
Customer Stories

Tutore deploys conversational agents for corporate language training using ElevenLabs
90% of Tutore’s placement interviews are now conducted by AI agents, accelerating onboarding and reducing costs
リリースから1ヶ月、Scribeは業界で最も高性能なテキスト変換モデルであることを証明し続けています。

わずか1ヶ月で、当社のテキスト変換モデル Scribeは業界トップクラスの精度で、すでに数千社に導入されています。メディアの字幕、コールセンター、医療の書き起こしなど、Scribeはデベロッパーに選ばれるモデルとなっています。
複数の第三者分析で、Scribeがすべてのモデル(OpenAIの新しい4oテキスト変換モデルを含む)を上回る精度であることが確認されています。たとえば、AI解析のベンチマークでは、Scribeが4oおよび4o miniトランスクリプトよりも平均してWord Error Rateで優れていることが示されています:
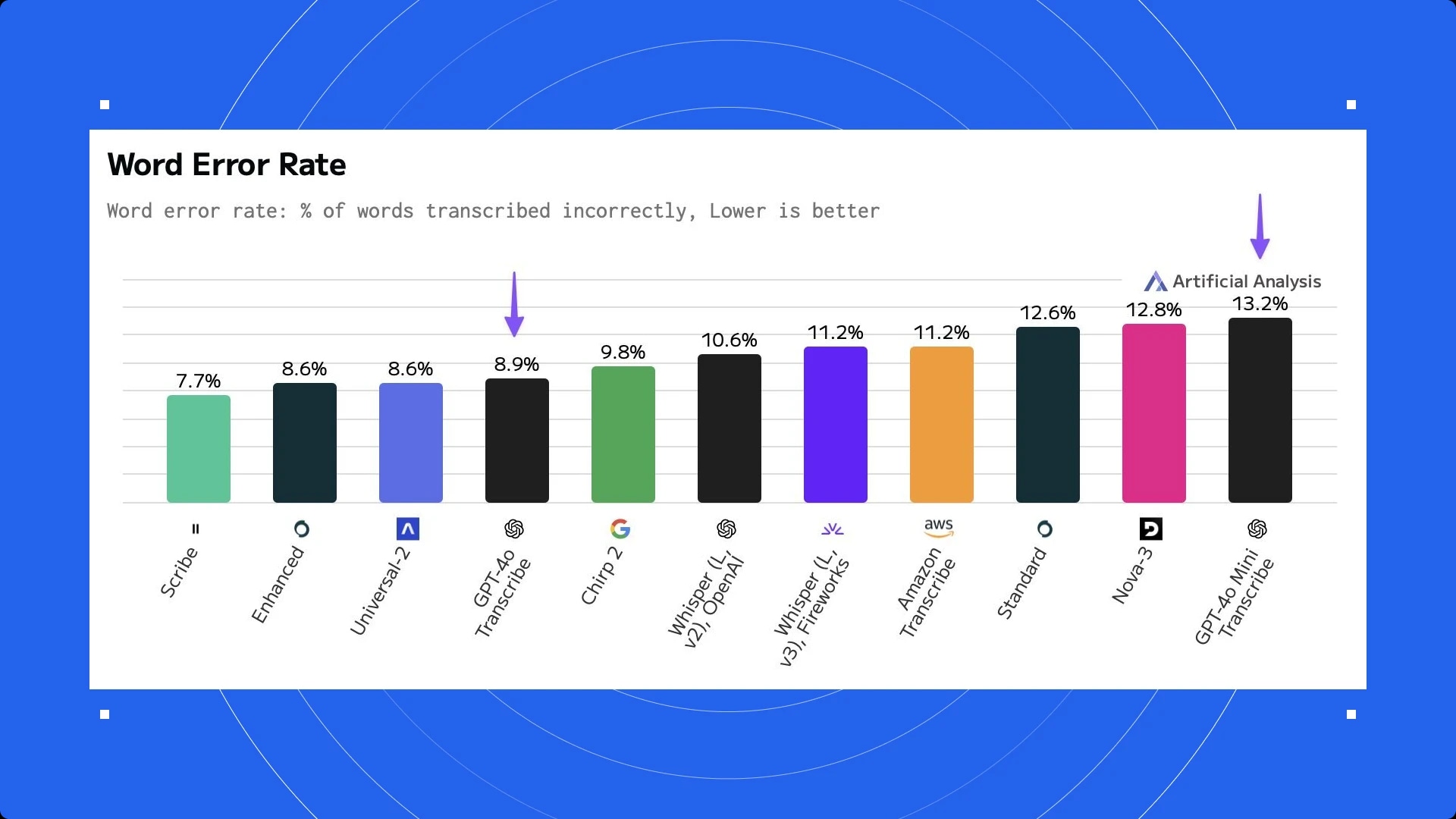
Scribeは、OpenAI自身のベンチマークでも、4oおよび4o miniトランスクリプションモデルと同等以上の精度を11言語中15言語で達成しています。たとえば日本語やヒンディー語では、ScribeはOpenAIの4oモデルよりも大きな差で優れています(OpenAI自身のベンチマークより):
Scribeでは、お客様にとってより使いやすくなるよう設計上の工夫をしています。そのため、業界ベンチマークと一致しない場合もあります。たとえば:
そのため、パフォーマンスを考える際は最終的な結果を見ることが重要です。たとえば英語では、OpenAIの4oテキスト変換モデルとScribeはベンチマーク上では同等ですが、実際の英語トランスクリプトを比較すると、Scribeの高度な機能が際立ちます。
このトランスクリプト分析は、イギリス議会公聴会のもので、Scribeがアクセントや声のトーン、バックグラウンドノイズや笑い声まで正確に捉え、ミスなく記録していることが分かります。
ElevenLabsのScribe(トランスクリプト作成時間:4.66秒)
ご質問してもよろしいでしょうか?この場所を、特に障害のある同僚のために、より利用しやすくするためにどのような取り組みが行われているのでしょうか?ヒアヒア。(ざわめき) すみません、私の南半球出身が関係しているのかもしれません。もう一度質問を繰り返していただけますか?聞き取れませんでした。(笑い声)わあ。今日はとても人気ですね。えっと、私は…私は言っていたのですが、 障害のある議会の同僚の中には、敷地内の一部を移動するのがかなり難しいと感じている方もいます。改修工事をしている今、障害のある方がもっと自由に移動でき、この場所がより利用しやすくなるためには何ができるでしょうか?ポールさん。(笑い声)本当にすみません。 どうか、南半球英語でゆっくり話していただけますか? ありがとうございます。どんな答えでも大丈夫です。私は…私は答えが…答えが役立つかもしれないと思います もし書面でご返答いただければ読まれるときに、スピーカーさん。はい、クリス・エルモアさん。(笑) ありがとうございます、副議長。最初からやってみます。(ざわめき)ああ、だめだ。あなたはウェールズ人ですね。私は…私は…私は…だって私もウェールズ人なので、神様、助けてください。
OpenAIの4o(トランスクリプト作成時間:5.01秒)
ご質問してもよろしいでしょうか? この場所を、特に障害のある同僚のために、より利用しやすくするためにどのような取り組みが行われているのでしょうか?すみません、私の南半球出身が関係しているのかもしれません。もう一度質問を繰り返していただけますか?聞き取れませんでした。今日はとても人気ですね。私は、 障害のある議会の同僚の中には、敷地内の一部を移動するのがかなり難しいと感じている方もいます。改修工事をしている今、障害のある方がもっと自由に移動でき、この場所がより利用しやすくなるためには何ができるでしょうか?本当にすみません。 どうか、南半球英語でゆっくり話していただけますか?答えが役立つかもしれません もし書面でご返答いただければ読まれるときに。ありがとうございます、副議長。最初からやってみます。なぜなら 私はウェールズ人なので、神様、助けてください。
AIが進化するたびに、見落とされがちなグループが大きな恩恵を受けています。それが吃音のある方です。吃音は人口の約1%が抱える遺伝性の発話障害で、自動音声認識(ASR)システムにとって独特の課題となります。吃音が約4語に1語の割合で含まれるテストサンプルでの調査では、Scribeは平均98.7%の精度を記録しました。これにより、Scribeが業界をリードし、あらゆるエンタープライズニーズに応えるモデルであることが改めて証明されました。
Scribeは、エンタープライズのお客様の課題解決に特化した機能を備えています。
Scribeを今すぐ体験、ウェブ版は4月9日まで無料です。Scribeの料金は非常に競争力があり、エンタープライズのお客様向けに1時間あたり$0.22からご利用いただけます。お気軽に営業チームにお問い合わせください。デモのご案内や、ビジネスへの活用方法をご提案いたします。
90% of Tutore’s placement interviews are now conducted by AI agents, accelerating onboarding and reducing costs
.webp&w=3840&q=95)
Generate individual vocals, instruments or full tracks with stylistic consistency using a fine-tuned version of our Music model.