
Recherche

Découvrez Scribe
Transcrivez la parole en texte avec le modèle ASR le plus précis au monde
Auteurs

Présentation de Eleven v3 Alpha
Essayez v3Transcrivez la parole en texte avec le modèle ASR le plus précis au monde

Vous n'avez jamais expérimenté un TTS aussi rapide et de type humain

Élargissez votre audience et créez un son de haute qualité en 32 langues

Synthèse vocale de haute qualité et à faible latence en 32 langues

Notre modèle le plus rapide a désormais une prononciation des nombres améliorée

Cette avancée permettra aux sociétés de médias, aux développeurs de jeux, aux éditeurs et aux créateurs indépendants du monde entier d’améliorer considérablement l’accessibilité de leur contenu.

Notre approche actuelle de deep learning exploite plus de données, plus de puissance de calcul et des techniques novatrices pour offrir notre modèle de synthèse vocale le plus avancé
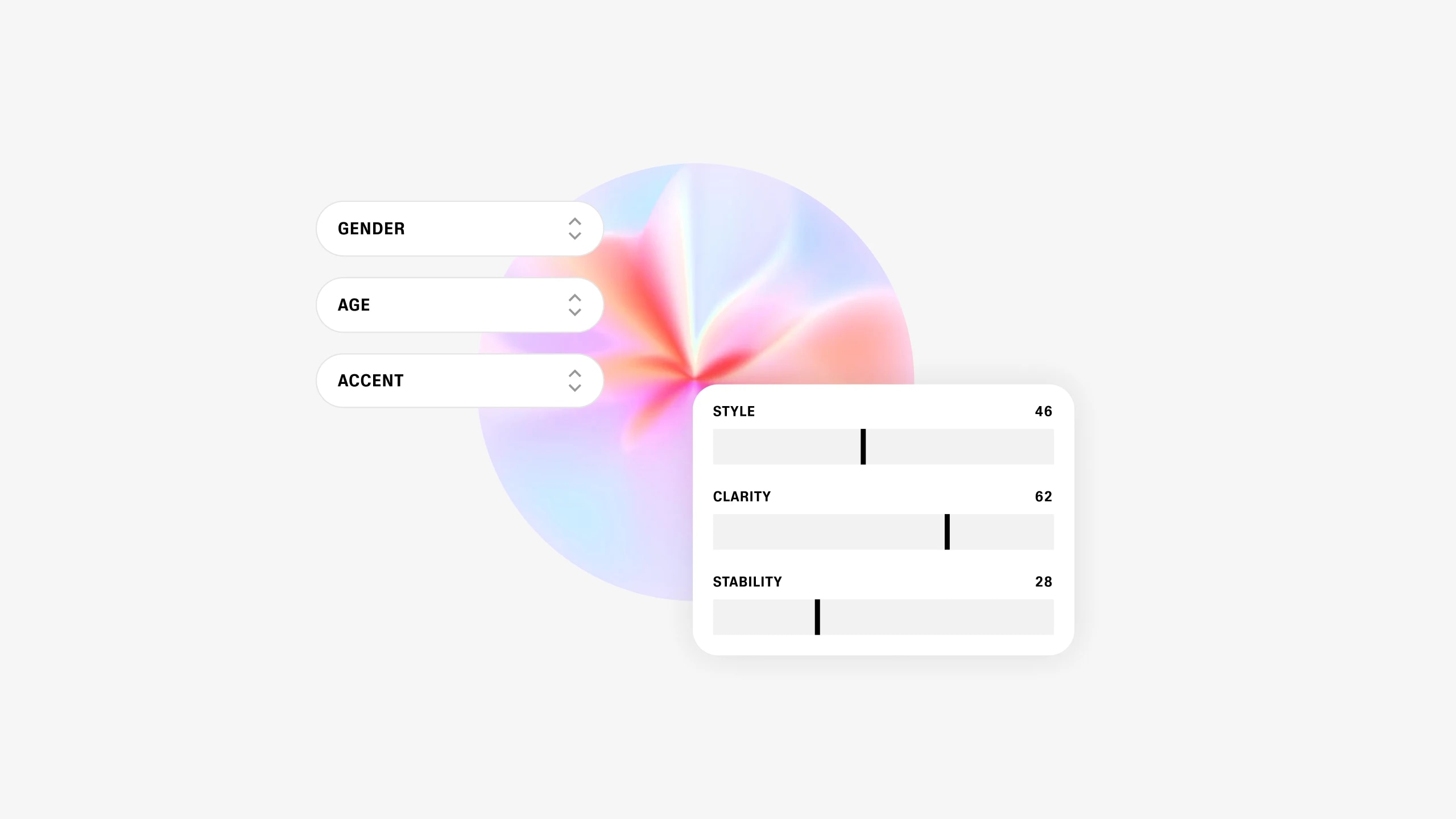
Nous déployons notre propre modèle génératif qui permet aux utilisateurs de concevoir des voix synthétiques entièrement nouvelles

Notre modèle produit des émotions comme aucun autre

Faire parler une personne avec la voix d'une autre

