Hur vi gjorde RAG 50% snabbare
- Skriven av
- Michal Korbela
- Publicerad
- Senast uppdaterad
LyssnaLyssna på den här artikeln
RAG förbättrar noggrannheten för AI-agenter genom att grunda LLM-svar i stora kunskapsbaser. Istället för att skicka hela kunskapsbasen till LLM, bäddar RAG in frågan, hämtar den mest relevanta informationen och skickar den som kontext till modellen. I vårt system lägger vi till ett steg för frågeomskrivning först, där dialoghistoriken sammanfattas till en exakt, självständig fråga innan hämtning.
För mycket små kunskapsbaser kan det vara enklare att skicka allt direkt i prompten. Men när kunskapsbasen växer blir RAG avgörande för att hålla svaren korrekta utan att överbelasta modellen.
Många system behandlar RAG som ett externt verktyg, men vi har byggt in det direkt i begäransflödet så att det körs på varje fråga. Detta säkerställer konsekvent noggrannhet men skapar också en latensrisk.
Varför frågeomskrivning saktade ner oss
De flesta användarförfrågningar refererar till tidigare turer, så systemet behöver sammanfatta dialoghistoriken till en exakt, självständig fråga.
Till exempel:
- Om användaren frågar: "Kan vi anpassa dessa gränser baserat på våra trafikmönster vid hög belastning?"
- Systemet omskriver detta till:“Kan Enterprise-planens API-gränser anpassas för specifika trafikmönster?”
Omskrivningen förvandlar vaga referenser som “de där gränserna” till självständiga frågor som hämtningssystem kan använda, vilket förbättrar kontexten och noggrannheten i det slutliga svaret. Men att förlita sig på en enda externt värd LLM skapade ett starkt beroende av dess hastighet och tillgänglighet. Detta steg stod ensamt för mer än 80% av RAG-latensen.
Hur vi löste det med modellracing
Vi omdesignade frågeomskrivningen för att köras som ett lopp:
- Flera modeller parallellt. Varje fråga skickas till flera modeller samtidigt, inklusive våra egenvärda Qwen 3-4B och 3-30B-A3B modeller. Det första giltiga svaret vinner.
- Reservlösningar som håller samtalen igång. Om ingen modell svarar inom en sekund, faller vi tillbaka på användarens råa meddelande. Det kan vara mindre exakt, men det undviker stopp och säkerställer kontinuitet.
.webp&w=3840&q=95)
Effekten på prestanda
Denna nya arkitektur halverade median RAG-latens, från 326ms till 155ms. Till skillnad från många system som utlöser RAG selektivt som ett externt verktyg, kör vi det på varje fråga. Med medianlatens nere på 155ms är överkostnaden för detta försumbar.
Latens före och efter:
- Median: 326 ms → 155 ms
- p75: 436 ms → 250 ms
- p95: 629 ms → 426 ms
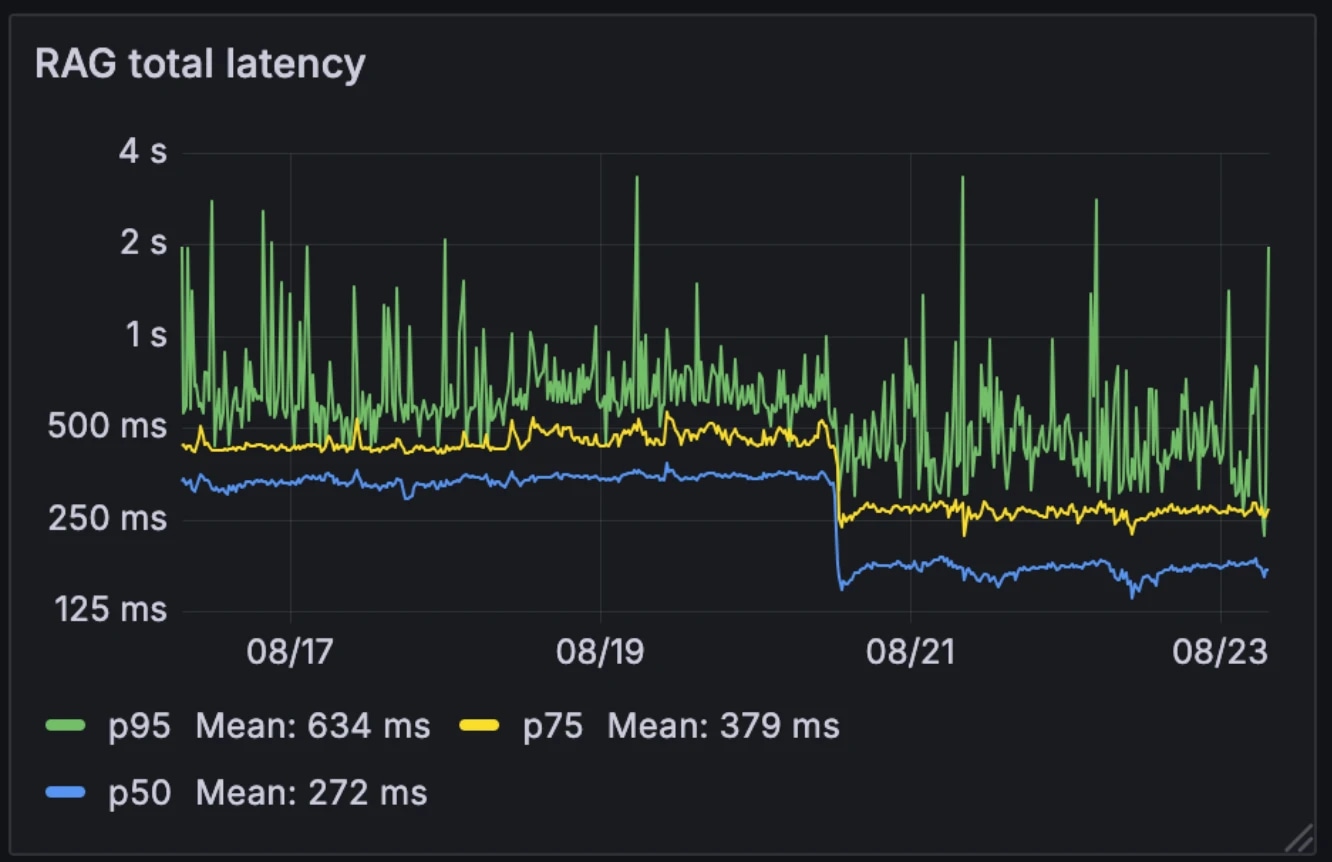
Arkitekturen gjorde också systemet mer motståndskraftigt mot modellvariabilitet. Medan externt värda modeller kan sakta ner under högtrafiktimmar, förblir våra interna modeller relativt konsekventa. Modellracing jämnar ut denna variabilitet, vilket förvandlar oförutsägbar individuell modellprestanda till mer stabilt systembeteende.
Till exempel, när en av våra LLM-leverantörer upplevde ett avbrott förra månaden, fortsatte samtalen sömlöst på våra egenvärda modeller. Eftersom vi redan driver denna infrastruktur för andra tjänster är den extra beräkningskostnaden försumbar.
Varför det är viktigt
Sub-200ms RAG-frågeomskrivning tar bort en stor flaskhals för konversationsagenter. Resultatet är ett system som förblir både kontextmedvetet och i realtid, även när det arbetar över stora företagskunskapsbaser. Med hämtningsöverhuvudet reducerat till nästan försumbar nivå kan konversationsagenter skala utan att kompromissa med prestandan.



.webp&w=3840&q=80)
