

























Singapore Data Residency is now available
- Category
- Company
- Date
Trusted by 1M+ users • Free to start



Narration
Expressive voices that bring audiobooks and podcasts to life.
Advertisement
Persuasive voices that drive action and brand recall.
Characters
Playful and engaging voices for cartoons or video games.
Narration
Expressive voices that bring audiobooks and podcasts to life.
Conversational
Natural voices perfect for informal scenarios.
Social Media
Trendy, attention-grabbing voices for short-form content.

Create controllable, expressive speech layered with emotion, audio events, and immersive soundscapes.
The voice paused for a moment, [softly] as if gathering its thoughts before continuing. Every breath felt intentional, every hesitation perfectly timed.
This wasn't synthetic speech anymore [laughs warmly] - it was a voice that understood timing, emotion, and the space between words.
Text transformed into presence. [sighs contentedly] Words given life, personality, soul.
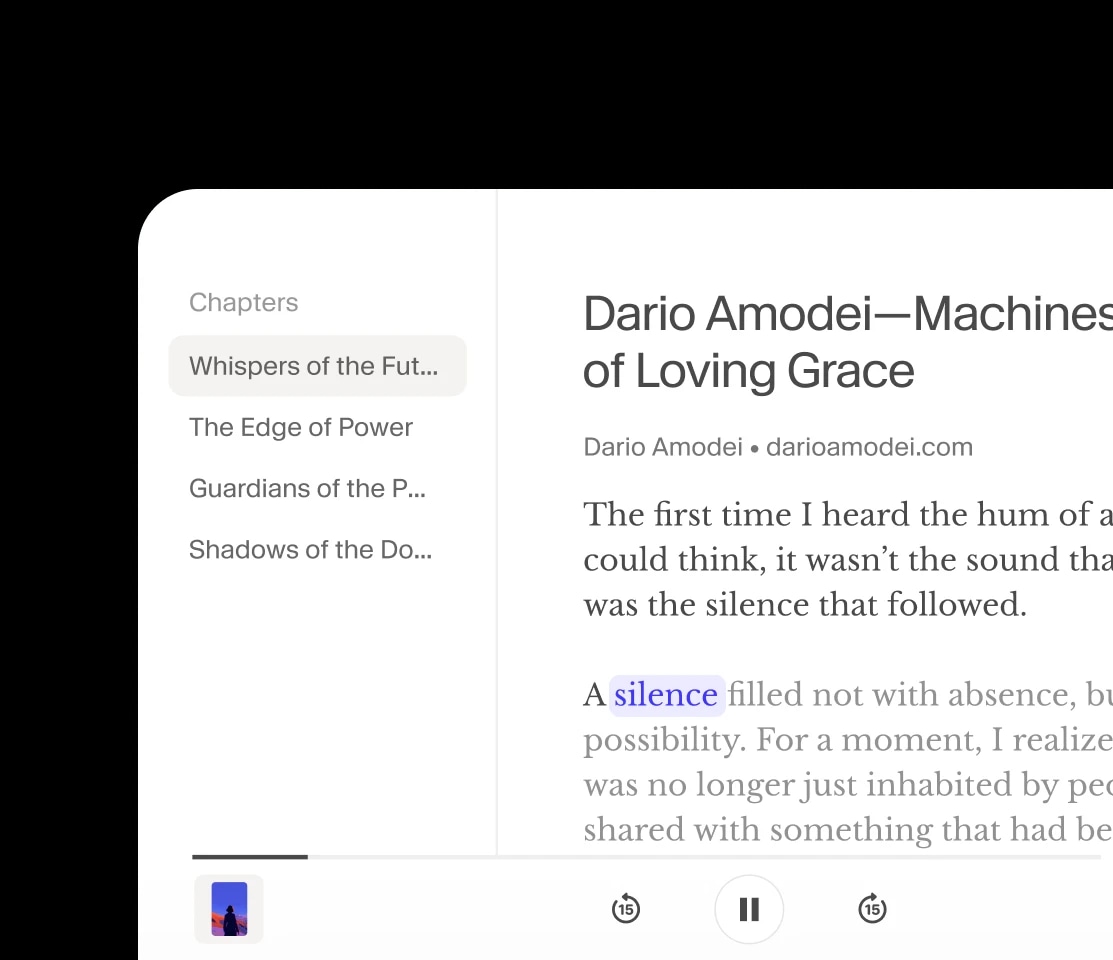
Explore an ever-growing collection of expressive, lifelike voices for any use case - from narration to character creation.
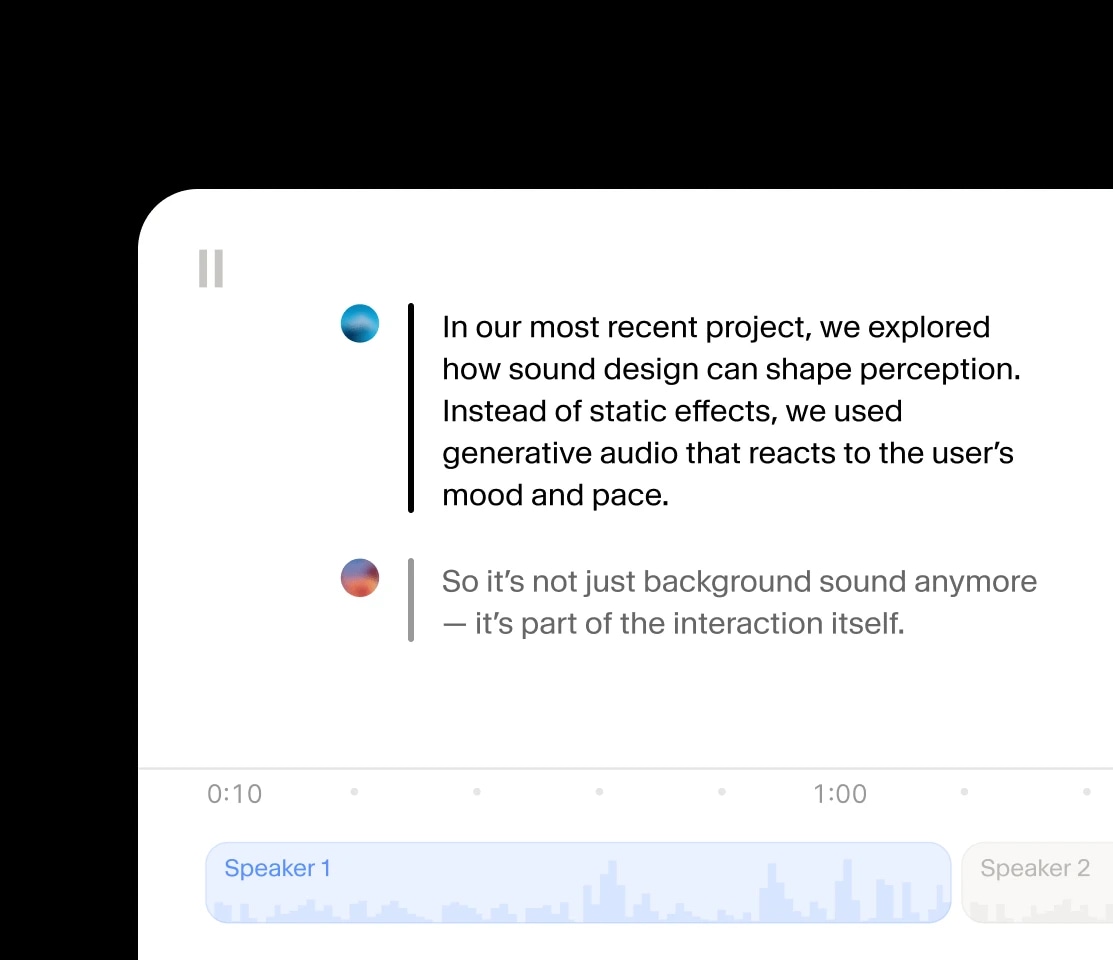
Create audio conversations where speakers share context and emotion.
Instantly replicate your own voice or craft unique AI Voices with full control.
Bring stories to life in over 70 languages, all with native-level emotion and clarity.
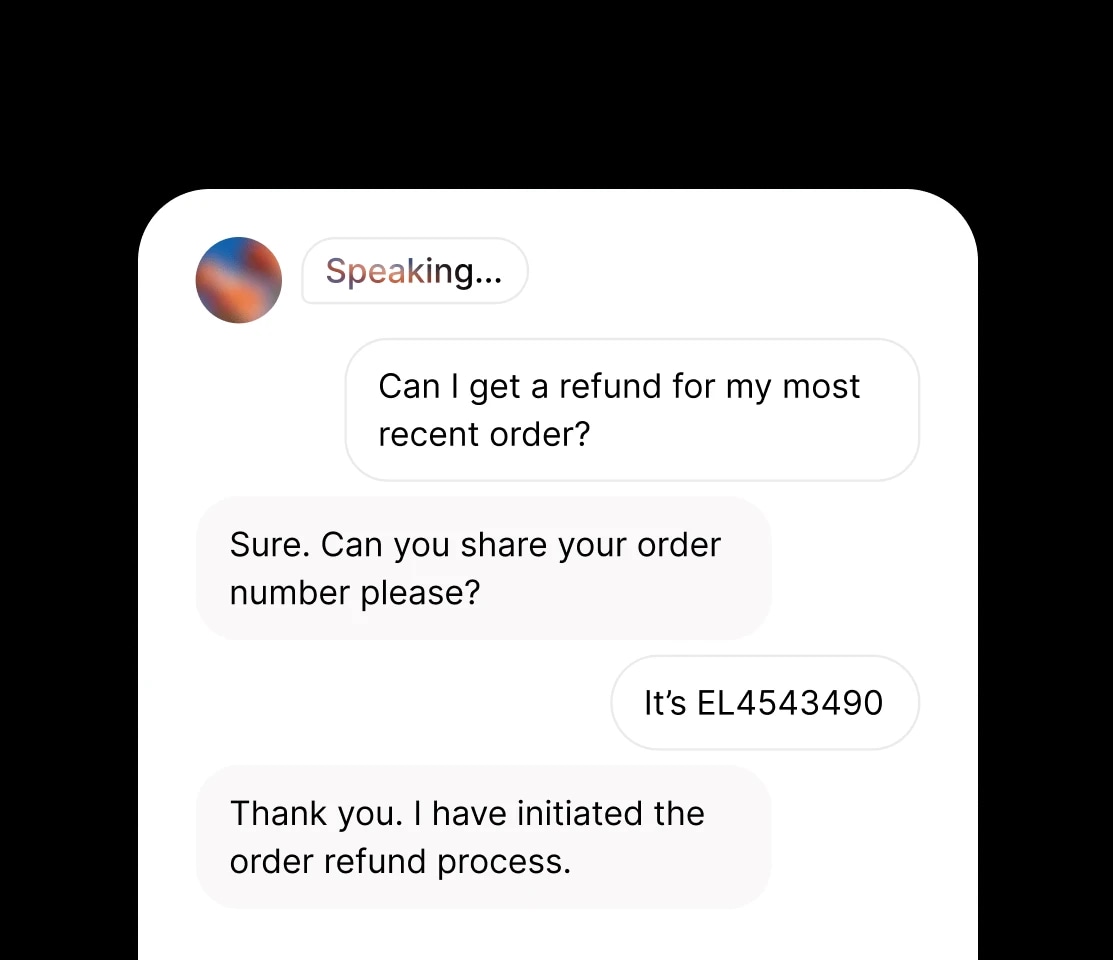



Our most advanced, expressive model with audio tags for precise emotional control. Best for storytelling, gaming and media production in 70+ languages.

Our most lifelike, emotionally rich text to speech model supporting 29 languages. Best for voiceovers, audiobooks, post-production and content creation.

Our high quality, low latency TTS model in 32 languages. Best for developer use cases where speed matters and you need non-English languages

High quality, low-latency model with a good balance of quality and speed

The best AI audio models in one powerful editor.

Generate expressive audio in seconds using our iOS and Android apps.
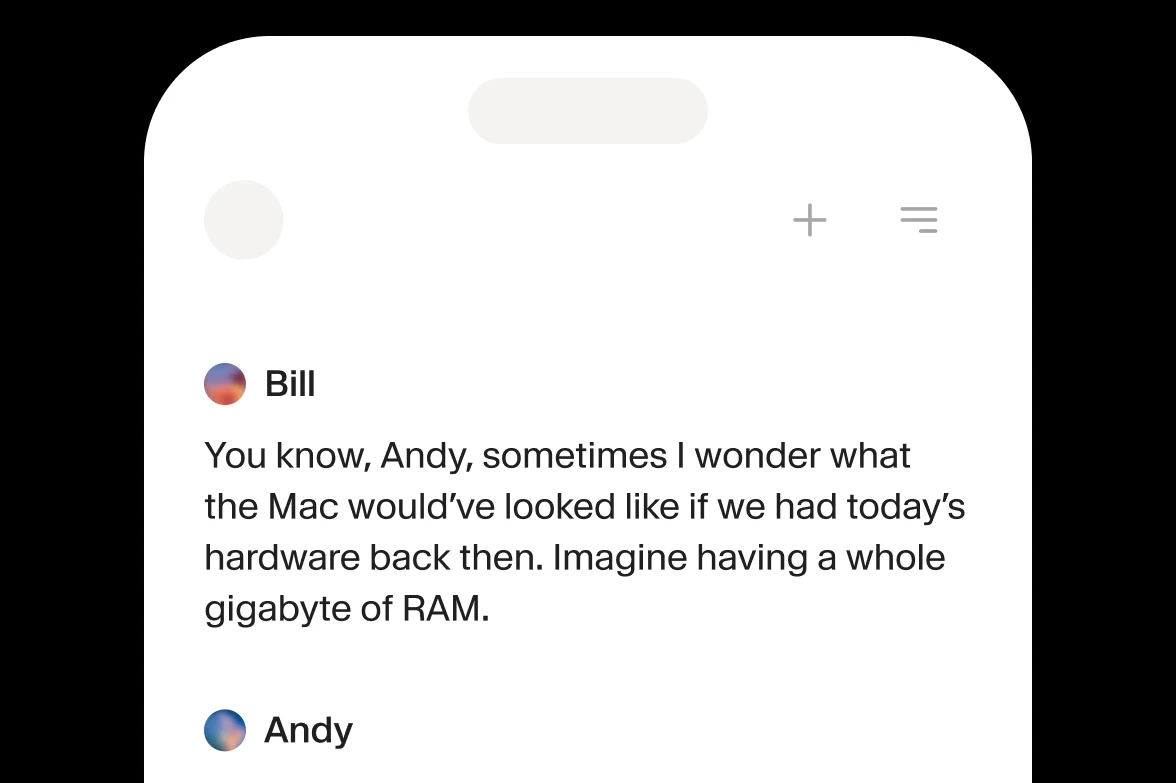
Integrate ElevenLabs Text to Speech (TTS) into your product via APIs or SDKs.


.jpg&w=3840&q=80)

.jpg&w=3840&q=80)



