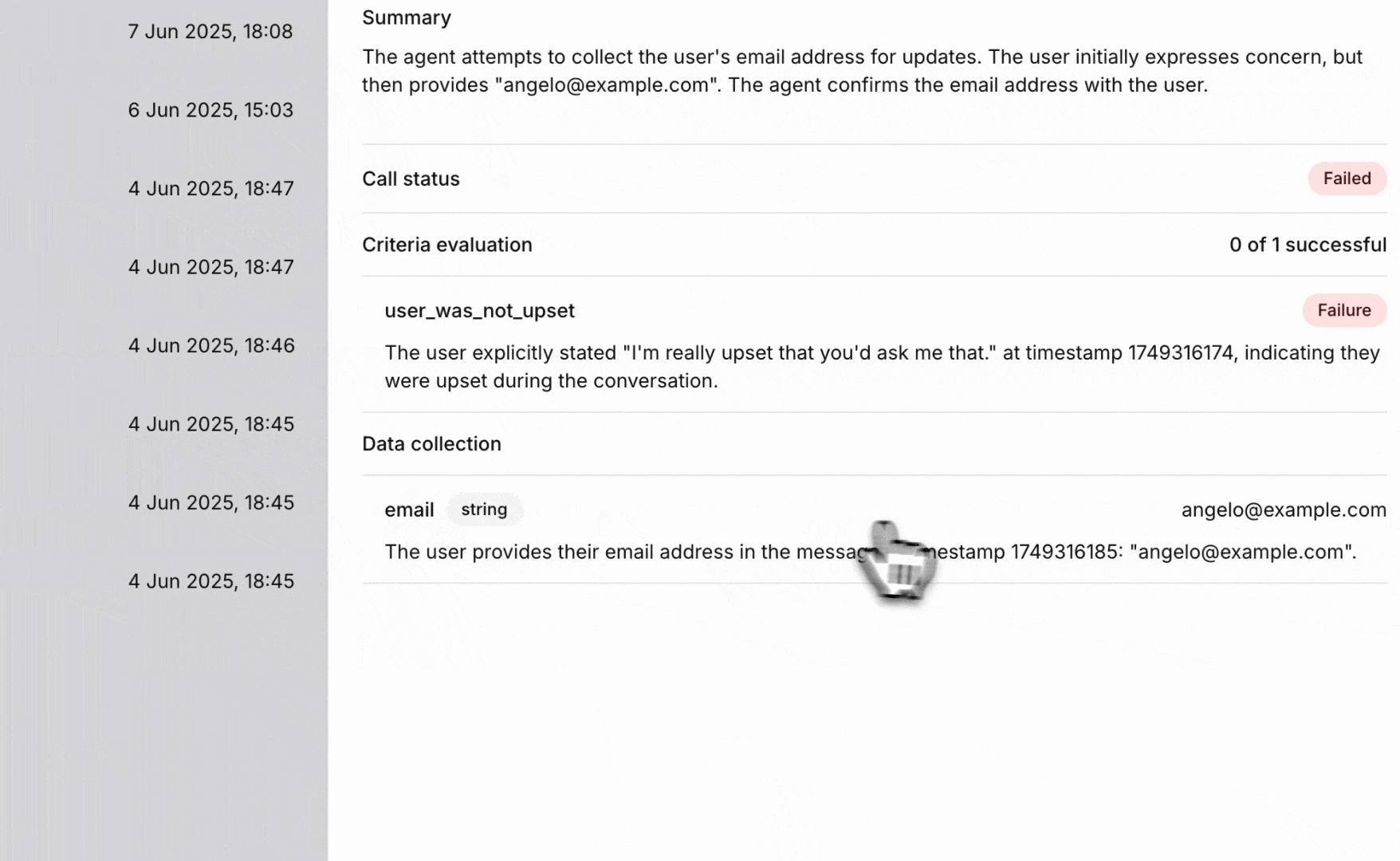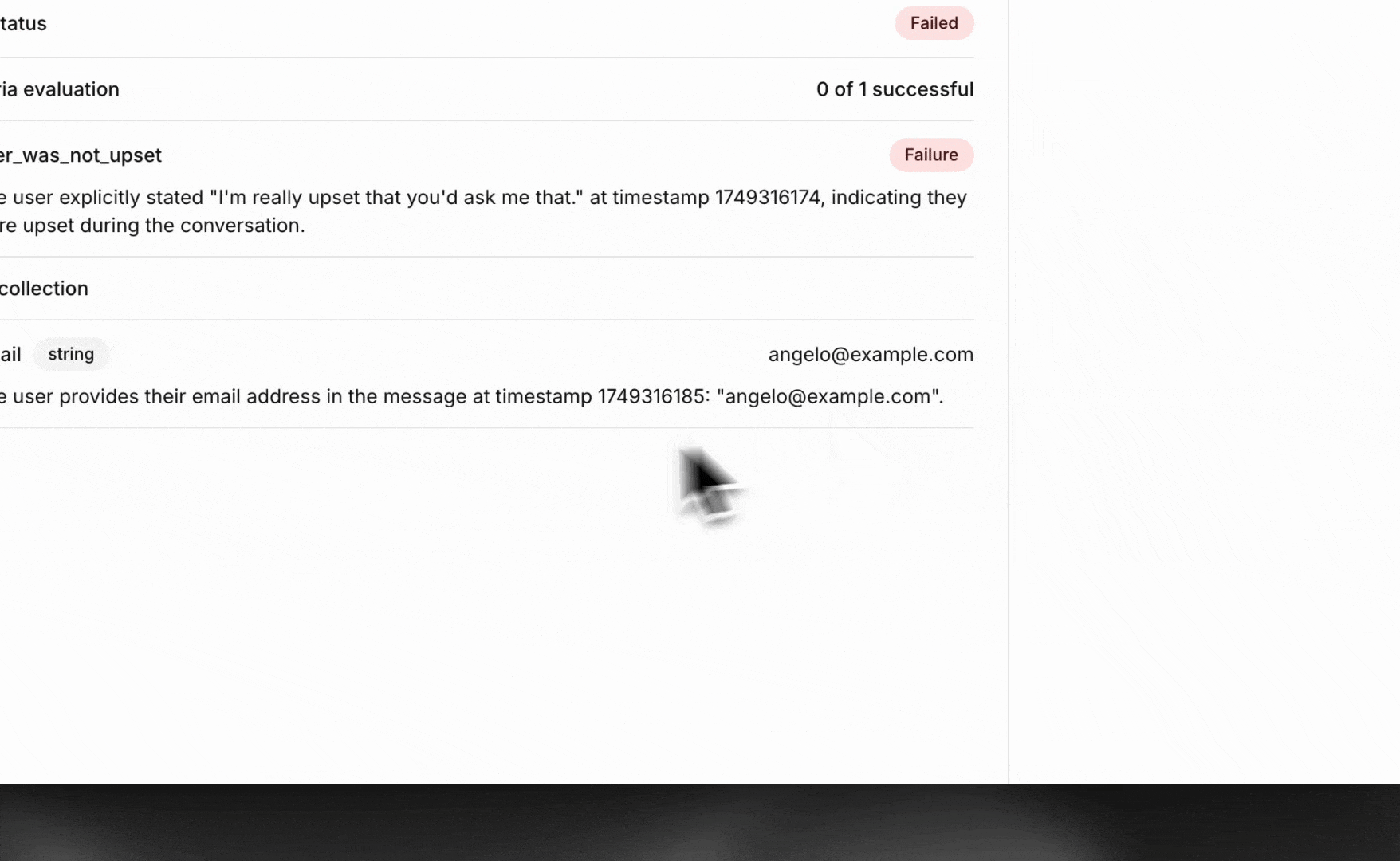
was_angry: “Determine if the customer expressed anger or frustration during the call”requested_callback: “Determine if the customer requested a callback or follow-up”
Handling missing or unclear data
When the requested data cannot be found or is ambiguous in the transcript, the extraction will return null or empty values. Consider:
- Using conditional logic in your applications to handle missing data
- Creating fallback criteria for incomplete extractions
- Training agents to consistently gather required information
Data Type Guidelines
String
Boolean
Integer
Number
Use for text-based information that doesn’t fit other types.
Examples:
- Customer names
- Email addresses
- Product categories
- Issue descriptions
Best practices:
- Specify expected format when relevant
- Include validation requirements
- Consider standardization needs
Use Cases
Extract contact information, qualification criteria, and interest levels from sales conversations.
Gather structured data about customer preferences, feedback, and behavior patterns for strategic insights.
Capture issue categories, resolution details, and satisfaction scores for operational improvements.
Extract required disclosures, consents, and regulatory information for audit trails.
Troubleshooting
Data extraction returning empty values
- Verify the data exists in the conversation transcript
- Check if your extraction prompt is specific enough
- Ensure the data type matches the expected format
- Consider if the information was communicated clearly during the conversation
Inconsistent data formats
- Review extraction prompts for format specifications
- Add validation requirements to prompts
- Consider post-processing for data standardization
- Test with various conversation scenarios
Performance considerations
- Each data collection rule adds processing time
- Complex extraction logic may take longer to evaluate
- Monitor extraction accuracy vs. speed requirements
- Optimize prompts for efficiency when possible
Extracted data is available through Post-call Webhooks for integration with CRM systems, databases, and analytics platforms.