
Seu fluxo de trabalho completo para editar vídeos e áudios, adicionar locuções e música, transcrever para texto e publicar produções narradas e legendadas
Com o Text to Speech, histórias podem ser ouvidas imediatamente após a publicação, em uma variedade de vozes e estilos de entrega


Text to Speech (TTS) tecnologia, em sua essência, transforma conteúdo escrito em fala audível. Nos últimos anos, com avanços significativos em aprendizado de máquina, TTS a tecnologia evoluiu a um ponto em que a fala sintetizada é praticamente indistinguível da narração humana. O realismo e a expressividade alcançados pelos modernos TTS sistemas oferecem um potencial incomparável, especialmente para a indústria editorial.
Para editores de notícias, o cenário sonoro não é apenas um campo emergente, mas uma necessidade para o engajamento. Desenvolver uma presença em áudio tem se mostrado eficaz para aumentar a retenção e satisfação do usuário. Enquanto o caminho tradicional envolveria contratar dubladores ou repórteres para narrar, esses métodos não são eficientes em termos de tempo ou custo. Com o Text to Speech, histórias podem ser vocalizadas imediatamente após a publicação, garantindo que o conteúdo permaneça fresco, relevante e de alta qualidade.
Como alcançamos uma entrega humana mesmo em textos muito longos se deve à forma como construímos nosso modelo. Ele é treinado para entender o que está sendo dito e ajustar a entrega de acordo. Faz isso levando em conta não apenas o significado das palavras, mas também o contexto ao redor de cada enunciado.
Algoritmos tradicionais de geração de fala produzem enunciados com base em cada sentença. Isso é menos exigente computacionalmente, mas soa imediatamente robótico. Emoções e entonação muitas vezes precisam se estender e ressoar por várias sentenças para unir um determinado raciocínio. Tom e ritmo transmitem intenção, que é realmente o que faz a fala soar humana em primeiro lugar. Então, em vez de gerar cada enunciado separadamente, nosso modelo leva em conta o contexto ao redor, mantendo o fluxo e a prosódia adequados em todo o material gerado. Essa profundidade emocional, juntamente com a qualidade de áudio superior, oferece aos usuários a ferramenta de narração mais genuína e envolvente disponível.
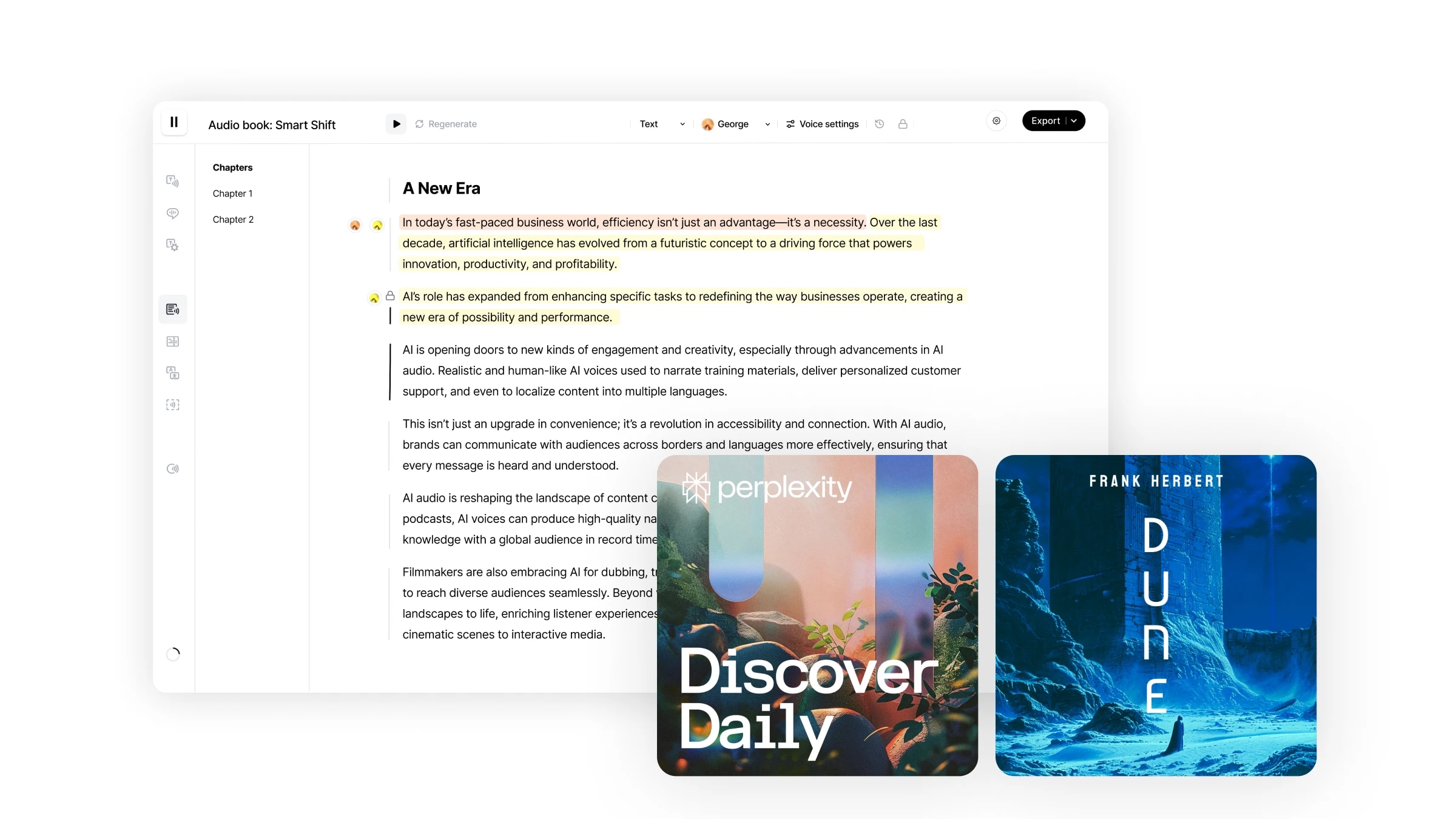
Estúdio é nosso fluxo de trabalho completo para criar audiolivros em minutos. Oferece um nível sem precedentes de controle sobre suas criações de áudio, com a capacidade de regenerar partes específicas do áudio, atribuir diferentes locutores a fragmentos de texto específicos, importar diretamente arquivos de vários formatos e muito mais.
Navegar pelo Studio é fácil e intuitivo.
O Studio oferece uma experiência de usuário direta, semelhante ao uso do Google Docs, com uma interface intuitiva e centrada no usuário, suportando uma variedade de recursos de edição:
Seu fluxo de trabalho completo para editar vídeos e áudios, adicionar locuções e música, transcrever para texto e publicar produções narradas e legendadas
O Studio está ao lado de Síntese de Fala, VoiceLab, e Voice Library, servindo como uma solução abrangente para síntese de áudio de longa duração. Além disso, está perfeitamente integrado com Professional Voice Cloning, Voice Library e nosso modelo multilíngue.
Na ElevenLabs, nosso compromisso com a inovação levou ao lançamento de um novo modelo multilíngue. Isso permite que a mesma narrativa seja traduzida e vocalizada em até 28 idiomas. Para os editores, isso significa um alcance global sem precedentes, com histórias ressoando em diferentes culturas e regiões, tudo em uma voz consistente e unificada.
Idiomas suportados agora incluem: Inglês, Coreano, Holandês, Chinês, Turco, Sueco, Indonésio, Filipino, Japonês, Ucraniano, Grego, Tcheco, Finlandês, Romeno, Dinamarquês, Búlgaro, Malaio, Eslovaco, Croata, Árabe Clássico, Polonês, Alemão, Espanhol, Francês, Italiano, Hindi, Português e Tâmil.
Nossa ferramenta proprietária Voice Design oferece uma experiência transformadora para editores. Facilita a criação de vozes completamente únicas com base em parâmetros selecionados, como idade, gênero e sotaque. Cada voz gerada é única, garantindo que os editores possam escolher uma voz específica para se tornar sinônimo de sua marca ou publicação.
Clonagem de Voz Profissional (PVC) tecnologia na ElevenLabs oferece outra camada de personalização. Ao clonar as vozes dos repórteres de uma publicação, podemos produzir histórias de áudio em seus tons únicos. Isso não apenas proporciona autenticidade, mas também reduz significativamente os custos e o tempo gasto em processos de gravação tradicionais. Além disso, nosso modelo multilíngue é compatível com a clonagem de voz profissional, garantindo que a voz de um repórter possa agora falar todos os idiomas suportados.

Automatize locuções de vídeos, leituras de anúncios, podcasts e mais, com a sua própria voz
Ouça um episódio de podcast gerado com nossa ferramenta de clonagem de voz profissional:
Para editores, a clonagem de voz profissional (PVC) oferece inúmeras vantagens:
Quando combinada com a tecnologia Texto para Voz, os editores estão equipados com um conjunto de ferramentas de última geração para produzir conteúdo auditivo rico, variado e global. Adotar as capacidades da tecnologia de clonagem de voz profissional é um movimento progressivo para os editores, abrindo uma infinidade de oportunidades.
O futuro da publicação não está apenas na palavra escrita, mas em como essas palavras são transmitidas. Com ferramentas como Texto para Voz, os editores têm o potencial de revolucionar a entrega de conteúdo, garantindo acessibilidade, exclusividade e alcance global. Na ElevenLabs, estamos na vanguarda dessa transformação, oferecendo tecnologia que abre caminho para uma experiência auditiva mais rica e diversificada.
Atualização: a partir de janeiro de 2025, Projects agora se chama Studio e está disponível para todos os usuários gratuitos.

Demand for digital tour guides rises with 10k+ tours taken and an average of 53 minutes listening time per session

Supporting 10,000+ research conversations with natural, trustworthy voices
Desenvolvido por ElevenLabs Agentes