
वीडियो और ऑडियो संपादित करने, वॉइसओवर और संगीत जोड़ने, टेक्स्ट में ट्रांसक्राइब करने और वर्णनात्मक, कैप्शनयुक्त प्रोडक्शंस प्रकाशित करने के लिए आपका पूरा वर्कफ़्लो
टेक्स्ट टू स्पीच के साथ, कहानियाँ प्रकाशित होते ही विभिन्न आवाज़ों और शैलियों में सुनी जा सकती हैं


Text to Speech (TTS) तकनीक, मूल रूप से, लिखित सामग्री को श्रव्य आवाज़ में बदलती है। हाल के वर्षों में, मशीन लर्निंग में महत्वपूर्ण प्रगति के साथ, TTS तकनीक इस स्तर तक विकसित हो गई है कि सिंथेसाइज़्ड आवाज़ मानव कथन से लगभग अप्रभेद्य है। आधुनिक TTS सिस्टम द्वारा प्राप्त यथार्थवाद और अभिव्यक्ति विशेष रूप से प्रकाशन उद्योग के लिए अद्वितीय संभावनाएं प्रदान करते हैं।
समाचार प्रकाशकों के लिए, ध्वनि परिदृश्य केवल एक उभरता हुआ क्षेत्र नहीं है बल्कि जुड़ाव के लिए आवश्यक है। ऑडियो उपस्थिति बढ़ाने से उपयोगकर्ता प्रतिधारण और संतुष्टि में सुधार हुआ है। जबकि पारंपरिक मार्ग में वॉइस ऐक्टर को नियुक्त करना या रिपोर्टरों को कथन के लिए लाना शामिल होगा, ये तरीके न तो समय और न ही लागत-कुशल हैं। टेक्स्ट टू स्पीच के साथ, कहानियों को प्रकाशन के तुरंत बाद आवाज़ दी जा सकती है, यह सुनिश्चित करते हुए कि सामग्री ताज़ा, प्रासंगिक और उच्च गुणवत्ता की बनी रहे।
हम लंबे टेक्स्ट पर भी मानव जैसी डिलीवरी कैसे प्राप्त करते हैं, यह हमारे मॉडल के निर्माण के तरीके पर निर्भर करता है।हमारा मॉडल। इसे यह समझने के लिए प्रशिक्षित किया गया है कि क्या कहा जा रहा है और तदनुसार डिलीवरी को समायोजित करने के लिए। यह न केवल शब्दों के अर्थ को बल्कि प्रत्येक कथन के आसपास के संदर्भ को भी ध्यान में रखकर करता है।
पारंपरिक स्पीच जनरेशन एल्गोरिदम वाक्य-दर-वाक्य आधार पर कथन उत्पन्न करते हैं। यह कम्प्यूटेशनल रूप से कम मांग वाला है लेकिन तुरंत रोबोटिक लगता है। भावनाएं और स्वर अक्सर एक विशेष विचारधारा को जोड़ने के लिए कई वाक्यों में फैलने और गूंजने की आवश्यकता होती है। स्वर और गति इरादे को व्यक्त करते हैं जो वास्तव में भाषण को मानव जैसा बनाता है। इसलिए प्रत्येक कथन को अलग से उत्पन्न करने के बजाय, हमारा मॉडल पूरे उत्पन्न सामग्री में उचित प्रवाह और प्रोसोडी बनाए रखते हुए आसपास के संदर्भ को ध्यान में रखता है। यह भावनात्मक गहराई, प्रमुख ऑडियो गुणवत्ता के साथ मिलकर, उपयोगकर्ताओं को सबसे प्रामाणिक और आकर्षक कथन उपकरण प्रदान करती है।
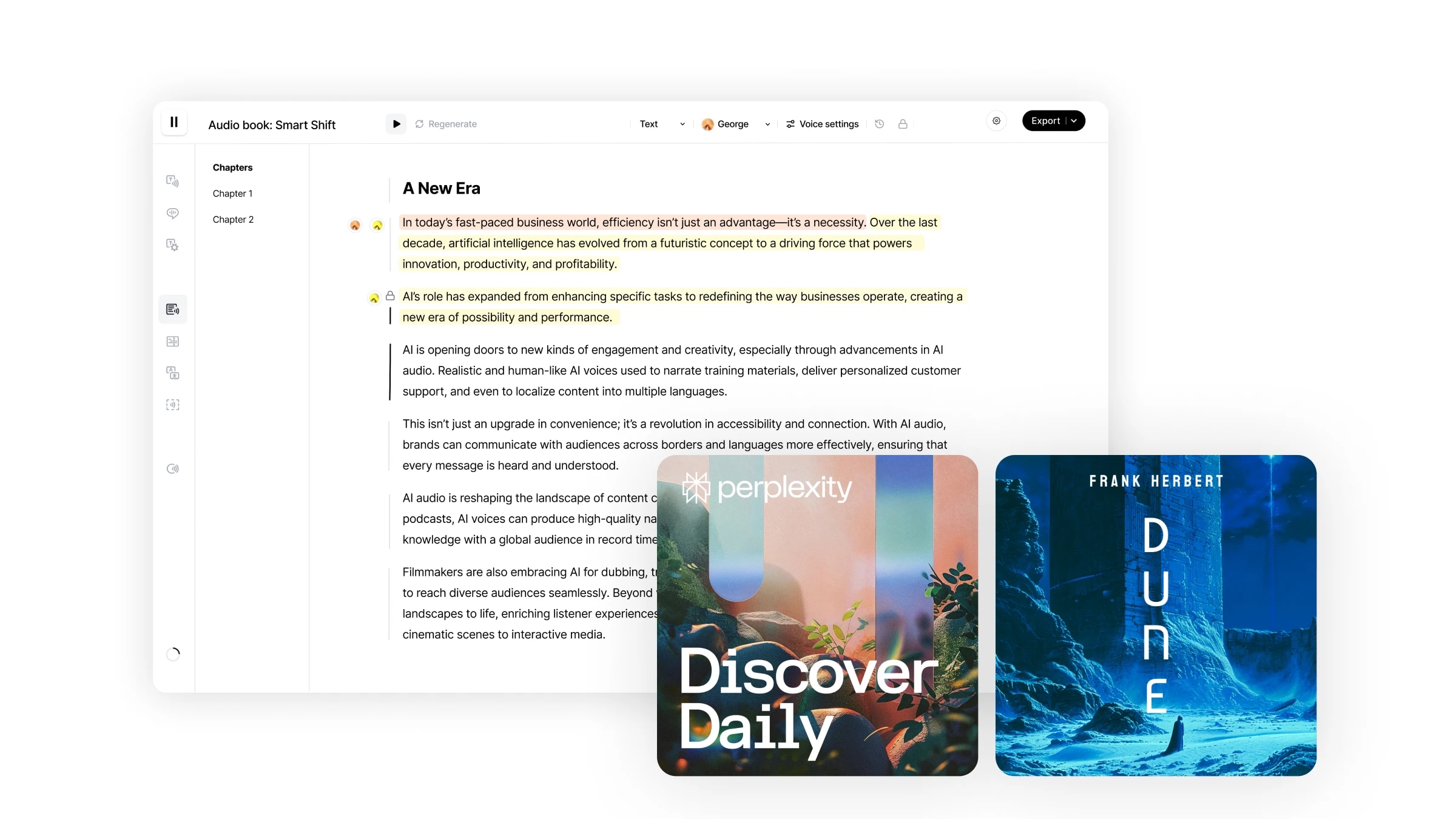
स्टूडियो हमारी एंड-टू-एंड वर्कफ़्लो है जो मिनटों में ऑडियोबुक बनाने के लिए है। यह आपके ऑडियो निर्माणों पर अभूतपूर्व स्तर का नियंत्रण प्रदान करता है, जिसमें विशिष्ट ऑडियो खंडों को पुनः उत्पन्न करने, विशेष टेक्स्ट खंडों को विभिन्न वक्ताओं को असाइन करने, कई प्रारूप फ़ाइलों को सीधे आयात करने की क्षमता और अधिक शामिल है।
स्टूडियो को नेविगेट करना आसान और सहज है।
स्टूडियो एक सीधा उपयोगकर्ता अनुभव प्रदान करता है, जैसे कि Google Docs का उपयोग करना, एक सहज, उपयोगकर्ता-केंद्रित इंटरफ़ेस के साथ जो विभिन्न संपादन सुविधाओं का समर्थन करता है:
वीडियो और ऑडियो संपादित करने, वॉइसओवर और संगीत जोड़ने, टेक्स्ट में ट्रांसक्राइब करने और वर्णनात्मक, कैप्शनयुक्त प्रोडक्शंस प्रकाशित करने के लिए आपका पूरा वर्कफ़्लो
स्टूडियो के साथ खड़ा है स्पीच सिंथेसिस, वॉइसलैब, और Voice Library, लंबी ऑडियो सिंथेसिस के लिए एक व्यापक समाधान के रूप में सेवा कर रहा है। इसके अतिरिक्त, यह प्रोफेशनल वॉइस क्लोनिंग, वॉइस लाइब्रेरी और हमारे बहुभाषी मॉडल के साथ सहजता से एकीकृत है।
ElevenLabs में, नवाचार के प्रति हमारी प्रतिबद्धता ने एक नए बहुभाषी मॉडल के लॉन्च का नेतृत्व किया है। यह एक ही कथा को अनुवादित और आवाज़ देने की अनुमति देता है 28 भाषाओं में। प्रकाशकों के लिए, इसका मतलब है अभूतपूर्व वैश्विक पहुंच, विभिन्न संस्कृतियों और क्षेत्रों में कहानियों की गूंज, सभी एक सुसंगत और एकीकृत आवाज़ में।
अब समर्थित भाषाओं में शामिल हैं: अंग्रेजी, कोरियाई, डच, चीनी, तुर्की, स्वीडिश, इंडोनेशियाई, फिलिपिनो, जापानी, यूक्रेनी, ग्रीक, चेक, फिनिश, रोमानियाई, डेनिश, बुल्गारियाई, मलय, स्लोवाक, क्रोएशियाई, क्लासिक अरबी, पोलिश, जर्मन, स्पेनिश, फ्रेंच, इतालवी, हिंदी, पुर्तगाली, और तमिल।
हमारा स्वामित्व Voice Design उपकरण प्रकाशकों के लिए एक परिवर्तनकारी अनुभव प्रदान करता है। यह चयनित मापदंडों जैसे आयु, लिंग और उच्चारण के आधार पर पूरी तरह से अद्वितीय आवाज़ें बनाने की सुविधा प्रदान करता है। हर उत्पन्न आवाज़ अद्वितीय होती है, यह सुनिश्चित करते हुए कि प्रकाशक एक विशेष आवाज़ चुन सकते हैं जो उनके ब्रांड या प्रकाशन के पर्याय बन जाए।
प्रोफेशनल वॉइस क्लोनिंग (PVC) तकनीक ElevenLabs में अनुकूलन की एक और परत प्रदान करती है। एक प्रकाशन के रिपोर्टरों की आवाज़ों को क्लोन करके, हम उनकी अनूठी टोन में ऑडियो कहानियां बना सकते हैं। यह न केवल प्रामाणिकता प्रदान करता है बल्कि पारंपरिक रिकॉर्डिंग प्रक्रियाओं पर लागत और समय को भी काफी कम करता है। इसके अलावा, हमारा बहुभाषी मॉडल प्रोफेशनल वॉइस क्लोनिंग के साथ संगत है, यह सुनिश्चित करते हुए कि एक रिपोर्टर की आवाज़ अब सभी समर्थित भाषाओं में बोल सकती है।

वीडियो वॉइसओवर, विज्ञापन पढ़ने, पॉडकास्ट और अन्य चीजों को आपकी अपनी आवाज़ में ऑटोमैट करें
हमारे प्रोफेशनल वॉइस क्लोनिंग टूल के साथ उत्पन्न एक पॉडकास्ट एपिसोड सुनें:
प्रकाशकों के लिए, प्रोफेशनल वॉइस क्लोनिंग (PVC) कई फायदे प्रदान करता है:
टेक्स्ट टू वॉइस तकनीक के साथ संयुक्त होने पर, प्रकाशकों के पास समृद्ध, विविध और वैश्विक श्रव्य सामग्री का उत्पादन करने के लिए एक अत्याधुनिक टूलकिट होता है। प्रोफेशनल वॉइस क्लोनिंग तकनीक की क्षमताओं को अपनाना प्रकाशकों के लिए एक प्रगतिशील कदम है, जो अनगिनत अवसरों के द्वार खोलता है।
प्रकाशन का भविष्य केवल लिखित शब्द में नहीं है बल्कि उन शब्दों को कैसे व्यक्त किया जाता है। टेक्स्ट टू वॉइस जैसे उपकरणों के साथ, प्रकाशकों के पास अपनी सामग्री वितरण में क्रांति लाने की क्षमता है, यह सुनिश्चित करते हुए कि पहुंच, विशिष्टता और वैश्विक पहुंच बनी रहे। ElevenLabs में, हम इस परिवर्तन के अग्रणी हैं, ऐसी तकनीक की पेशकश कर रहे हैं जो एक समृद्ध, अधिक विविध श्रव्य अनुभव का मार्ग प्रशस्त करती है।
अपडेट: जनवरी 2025 से, प्रोजेक्ट्स को अब स्टूडियो कहा जाता है और यह सभी मुफ्त उपयोगकर्ताओं के लिए उपलब्ध है।

Demand for digital tour guides rises with 10k+ tours taken and an average of 53 minutes listening time per session

Supporting 10,000+ research conversations with natural, trustworthy voices
ElevenLabs द्वारा संचालित एजेंट्स