Customer stories

Meesho delivers real-time, multilingual customer support with voice agents
Scaling incredible experiences for millions of users in Hindi and English
We’re deploying our own generative model which lets users design entirely new synthetic voices
Recently it seems everybody is talking about generative AI. Deep learning-powered large language and text-to-image models like ChatGPT, Stable Diffusion, DALL-E and Midjourney have caused much fuss in the tech world, and beyond. Many include them among the most significant recent developments in AI. Whether or not you agree, the general sentiment seems to be that something very all-powerful has appeared. In 2023 we’ll hear about models that can help you draw or create videos. Much like questions about what’s the latest-greatest smartphone, we’ll soon be asking about what's the latest-greatest foundation model. Yet for all this excitement, we feel there’s one area within generative media that’s still severely underhyped: voice AI. It’s also the area we seek to become leaders in. At Eleven, we rely on the potential unlocked by deep learning techniques each day to power our lifelike text-to-speech and voice cloning tools. And now, we’re also deploying our own generative model which lets you design entirely new synthetic voices from scratch.
Our users take to the platform daily to bring their characters alive - be it for audiobooks, games or fan fiction. We realized our current speaker bank is too small for everybody to find the voices that match their content needs while remaining exclusive to each user. Our solution was to let you design entirely new synthetic voices.
We had an idea for how we'd go about this which came as we unpacked the methods we currently use for speech synthesis and voice cloning. Both processes require a way of encoding the characteristics of a particular voice. Speaker embeddings are what carries this identity - they're a vector representation of a speaker's voice. We realized that we could sample from the distribution of speaker embeddings by training a dedicated model to let us create infinitely many new voices.
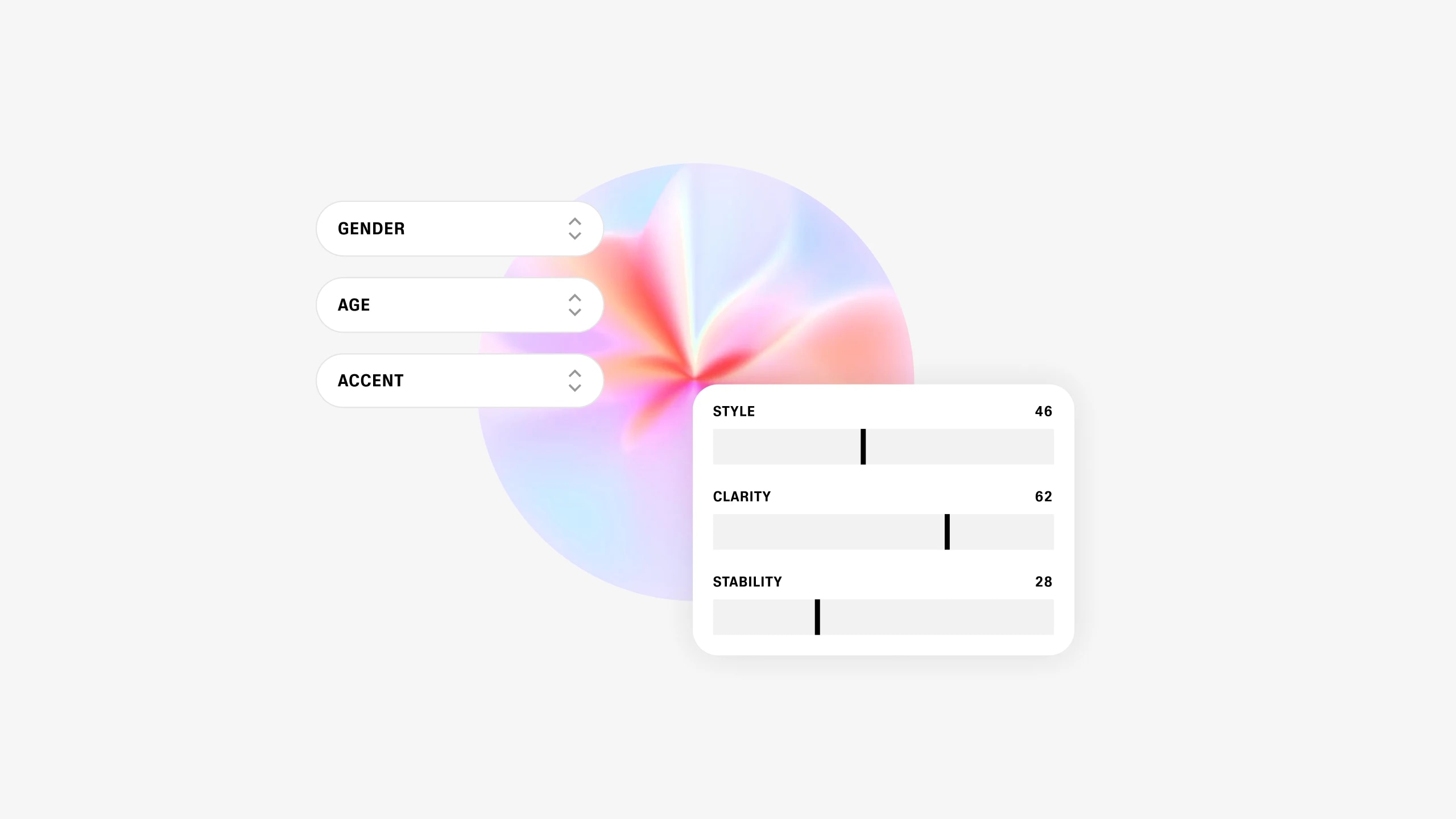
Since our users mostly look for specific speech characteristics, we needed to add a degree of control over the process. We expanded our model with conditioning to generate voices based on their characteristics. The model now lets you set certain basic parameters which establish the new voice’s core identity: gender, age, accent, pitch and speaking style. In other words, every time you hit ‘generate’, even if you choose the same base parameters, you get a completely new voice that didn't exist before.
Below are some examples of voices that can be designed this way:
'Design Voice' will become available on our platform this February, as part of Voice Lab.
Our tools can already produce speech that's as lifelike as any human's and we expect the sphere of potential applications for artificial voices will only expand. Many of these new applications, including recording audio for news publications or commercials, will require that one voice be confined to, and identified with, a particular brand or use-case, and not be used somewhere else. Other use-cases, like storytelling and video games, prioritize flexibility and the freedom to experiment from early on in development. So rather than create a gigantic set of virtual speakers, we set out to let users have the final say on which voices best suit their purposes.
Book authors now gain not just the opportunity to easily convert their work to audio but they also retain artistic control over designing bespoke narration. This presents their audiences with interesting new ways of interacting with publications, as well as greatly increases the number of books we'll be able to enjoy listening to.
News publishers have increasingly ventured into audio and choosing distinctive voices to represent their publications is an important task - many listeners value form as well as substance. Equally importantly, publishers can now be certain that a particular voice represents them, and them alone.
Video game developers can now voice a plethora of otherwise mute NPCs with all the necessary tools available at their fingertips. Not only can they be more cost-effective without compromising on quality but they can now also design voices that will be entirely unique to the virtual worlds they create.
Advertising creatives need voiceovers to suit particular campaigns, so being able to design resonating and purpose-built narration at the start of development is a considerable advantage. They can now experiment with multiple voices and delivery styles instantly and without engaging additional resources.
From creators producing all kinds of audio and video content to corporate officers seeking to voice company communications, the opportunities for designing compelling audio that’s both unique and tailored to a specific use-case are now endless.
Similarly to how voice cloning raises fears about the consequences of its potential misuse, increasingly many people worry that the proliferation of AI technology will put professionals’ livelihoods at risk. At Eleven, we see a future in which voice actors are able to license their voices to train speech models for specific use, in exchange for fees. Clients and studios will still gladly feature professional voice talent in their projects and using AI will simply contribute to faster turnaround times and greater freedom to experiment and establish direction in early development. The technology will change how spoken audio is designed and recorded but the fact that voice actors no longer need to be physically present for every session really gives them the freedom to be involved in more projects at any one time, as well as to truly immortalize their voices.
On top of this, the reason we're excited is that a multitude of books, news, independent games and other content whose authors and developers wouldn't otherwise be able to afford recording costs will now become accessible through another medium. With this increased access comes the opportunity to widen audiences in each case.
At Eleven, we're fully committed both to respecting intellectual property rights and to implementing safeguards against potential misuse of our technology:
In the future we plan to combine the capabilities of our voice generating and voice cloning models to allow users to enhance their own voices. You’ll be able to clone your voice and then manipulate it to any desired effect. If you fear your natural speaking style is a bit monotone, you’ll be able to add variety to it. If you really dislike being recorded, you’ll be able to manipulate the output to sound more natural. Any person who needs to produce audio featuring their own voice for any purpose, be it a pre-recorded presentation or an audio message, will be able to do so using our suite of tools, at a click of a button.
As 2022 drew to a close, we'd like to thank our beta-users for your continued participation and for your feedback. Many of the features we're developing are down to your input and suggestions. We couldn't be happier to have you onboard and we wish you all a Happy New Year.
Eleven Labs Beta
Go here to sign up for our beta platform and try it out for yourself. We're constantly making improvements and all user insight is very valuable for us at this early stage.
Scaling incredible experiences for millions of users in Hindi and English

AI-generated videos created with avatars & dubbed voice have grown 7x
Powered by ElevenLabs Conversational AI