
Twój kompletny workflow do edycji wideo i audio, dodawania nałożonych głosów i muzyki, transkrypcji na tekst oraz publikacji produkcji z narracją i napisami
Dzięki Text to Speech historie można usłyszeć od razu po publikacji, w różnych głosach i stylach


Text to Speech (TTS) technologia, w swojej istocie, przekształca treści pisane w mowę. W ostatnich latach, dzięki znacznym postępom w uczeniu maszynowym, TTS technologia rozwinęła się do poziomu, gdzie syntezowana mowa jest praktycznie nie do odróżnienia od ludzkiej narracji. Realizm i ekspresja osiągnięte przez nowoczesne TTS systemy oferują niespotykany potencjał, szczególnie dla branży wydawniczej.
Dla wydawców wiadomości, dźwiękowy krajobraz to nie tylko nowa dziedzina, ale konieczność dla zaangażowania. Rozwijanie obecności audio zwiększa retencję użytkowników i ich zadowolenie. Tradycyjna droga wymagałaby zatrudnienia aktorów głosowych lub reporterów do narracji, co nie jest ani czasowo, ani kosztowo efektywne. Dzięki Text to Speech, historie mogą być natychmiastowo udźwiękowione po publikacji, zapewniając, że treść pozostaje świeża, istotna i wysokiej jakości.
Jak osiągamy ludzką jakość nawet przy bardzo długich tekstach, to zasługa tego, jak zbudowaliśmy nasz model. Jest on szkolony, by rozumieć co jest mówione i dostosowywać sposób przekazu. Robi to, biorąc pod uwagę nie tylko znaczenie słów, ale także kontekst każdej wypowiedzi.
Tradycyjne algorytmy generowania mowy produkują wypowiedzi zdanie po zdaniu. Jest to mniej wymagające obliczeniowo, ale brzmi od razu robotycznie. Emocje i intonacja często muszą rozciągać się i rezonować przez kilka zdań, by połączyć określony tok myślenia. Ton i tempo przekazują intencję, co sprawia, że mowa brzmi ludzko. Zamiast generować każdą wypowiedź osobno, nasz model uwzględnia otaczający kontekst, utrzymując odpowiedni przepływ i prozodię w całym generowanym materiale. Ta emocjonalna głębia, połączona z doskonałą jakością dźwięku, zapewnia użytkownikom najbardziej autentyczne i przekonujące narzędzie narracyjne.
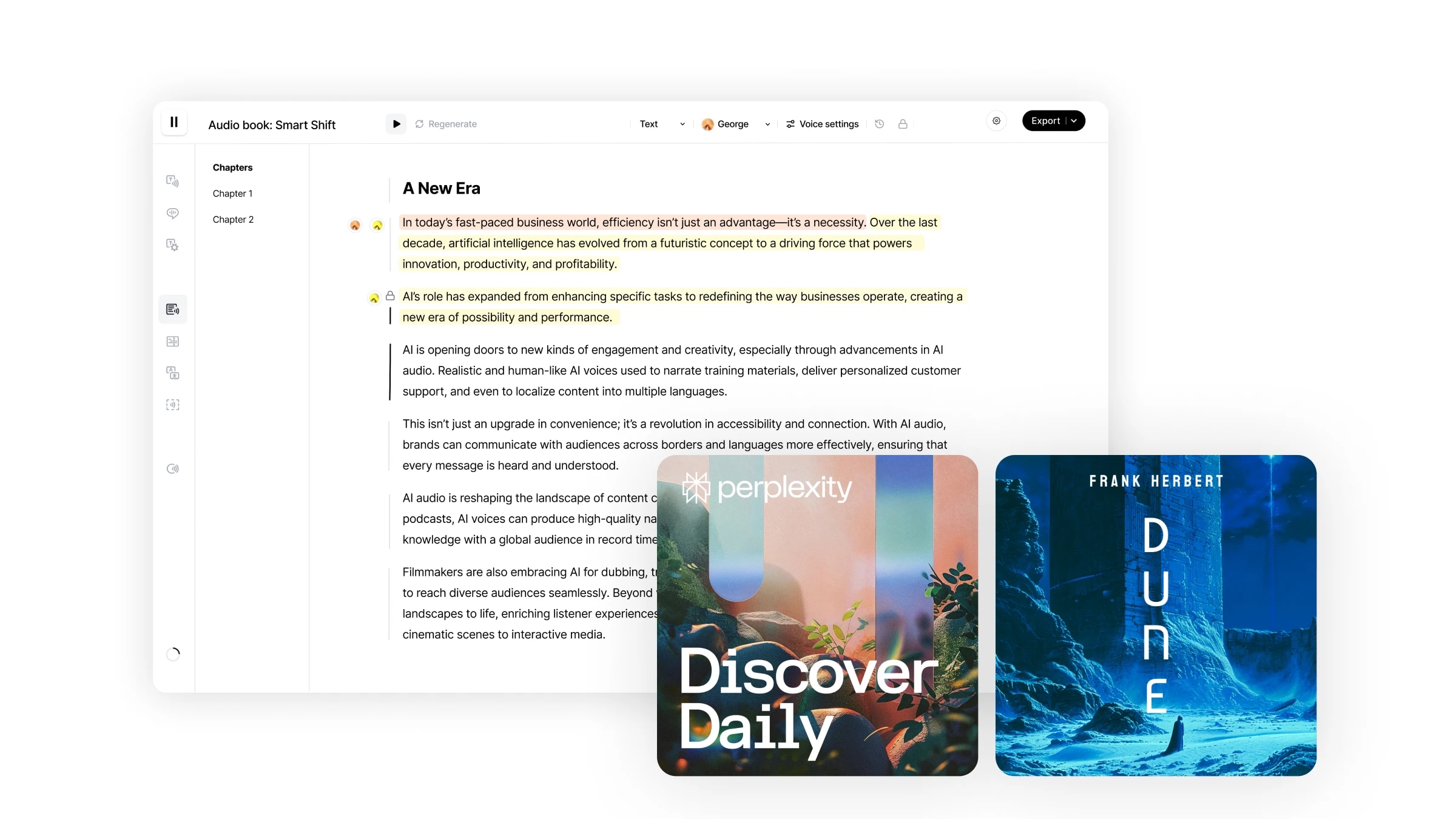
Studio to nasz end-to-end workflow do tworzenia audiobooków w kilka minut. Oferuje niespotykany poziom kontroli nad twoimi kreacjami audio z możliwością regeneracji konkretnych fragmentów audio, przypisywania różnych mówców do określonych fragmentów tekstu, bezpośredniego importu plików w różnych formatach i więcej.
Nawigacja po Studio jest łatwa i intuicyjna.
Studio zapewnia prostą obsługę, podobną do korzystania z Google Docs, z intuicyjnym, zorientowanym na użytkownika interfejsem wspierającym różnorodne funkcje edycji:
Twój kompletny workflow do edycji wideo i audio, dodawania nałożonych głosów i muzyki, transkrypcji na tekst oraz publikacji produkcji z narracją i napisami
Studio współpracuje z Synteza mowy, VoiceLab, i Voice Library, służąc jako kompleksowe rozwiązanie do syntezy długich treści audio. Dodatkowo, jest płynnie zintegrowane z Professional Voice Cloning, Voice Library i naszym wielojęzycznym modelem.
W ElevenLabs, nasze zaangażowanie w innowacje doprowadziło do wprowadzenia nowego wielojęzycznego modelu. Pozwala to na tłumaczenie i udźwiękowienie tej samej narracji w aż 28 językach. Dla wydawców oznacza to niespotykany globalny zasięg, z historiami rezonującymi w różnych kulturach i regionach, wszystko w spójnym i jednolitym głosie.
Obsługiwane języki to teraz: angielski, koreański, niderlandzki, chiński, turecki, szwedzki, indonezyjski, filipiński, japoński, ukraiński, grecki, czeski, fiński, rumuński, duński, bułgarski, malajski, słowacki, chorwacki, klasyczny arabski, polski, niemiecki, hiszpański, francuski, włoski, hindi, portugalski i tamilski.
Nasze własne Voice Design narzędzie zapewnia transformacyjne doświadczenie dla wydawców. Ułatwia tworzenie całkowicie unikalnych głosów na podstawie wybranych parametrów, takich jak wiek, płeć i akcent. Każdy wygenerowany głos jest unikalny, co zapewnia, że wydawcy mogą wybrać konkretny głos, który stanie się synonimem ich marki lub publikacji.
Profesjonalne klonowanie głosu (PVC) technologia w ElevenLabs oferuje kolejny poziom personalizacji. Klonując głosy reporterów publikacji, możemy tworzyć historie audio w ich unikalnych tonach. To nie tylko zapewnia autentyczność, ale także znacznie redukuje koszty i czas poświęcony na tradycyjne procesy nagrywania. Co więcej, nasz wielojęzyczny model jest kompatybilny z Professional Voice Cloning, co zapewnia, że głos reportera może teraz mówić we wszystkich obsługiwanych językach.

I używaj go do filmów, reklam, podcastów i nie tylko
Posłuchaj odcinka podcastu wygenerowanego za pomocą naszego narzędzia Professional Voice Cloning:
Dla wydawców, Professional Voice Cloning (PVC) oferuje liczne korzyści:
W połączeniu z technologią Text to Voice, wydawcy są wyposażeni w nowoczesne narzędzie do tworzenia bogatych, zróżnicowanych i globalnych treści dźwiękowych. Przyjęcie możliwości Professional Voice Cloning Technology to postępowy krok dla wydawców, otwierający wiele możliwości.
Przyszłość wydawnictwa to nie tylko słowo pisane, ale także sposób, w jaki te słowa są przekazywane. Dzięki narzędziom takim jak Text to Voice, wydawcy mają potencjał do rewolucjonizowania dostarczania treści, zapewniając dostępność, unikalność i globalny zasięg. W ElevenLabs jesteśmy na czele tej transformacji, oferując technologię, która toruje drogę do bogatszego, bardziej zróżnicowanego doświadczenia dźwiękowego.
Aktualizacja: od stycznia 2025, Projects nazywa się teraz Studio i jest dostępne dla wszystkich darmowych użytkowników.

Demand for digital tour guides rises with 10k+ tours taken and an average of 53 minutes listening time per session

Supporting 10,000+ research conversations with natural, trustworthy voices
Napędzane przez ElevenLabs Agenci