How we engineered RAG to be 50% faster
- Written by
- Michal Korbela
- Published
- Last updated
ListenListen to this article
RAG improves accuracy for AI agents by grounding LLM responses in large knowledge bases. Rather than sending the entire knowledge base to the LLM, RAG embeds the query, retrieves the most relevant information, and passes it as context to the model. In our system, we add a query rewriting step first, collapsing dialogue history into a precise, self-contained query before retrieval.
For very small knowledge bases, it can be simpler to pass everything into the prompt directly. But once the knowledge base grows larger, RAG becomes essential for keeping responses accurate without overwhelming the model.
Many systems treat RAG as an external tool, however we’ve built it directly into the request pipeline so it runs on every query. This ensures consistent accuracy but also creates a latency risk.
Why query rewriting slowed us down
Most user requests reference prior turns, so the system needs to collapse dialogue history into a precise, self-contained query.
For example:
- If the user asks: “Can we customize those limits based on our peak traffic patterns?"
- The system rewrites this to: “Can Enterprise plan API rate limits be customized for specific traffic patterns?”
The rewriting turns vague references like “those limits” into self-contained queries that retrieval systems can use, improving the context and accuracy of the final response. But relying on a single externally-hosted LLM created a hard dependency on its speed and uptime. This step alone accounted for more than 80% of RAG latency.
How we fixed it with model racing
We redesigned query rewriting to run as a race:
- Multiple models in parallel. Each query is sent to multiple models at once, including our self-hosted Qwen 3-4B and 3-30B-A3B models. The first valid response wins.
- Fallbacks that keep conversations flowing. If no model responds within one second, we fall back to the user’s raw message. It may be less precise, but it avoids stalls and ensures continuity.
.webp&w=3840&q=95)
The impact on performance
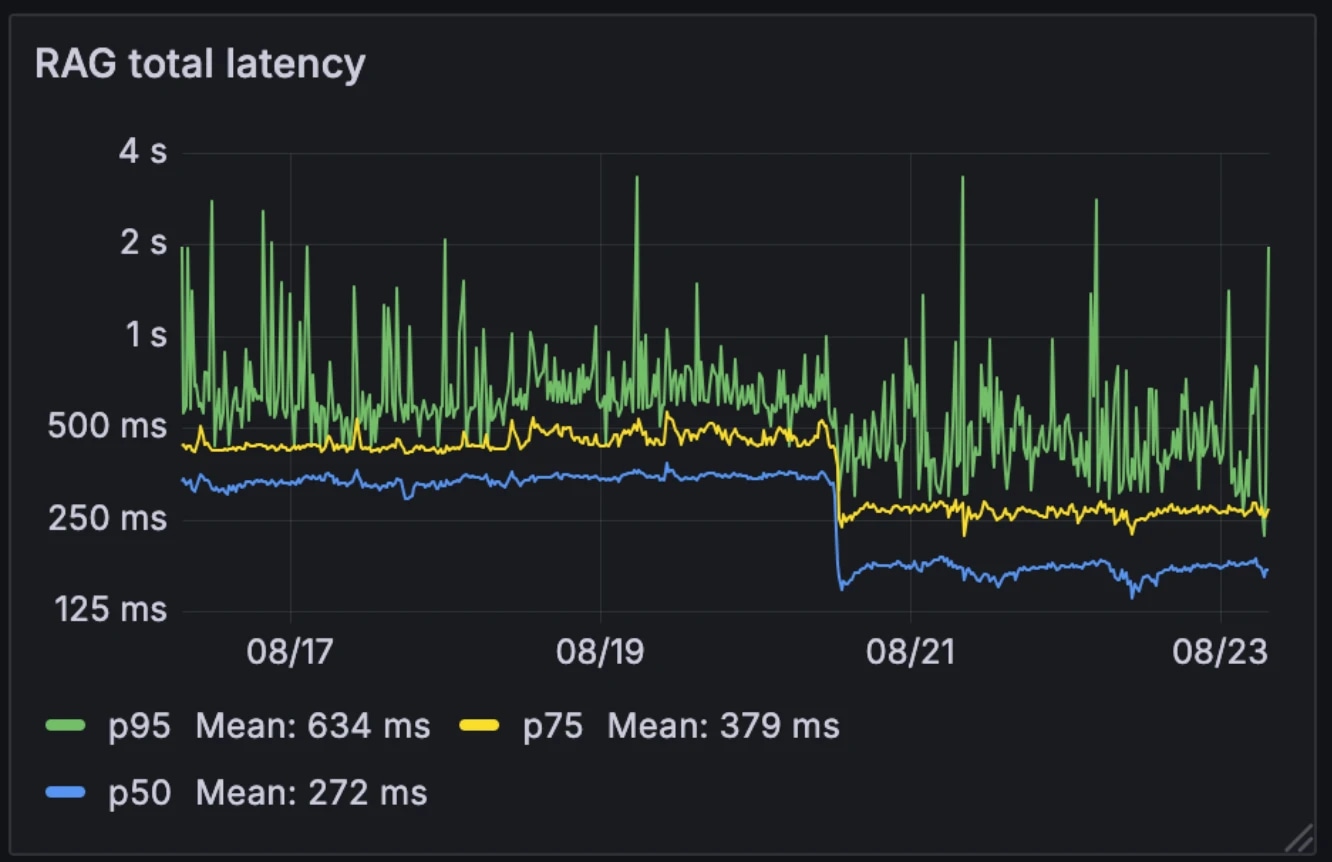
This new architecture cut median RAG latency in half, from 326ms to 155ms. Unlike many systems that trigger RAG selectively as an external tool, we run it on every query. With median latency down to 155ms, the overhead of doing this is negligible.
Latency before and after:
- Median: 326ms → 155ms
- p75: 436ms → 250ms
- p95: 629ms → 426ms
The architecture also made the system more resilient to model variability. While externally-hosted models can slow during peak demand hours, our internal models stay relatively consistent. Racing the models smooths this variability out, turning unpredictable individual model performance into more stable system behavior.
For example, when one of our LLM providers experienced an outage last month, conversations continued seamlessly on our self-hosted models. Since we already operate this infrastructure for other services, the additional compute cost is negligible.
Why it matters
Sub-200ms RAG query rewriting removes a major bottleneck for conversational agents. The result is a system that remains both context-aware and real-time, even when operating over large enterprise knowledge bases. With retrieval overhead reduced to near-negligible levels, conversational agents can scale without compromising performance.



.webp&w=3840&q=80)
