
Introducing ElevenAgents Spotlight
- Category
- Product
- Date
Scribe v2 is the most accurate Speech to Text model. Scribe v2 Realtime sets the benchmark for live transcriptions - powering agents and real-time applications. Both available via API.


Scribe v2 Realtime captures live speech in under 150 ms with exceptional accuracy – built for agents, meetings, and AI Agents that demand instant understanding.
Scribe v2 Realtime delivers industry-leading accuracy with sub-150 ms latency, setting a new benchmark for real-time speech recognition.
Automatically detect when speech starts and stops, segmenting speech with precision for smoother live processing.
Delivering exceptional accuracy across accents, dialects, and recording conditions.
Build Scribe Realtime v2 into your products with the API. With full-streaming support and commit control.


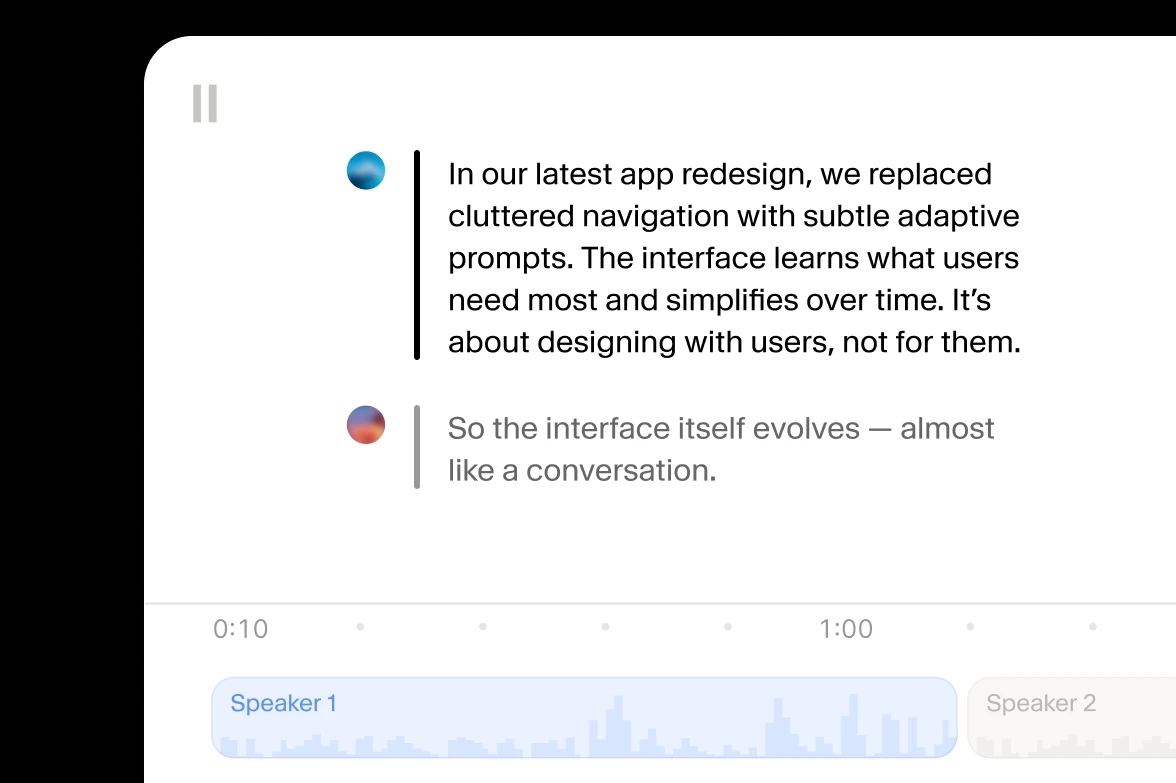
Upload audio or video in any format — MP4, MOV, MP3, WAV, and more. Scribe v2 automatically converts speech into precise text, ready for captions, subtitles, or editing.
Scribe v2 achieves industry-leading transcription accuracy, delivering clean, editable text even in challenging audio conditions or across diverse accents.
Select up to 1000 specific words or sentences for Scribe to accurately transcribe based on context.
From laughter to footsteps, Scribe v2 tags every sound event, enriching your transcripts with the full context.
Scribe v2 intuitively distinguishes and labels every speaker, calculates entity timestamps, and redacts sensitive information from transcripts.

Integrate Scribe v2 and Scribe v2 Realtime into your product with the API or SDKs.

Enable real-time voice interactions with instant, low-latency transcription.
.webp&w=3840&q=100)
Convert recordings into editable text, captions, and repurposable content.
Our AI speech to text transcription supports 90+ languages, just select the language and upload your audio file.












































































.png&w=3840&q=80)
.png&w=3840&q=80)
