
Profitieren Sie mit minimalem Programmieraufwand und durch einfache Einbindung von der geringen Latenz unserer Text-to-Speech-API und werten Sie Ihre Anwendungen durch klare, qualitativ hochwertige Sprachinhalte auf
Einführung von Eleven v3 Alpha
v3 ausprobierenExperience dynamic conversations, emotional nuance, and rich delivery like never before. With Eleven v3, you can: - Direct tone and timing using in-line audio tags - Generate natural dialogue between multiple speakers - Localize at scale with human-like speech in 70+ languages From stadium chants to comedic timing, expressive storytelling to chaotic group banter — v3 makes voice creation fully controllable, deeply human, and unmistakably real.
Unsere KI-Stimmen erkennen emotionale Hinweise im Text und passen Tonfall und Betonung an Inhalt und Kontext an. So klingen sie natürlicher, vermeiden logische Fehler und transportieren Bedeutung präzise.
Finden Sie die passende Stimme für jedes Projekt: Greifen Sie auf tausende Stimmen in unserer Voice Library zu oder erstellen Sie mit Voice Design individuelle KI-Stimmen. Alter, Akzent und Stimmcharakter lassen sich präzise an Ihre Produktionsanforderungen anpassen – für maximale Kontrolle über Tonalität und Ausdruck.
Mit der ElevenReader-App können Sie sich Artikel, PDFs, ePubs, Newsletter und mehr vorlesen lassen. Wählen Sie eine Stimme aus der Voice Library, laden Sie Ihre Inhalte hoch – und hören Sie sie direkt auf dem Smartphone.
Erstellen Sie professionelle Voiceovers für Social Media, Werbung, Film und mehr – direkt in unserem Voiceover-Studio. Wählen Sie eine Stimme, laden Sie Ihr Skript hoch und passen Sie Timing, Sprecherrollen und Soundeffekte präzise an.
Alle unsere KI-Stimmen können über 70 Sprachen sprechen. Nutzen Sie unsere mehrsprachigen Text-to-Speech-Modelle, um internationale Zielgruppen zu erreichen, Sprachbarrieren zu überwinden und Chancen in neuen Märkten zu erschließen.
Whether it's American, British, Australian, Indian, Nigerian, or dozens more, our technology is designed to understand and generate speech that reflects the way people speak. We're constantly expanding our accent support to ensure voices feel natural, nuanced, and truly human.

Unser lebensechtestes und emotional stärkstes Modell – verfügbar in 29 Sprachen. Ideal für Voiceovers, Hörbücher, Postproduktion und Content-Erstellung.

Unser ausschließlich englischsprachiges Modell mit niedriger Latenz. Ideal für Entwickler und einsprachige Anwendungsfälle, bei denen Geschwindigkeit entscheidend ist. Die Leistung entspricht dem Turbo v2.5-Modell.

Unser hochwertiges, latenzarmes TTS-Modell in über 70 Sprachen. Ideal für Entwickleranwendungen, bei denen Geschwindigkeit zählt und nicht-englische Sprachen benötigt werden.

Erstellen Sie natürliche, menschenähnliche Stimmen für Chatbots und virtuelle Assistenten – mit KI-Text-to-Speech.

Erzeugen Sie Voiceovers für Videospielcharaktere mit der Text-to-Speech-API – kontextbewusst und emotional präzise für realistische In-Game-Szenarien.

Verwandeln Sie Text in Hörbücher mit natürlich klingenden KI-Stimmen – schnell generiert und in mehreren Sprachen verfügbar.
.webp&w=3840&q=95)
Erstellen Sie hochwertige Voiceovers für Videos, TV-Shows und Animationen – mit KI-Text-to-Speech, ohne menschliche Sprecher. Für schnellere und skalierbare Produktionen.

Erstellen Sie professionelle Podcasts mit KI-Text-to-Speech – und reduzieren Sie den Aufwand für manuelle Aufnahmen.

Integrieren Sie KI-Text-to-Speech in Websites und Apps, für barrierefreie Audioversionen, die sehbeeinträchtigte und leseschwache Nutzer unterstützen.
Profitieren Sie mit minimalem Programmieraufwand und durch einfache Einbindung von der geringen Latenz unserer Text-to-Speech-API und werten Sie Ihre Anwendungen durch klare, qualitativ hochwertige Sprachinhalte auf
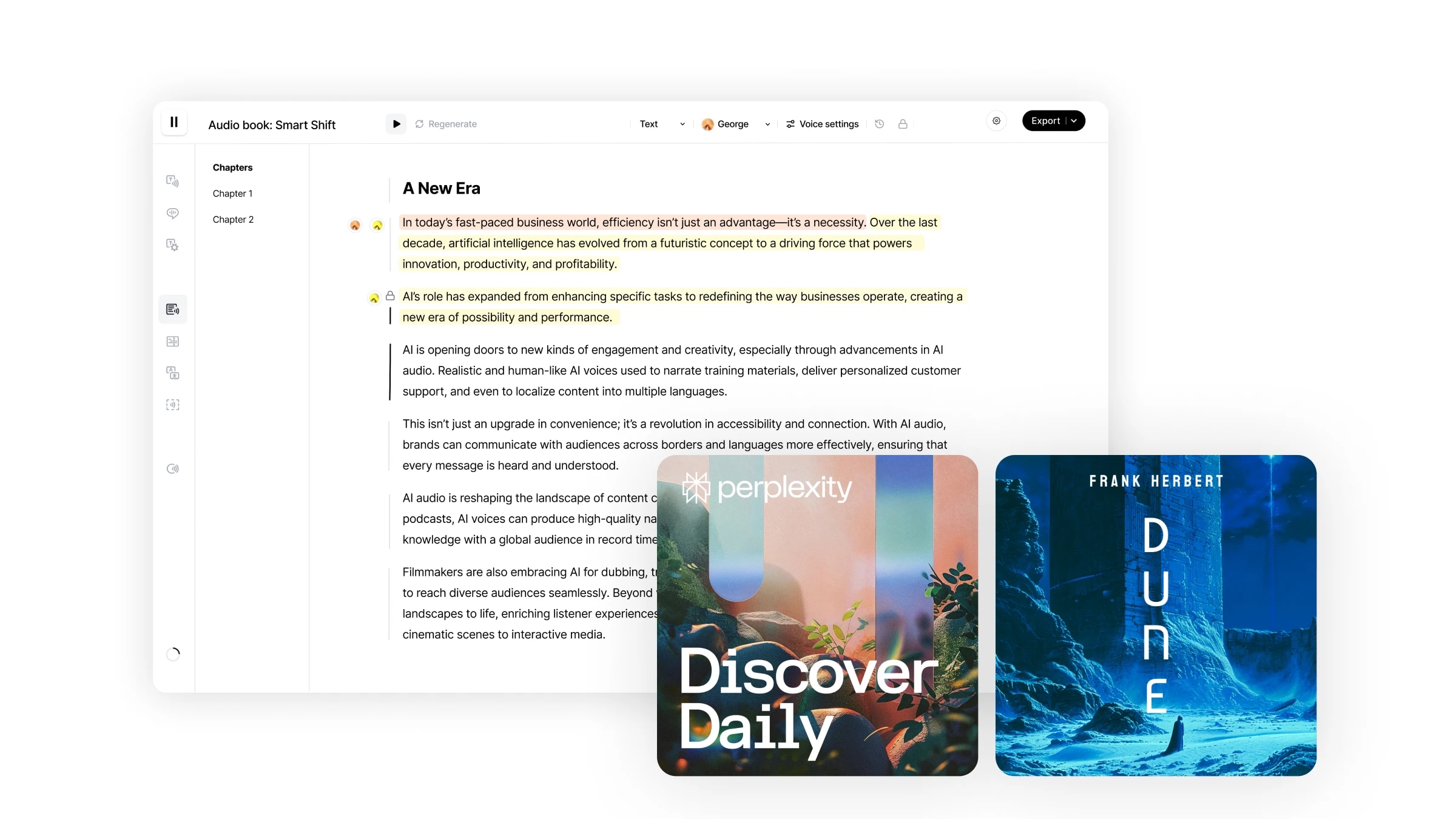
Ihr umfassender Workflow, um Bücher in Hörbücher, Skripte in Podcasts zu verwandeln oder andere Audioformate Ihrer Wahl zu erstellen.
Five Stations Radio
Paradox Interactive
UNTERNEHMEN

✓ SLAs auf Unternehmensebene
✓ Dedizierter Support
✓ Vorrangiger Zugang
✓ API-Zugriff
✓ Unbegrenzte Sitzplätze
✓ Mengenrabatte

Entdecke unsere umfangreiche Sammlung hochqualitativer Stimmen, maßgeschneidert für die Kreativbranche. Egal, ob Hörbücher, Videos oder interaktive Inhalte – finde die perfekte Stimme, um deine Vision zum Leben zu erwecken.
Bereitgestellt von ElevenLabs Konversationelle KI

















.webp&w=3840&q=95)
.webp&w=3840&q=95)
.webp&w=3840&q=95)