Zanurz się w świecie, gdzie elokwencja pisanych słów magicznie przekształca się w żywe melodie mowy. Wyobraź sobie krainę, gdzie tekst ożywa, rezonując w różnych akcentach i tonach—od głębokiego brytyjskiego narratora po czarującą kadencję francuskiego opowiadacza—wszystko to za jednym kliknięciem.
To nie narracja futurystycznej powieści, ale fascynujący świat online text-to-speech (TTS) w 2023 roku.
Nie ma wątpliwości, żyjemy w świecie AI, gdzie granica między tekstem pisanym a mówionym się zaciera, dając firmom i osobom możliwość przekształcania treści w realistyczne, porywające audio bez wchodzenia do studia nagrań.
W miarę jak cyfrowy horyzont się rozszerza, wybór jest ogromny, co sprawia, że poszukiwanie idealnego rozwiązania TTS online to ekscytująca przygoda.
Więc, wyruszając w tę podróż, odkryjmy najlepsze platformy text-to-speech tego roku i zobaczmy, jak ElevenLabs wyróżnia się w tej konkurencyjnej arenie.
Czym jest text-to-speech: rzut oka na jego ewolucję
W swojej istocie, zamiana tekstu na mowę (TTS) to alchemiczny proces przekształcania treści pisanej w słyszalną mowę. Jednak w ostatnich latach ten obszar przeszedł metamorfozę, głównie dzięki postępom w sztucznej inteligencji.
Minęły czasy robotycznych, monotonnych głosów przypominających wczesne systemy komputerowe. Dziś, rezonujące nuty zamiana tekstu na mowę są tak dopracowane, tak realistyczne, że są niemal nie do odróżnienia od ludzkiej mowy. Wypróbuj Eleven v3, nasz najbardziej ekspresyjny model text-to-speech.
Twórz ludzkie głosy z naszym systemem Text to Speech (TTS), stworzonym do wysokiej jakości narracji, gier, wideo i dostępności. Ekspresyjne głosy, wsparcie wielojęzyczne i integracja z API ułatwiają skalowanie od projektów osobistych do firmowych workflow.
Co było katalizatorem tej rewolucji? Postępy w AI i algorytmach głębokiego uczenia. Analizując niuanse w tonie, wysokości i barwie, platformy TTS zasilane AI, takie jak ElevenLabs, stworzyły głosy, które nie tylko naśladują naturalną mowę, ale rezonują z istotą ludzkich emocji.
Ale transformacyjna moc TTS wykracza poza samą jakość dźwięku. Dla firm to złoty klucz otwierający wiele drzwi:
- Tworzenie treści: Marki mogą teraz przekształcać blogi, artykuły i materiały pisane w angażujące treści audio, docierając do osób uczących się słuchowo i tych, którzy wolą słuchać niż czytać.
- Identyfikacja marki: Dzięki cudowi voice cloning, firmy mogą teraz mieć spójny głos marki—dosłownie. Niezależnie od tego, czy odpowiadają na pytania, czy prowadzą użytkowników, ten głos staje się identyfikatorem, wyróżniającym ich w cyfrowym świecie.
- Interaktywne chatboty: Obsługa klienta i interakcje wkroczyły w przyszłość. Zamiast bezosobowych, pisanych auto-odpowiedzi, klienci mogą rozmawiać z chatbotami zasilanymi AI, które mówią, rozumieją i pomagają—wszystko w czasie rzeczywistym.
- Ekspansja wielojęzyczna: Dystrybucja treści nie jest już ograniczona barierami językowymi. Dzięki rozbudowanym bibliotekom językowym, narzędzia TTS umożliwiają firmom łączenie się z globalnymi odbiorcami, artykułując przekazy w językach, które rezonują z słuchaczami na całym świecie.
Krótko mówiąc, krajobraz komunikacji przechodzi tektoniczną zmianę. W miarę jak technologia TTS nadal się rozwija, zarówno firmy, jak i osoby prywatne stoją na progu renesansu dźwiękowego. Nowa era, w której słowa nie tylko mają znaczenie—one brzmią życiem.
Kluczowe kryteria oceny oprogramowania TTS
Z ogromem dostępnego dziś oprogramowania text-to-speech, wybór odpowiedniego rozwiązania dla twoich potrzeb może być przytłaczający.
Jednak zrozumienie kluczowych czynników definiujących wyjątkową platformę TTS pozwoli ci podjąć świadomą decyzję.
Oto podstawowe kryteria, które warto rozważyć przy ocenie opcji:
- Jakość głosu: W sercu TTS leży komputerowo generowany głos. Minęły czasy sterylnych, robotycznych tonów. Współcześni użytkownicy pragną syntetycznych głosów, które odzwierciedlają ciepło, niuanse i emocje ludzkiej mowy.
Zadaj sobie pytanie: Czy głos porywa cię swoją autentycznością, czy wyrywa z doświadczenia swoim sztucznym brzmieniem?
- Pokrycie językowe i akcentowe: Nasz świat śpiewa mieszanką języków i tonów. Wiodąca platforma TTS powinna odzwierciedlać tę różnorodność.
Zanurz się w ich repertuarze: Jak rozległy jest ich krajobraz językowy? Czy uchwytują bogactwo akcentów, zapewniając, że treść rezonuje poza granicami?
- Dostosowywalność: Żadne dwa głosy nie są takie same, ani nie powinny być. Solidne narzędzie TTS oferuje bogactwo opcji dostosowywania, pozwalając użytkownikom na regulację prędkości głosu, intonacji, wysokości i więcej. Chodzi o kształtowanie głosu, który jest unikalnie twój, dostosowując się do różnych nastrojów i stylów treści.
- API i integracja: Era cyfrowa wymaga bezproblemowej integracji. Najlepsze rozwiązanie TTS nie będzie działać w izolacji, lecz płynnie wtopi się w twoje istniejące systemy i aplikacje.
Zanurz się w ich dokumentacji API. Czy jest solidna, intuicyjna i dobrze wspierana, ułatwiając proces integracji?
- Koszt: Choć urok funkcji może być kuszący, pragmatyczna strona równania pozostaje: cena. Upewnij się, że oprogramowanie TTS oferuje wartość, która odpowiada twoim ograniczeniom budżetowym, nie rezygnując z niezbędnych funkcji. Chodzi o znalezienie złotego środka między kosztem a możliwościami.
Wyposażony w te kryteria, nie błądzisz bez celu. Jesteś na misji, w poszukiwaniu platformy TTS, która harmonizuje z twoimi unikalnymi potrzebami, wzmacniając głosy w symfonii dźwięku i technologii.
Wiodące rozwiązania TTS online w 2023 roku
Po ustaleniu kluczowych kryteriów oceny, skupmy się na liderach w krajobrazie TTS online. Te platformy nie tylko spełniły, ale często przekroczyły kryteria, ustanawiając złoty standard w technologii text-to-speech.
1. Google Cloud zamiana tekstu na mowę
Obraz: Google
Pochodzący z laboratoriów technologicznego giganta, Google Cloud Text-to-Speech wykorzystuje pełną moc zaawansowanej AI i technologii uczenia maszynowego Google. To rozwiązanie w chmurze oferuje rozległą bibliotekę głosów obejmującą wiele języków, co czyni je prominentnym wyborem dla tych, którzy celują w globalny zasięg.
Jakość głosu: Jedną z niezaprzeczalnych zalet oferty Google jest jakość głosu. Dzięki wykorzystaniu ogromnych zasobów danych Google i pionierskich modeli uczenia maszynowego, generowane głosy wykazują niezwykłe ciepło i naturalność.
Podczas słuchania łatwo zapomnieć, że słyszysz komputerowo generowany głos.
Pokrycie językowe i akcentowe: Różnorodność to tutaj słowo kluczowe. Google Cloud Text-to-Speech odzwierciedla globalny zasięg samego internetu, oferując rozległe wsparcie językowe i akcentowe, zaspokajając potrzeby odbiorców z niemal każdego zakątka świata.
Dostosowywalność: Użytkownicy korzystają z głębokich opcji dostosowywania. Od zmian wysokości po regulacje tempa, ta platforma zapewnia, że głosy są kształtowane, aby pasować do różnych kontekstów i nastrojów.
API i integracja: Jako rozwiązanie w chmurze, jest zaprojektowane do bezproblemowej integracji z różnymi aplikacjami i systemami. Ich API jest solidne i wspierane przez kompleksową dokumentację, upraszczając proces integracji.
Koszt: Choć to potęga pod względem funkcji, koszt może wzrosnąć przy intensywnym użytkowaniu, co sprawia, że potencjalni użytkownicy muszą ocenić model cenowy w kontekście oczekiwanej ilości konwersji treści.
Mocne strony: Rozległe wsparcie językowe i głębokie opcje dostosowywania.
Słabe strony: Koszt może być problemem przy intensywnym użytkowaniu.
2. Amazon Polly
Obraz: Amazon
Amazon Polly jest integralną częścią rozległej machiny Amazon Web Services (AWS). Zaprojektowany, aby przekształcać tekst w dynamiczną i realistyczną mowę, Polly stał się wyborem wielu firm i deweloperów osadzonych w ekosystemie AWS.
Jakość głosu: Choć Amazon poczynił postępy w dziedzinie jakości syntezowanego głosu, wynik z Polly jest dość realistyczny.
Głosy są pozbawione sztywności często kojarzonej z wcześniejszymi wersjami technologii TTS, dostarczając czyste i przyjemne doświadczenia dźwiękowe. Ponownie, na pierwszy plan wysuwa się wyrafinowanie komputerowo generowanego głosu.
Pokrycie językowe i akcentowe: Odzwierciedlając swój globalny zasięg, Amazon Polly oferuje imponującą gamę języków i akcentów. Niezależnie od tego, czy docierasz do odbiorców w Ameryce Północnej, Europie czy Azji, Polly zapewnia, że twój przekaz rezonuje w rodzimych językach twoich słuchaczy.
Dostosowywalność: Choć Polly oferuje regulacje w zakresie prędkości i wysokości, nieco ustępuje niektórym konkurentom w dziedzinie kształtowania głosu. Niektórzy użytkownicy mogą uznać opcje dostosowywania za niewystarczająco rozbudowane lub szczegółowe.
API i integracja: Jedną z wyróżniających się cech Polly jest jej bezproblemowa integracja z innymi usługami AWS. Biorąc pod uwagę rozległe wykorzystanie AWS w świecie biznesu, oferuje to prostą ścieżkę dla tych, którzy już są na pokładzie ekosystemu Amazon.
Dokumentacja API jest szczegółowa i przyjazna dla użytkownika, torując drogę do bezproblemowego włączenia do różnych projektów.
Koszt: Będąc pod parasolem AWS, model cenowy Polly jest zgodny z filozofią płatności za użycie Amazon. Choć może to być opłacalne dla sporadycznych użytkowników, użytkownicy o dużym wolumenie muszą być świadomi rosnących kosztów, zwłaszcza jeśli korzystają z wielu usług AWS jednocześnie.
Mocne strony: Łatwa integracja z usługami AWS, szeroki wybór języków.
Słabe strony: Mniejsza elastyczność w dostosowywaniu głosu w porównaniu do niektórych konkurentów.
3. IBM Watson zamiana tekstu na mowę
Obraz: IBM
Potomek szanowanej linii sztucznej inteligencji IBM, Watson Text to Speech łączy bogatą historię firmy w dziedzinie komputerów i AI. Zaprojektowany, aby dostarczać wysokiej jakości mowę, ta platforma wyróżnia się nie tylko swoją techniczną biegłością, ale także głębią emocji, które jej głosy potrafią przekazać.
Jakość głosu: Znakiem rozpoznawczym Watson Text to Speech jest naturalność generowanych głosów.
Unikając monotonicznej dostawy starszych systemów TTS, Watson oferuje dźwięk, który jest ciepły, angażujący i dziwnie przypominający ludzkie głosy. Dodatkowym atutem jest jego zdolność do przekazywania ekspresji, co sprawia, że wynik mowy jest bardziej dynamiczny i kontekstowo odpowiedni.
Pokrycie językowe i akcentowe: Choć Watson oferuje gamę języków i akcentów, nie dorównuje rozległym bibliotekom swoich odpowiedników w Google i Amazon. Jednak języki, które obsługuje, są renderowane z dużą starannością i autentycznością.
Dostosowywalność: Poza standardowymi parametrami, takimi jak wysokość i prędkość, siła Watsona leży w jego opcjach ekspresyjnych. Użytkownicy mogą tworzyć mowę, która nie tylko jest technicznie dokładna, ale także emocjonalnie rezonująca, czy to radość, smutek, czy entuzjazm.
API i integracja: Watson Text to Speech jest zbudowany dla nowoczesnego internetu. Jego API jest solidne i zaprojektowane do bezproblemowej integracji z różnymi platformami i systemami. Szczegółowa dokumentacja pomaga deweloperom w zapewnieniu płynnej implementacji.
Koszt: Struktura cenowa IBM nie jest dokładnie przejrzysta, wymagane jest konto, aby zobaczyć koszty, jednak można doświadczyć technologii dzięki darmowej wersji demo.
Potencjalni użytkownicy powinni rozważyć funkcje w kontekście swoich ograniczeń budżetowych, zwłaszcza w porównaniu z ofertami, które mają szerszy wybór głosów i języków.
Mocne strony: Oferuje opcje ekspresyjne, które przekazują emocje.
Słabe strony: Ograniczona liczba głosów w porównaniu do Google i Amazon.
ElevenLabs: jak się wyróżnia?
Obraz: ElevenLabs
Dzięki unikalnemu połączeniu AI voice cloning i najwyższej klasy możliwości text-to-speech, ElevenLabs wyłania się jako lider w krajobrazie technologii TTS. Zakorzeniona w dążeniu do wykorzystania najlepszej AI do generowania realistycznego, kontekstowego audio, platforma obiecuje niezrównane doświadczenie dźwiękowe.
Jakość głosu: Czerpiąc z najnowocześniejszej technologii AI, ElevenLabs dostarcza mowę, która nie tylko naśladuje naturalną ludzką mowę, ale rozumie i rezonuje z niuansami tekstu.
Ten podwyższony poziom klarowności i jakości zapewnia najwyższej klasy doświadczenie słuchowe przy doskonałej jakości 96 kbps.
Pokrycie językowe i akcentowe: Obsługując globalną bazę użytkowników, wielojęzyczna zdolność ElevenLabs obejmuje imponujące 28 języków, zachowując unikalne cechy i autentyczność w każdym języku.
Niezależnie od tego, czy przekazujesz niuanse, czy rodzime idiomy, autentyczność języka pozostaje niezachwiana.
Dostosowywalność: Od eksploracji rozległej Voice Library po precyzyjne dostosowywanie wyników głosowych, użytkownicy otrzymują narzędzia do opanowania doskonałego audio. Niezależnie od tego, czy dostosowujesz ustawienia głosu dla klarowności, zwiększasz podobieństwo do mówcy, czy nawet akcentujesz style głosu – platforma ElevenLabs jest zbudowana dla niezrównanej ekspresji.
API i integracja: ElevenLabs szczyci się swoim zaawansowanym API, które, w połączeniu z ultra-niską latencją i kompleksowym wsparciem, zapewnia deweloperom bezproblemowe doświadczenie integracji.
Dzięki strumieniowemu audio dostarczanemu w mniej niż sekundę i wspierającej społeczności deweloperów, integracja ElevenLabs staje się drugą naturą.
Koszt: Platforma oferuje zrównoważony i konkurencyjny model cenowy, co czyni ją dostępnym wyborem dla różnych segmentów użytkowników. To, w połączeniu z zaawansowanymi funkcjami, daje ElevenLabs przewagę w analizie kosztów do funkcji.
Mocne strony: Unikalna funkcja Voice Cloning wyróżnia się, oferując użytkownikom niezrównane, spersonalizowane doświadczenie TTS. Ponadto, wysokiej jakości wynik, wspierany przez zaawansowaną AI i zdolności emocjonalne, pokazuje zaangażowanie ElevenLabs w doskonałość.
Efektywna produkcja treści, zaawansowane API i silny nacisk na kontekstowy TTS dodatkowo wzmacniają ofertę platformy.
Słabe strony: Choć ElevenLabs wyróżnia się w wielu obszarach, potencjalni użytkownicy mogą pragnąć jeszcze szerszej różnorodności głosów w porównaniu do gigantycznych konkurentów, takich jak Google i Amazon.
Odkrywając przyszłość audio z ElevenLabs
W miarę jak poruszamy się w erze AI i jej roli w ciągłej ewolucji technologii text-to-speech, niektóre platformy wyróżniają się nie tylko swoimi innowacjami, ale także doświadczeniami, które tworzą.
ElevenLabs to więcej niż narzędzie—jest to rewolucja dźwiękowa.
Stworzona przez entuzjastów zaangażowanych w pionierską falę audio napędzanego AI, platforma płynnie łączy wyjątkowe doświadczenie użytkownika z niezachwianymi etycznymi zasadami AI.
Niezależnie od tego, czy jesteś doświadczoną firmą, początkującym twórcą treści, czy kimś ciekawym niuansów TTS, ElevenLabs zaprasza cię do symfonii przyszłości.
Gotowy na tę dźwiękową podróż? Zanurz się głębiej w ElevenLabs' Text-to-Speech i zobacz, jak przyszłość się rozwija.
Czym Eleven się różni?
Jak osiągamy ludzką jakość nawet przy bardzo długich tekstach, wynika z tego, jak zbudowaliśmy nasz model. Jest on szkolony, aby rozumieć co jest mówione i dostosowywać sposób dostarczania. Robi to, biorąc pod uwagę nie tylko znaczenie słów, ale także kontekst otaczający każdą wypowiedź.
Tradycyjne algorytmy generowania mowy produkują wypowiedzi na zasadzie zdanie po zdaniu. Jest to mniej wymagające obliczeniowo, ale od razu brzmi robotycznie. Emocje i intonacja często muszą się rozciągać i rezonować przez kilka zdań, aby połączyć określony tok myślenia. Ton i tempo przekazują intencję, co naprawdę sprawia, że mowa brzmi ludzko. Zamiast generować każdą wypowiedź osobno, nasz model bierze pod uwagę otaczający kontekst, utrzymując odpowiedni przepływ i prozodię w całym generowanym materiale. Ta emocjonalna głębia, połączona z najwyższą jakością dźwięku, zapewnia użytkownikom najbardziej autentyczne i porywające narzędzie narracyjne.
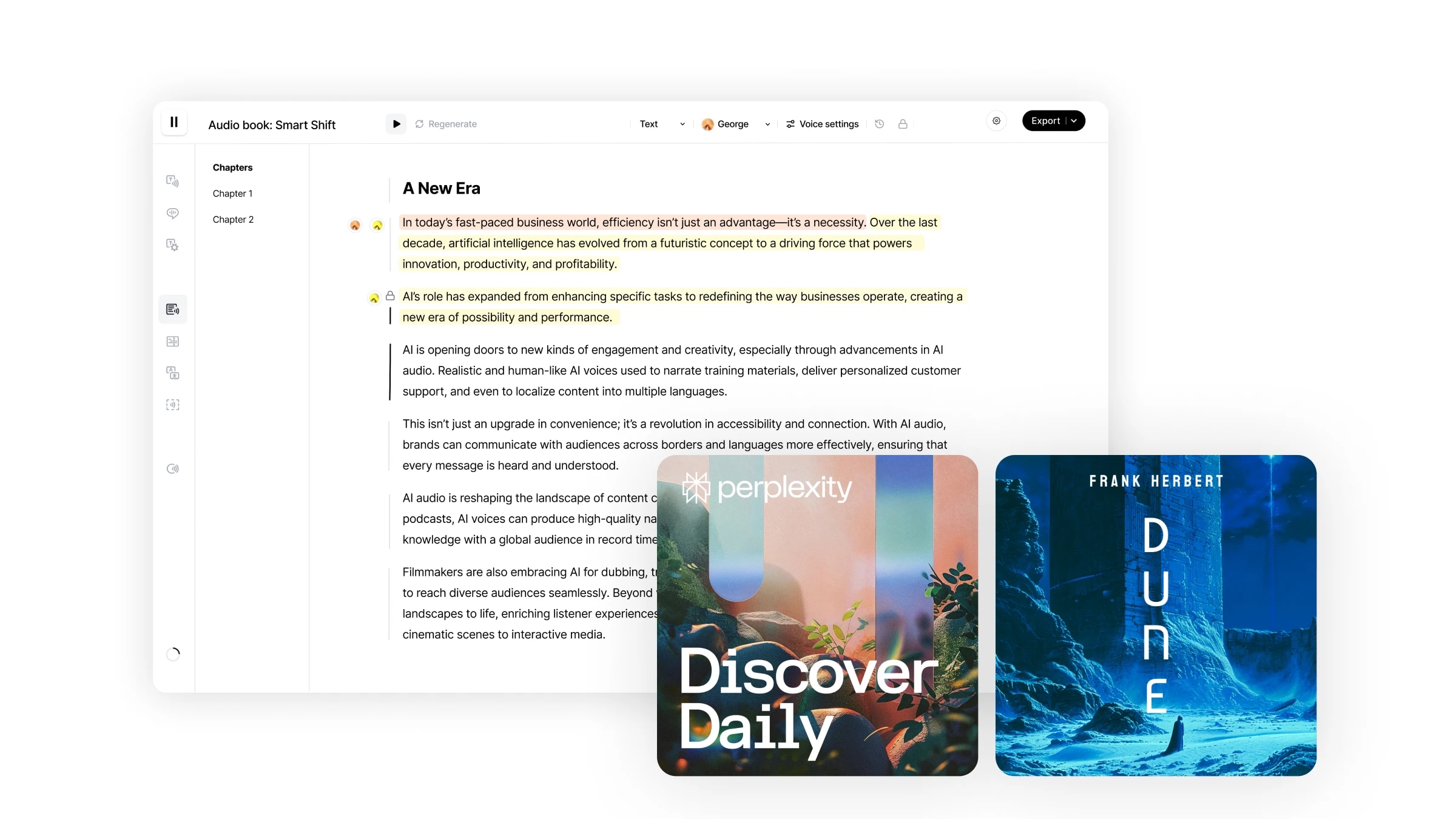
Generowanie treści długiej formy z Studio
Studio to nasz end-to-end workflow do tworzenia audiobooków w kilka minut. Oferuje niespotykany poziom kontroli nad twoimi kreacjami audio z możliwością regeneracji konkretnych fragmentów audio, przypisywania różnych mówców do określonych fragmentów tekstu, bezpośredniego importu plików w różnych formatach i więcej.
Twój kompletny workflow do edycji wideo i audio, dodawania nałożonych głosów i muzyki, transkrypcji na tekst oraz publikacji produkcji z narracją i napisami
Pierwsze kroki
Nawigacja po Studio jest łatwa i intuicyjna.
- Wybierz Studio z menu na górnym pasku.
- Kliknij Utwórz Nowy Projekt.
- Wybierz, jak chcesz zainicjować swój Projekt.
- Zacznij tworzyć swój tekst.
- Kliknij Konwertuj, aby przetworzyć cały Projekt naraz, lub użyj Odtwórz i Regeneruj, aby przetestować konkretne fragmenty.
Najważniejsze funkcje
Studio zapewnia prostą obsługę użytkownika, podobną do korzystania z Google Docs, z intuicyjnym, zorientowanym na użytkownika interfejsem wspierającym różnorodne funkcje edycji:
- Pełna konwersja: Użyj jednego przycisku, aby przetworzyć cały Projekt naraz, lub użyj Odtwórz i Regeneruj, aby przetestować konkretne fragmenty.
- Przypisywanie mówców: Przypisz różne fragmenty tekstu do różnych mówców; wybierz domyślne głosy dla nagłówków i akapitów.
- Regeneracja fragmentów audio: Bezproblemowo regeneruj konkretne segmenty w większych fragmentach audio, zachowując kontekst.
- Wstawianie pauz (dostępne w tym tygodniu): Ręcznie dostosuj długość pauz (do 3s początkowo) między segmentami mowy, aby dostroić tempo.
- Segmentacja według rozdziału: Strukturyzuj swój tekst na sekcje, aby skupić się na konkretnym fragmencie jeden po drugim.
- Zapisz i wznow postęp: Wygodnie wstrzymaj swoją pracę i wznow dokładnie tam, gdzie skończyłeś.
- Importuj pliki: Studio obsługuje pliki .epub, .pdf i .txt, a także URL-e dla bardziej płynnego workflow
- Inteligentna regeneracja: Podczas wznawiania pracy nad już wygenerowanym projektem, zostaniesz obciążony kosztami tylko za regenerację zmienionych fragmentów, a nie całego projektu
Kompatybilność
Studio stoi obok Synteza mowy, VoiceLab, i Voice Library, służąc jako kompleksowe rozwiązanie do syntezy długiej formy audio. Dodatkowo, jest płynnie zintegrowane z Professional Voice Cloning, Voice Library i naszym modelem wielojęzycznym.
- Profesjonalne Voice Cloning: generuj długą formę treści audio w swoim własnym głosie. Możesz także udostępniać swój profesjonalny klon głosu za pośrednictwem Voice Library i zdobywać nagrody za postacie, gdy inni tworzą projekty używając twojego głosu.
- Voice Library: Wybierz idealny głos dla swojej narracji spośród niezliczonych głosów stworzonych przez naszą społeczność. Wybierz spośród szerokiej gamy narratorów: epicki, baryton, alt, tenor, nosowy, chrapliwy, krzyczący, dziwny, szorstki, zły, i więcej. Idealny, niezależnie od tego, czy potrzebujesz głosu dorosłego mężczyzny czy kobiety, starszego mężczyzny czy kobiety, mądrego mentora, futurystycznego robota, czy poszukiwacza przygód.
- Eleven Multilingual: Niezależnie od tego, czy wybierzesz gotowy głos, sklonowany głos czy swój własny głos, możesz płynnie mówić we wszystkich językach obsługiwanych przez nasz model wielojęzyczny.
Poszerzanie horyzontów: Nasz nowy model wielojęzyczny
W ElevenLabs nasze zaangażowanie w innowacje doprowadziło do uruchomienia nowego modelu wielojęzycznego. To pozwala na tłumaczenie i wokalizację tej samej narracji w nawet 28 językach. Dla wydawców oznacza to niespotykany globalny zasięg, z historiami rezonującymi w różnych kulturach i regionach, wszystko w spójnym i jednolitym głosie.
Obsługiwane języki to teraz: angielski, koreański, niderlandzki, chiński, turecki, szwedzki, indonezyjski, filipiński, japoński, ukraiński, grecki, czeski, fiński, rumuński, duński, bułgarski, malajski, słowacki, chorwacki, klasyczny arabski, polski, niemiecki, hiszpański, francuski, włoski, hindi, portugalski i tamilski.
Voice Design: Tworzenie unikalnych narracji
Nasze własne Voice Design narzędzie zapewnia transformacyjne doświadczenie dla wydawców. Ułatwia tworzenie całkowicie unikalnych głosów na podstawie wybranych parametrów, takich jak wiek, płeć i akcent. Każdy wygenerowany głos jest unikalny, zapewniając, że wydawcy mogą wybrać konkretny głos, który stanie się synonimem ich marki lub publikacji.
Efektywność dzięki Professional Voice Cloning
Profesjonalne Voice Cloning (PVC) technologia w ElevenLabs oferuje kolejną warstwę dostosowywania. Klonując głosy reporterów publikacji, możemy produkować historie audio w ich unikalnych tonach. To nie tylko zapewnia autentyczność, ale także znacznie redukuje koszty i czas poświęcony na tradycyjne procesy nagrywania. Co więcej, nasz model wielojęzyczny jest kompatybilny z Professional Voice Cloning, zapewniając, że głos reportera może teraz mówić we wszystkich obsługiwanych językach.
I używaj go do filmów, reklam, podcastów i nie tylko
Posłuchaj odcinka podcastu wygenerowanego za pomocą naszego narzędzia Professional Voice Cloning:
Jak wydawcy mogą skorzystać z Voice Cloning
Dla wydawców, Professional Voice Cloning (PVC) oferuje liczne korzyści:
- Wyrazisty głos marki: Klonując unikalny głos, wydawcy mogą ustanowić rozpoznawalną markę dźwiękową, wyróżniając swoją treść.
- Spójność treści: Klonowanie głosu zapewnia spójny styl wokalny w wielu artykułach i publikacjach bez potrzeby różnych aktorów głosowych.
- Efektywność: Potrzebujesz poprawki głosu? Zamiast ponownego nagrywania, po prostu wygeneruj wymaganą narrację z klonowanym głosem, oszczędzając czas i utrzymując jednolitość.
- Zwiększone zaangażowanie: Dla globalnych czytelników, znajomy klonowany głos zwiększa połączenie i zaufanie do treści.
W połączeniu z technologią Text to Voice, wydawcy są wyposażeni w nowoczesny zestaw narzędzi do produkcji bogatych, zróżnicowanych i globalnych treści dźwiękowych. Przyjęcie możliwości Professional Voice Cloning Technology to postępowy krok dla wydawców, otwierający mnóstwo możliwości.
Aktualizacja: od stycznia 2025, Projects nazywa się teraz Studio i jest dostępne dla wszystkich darmowych użytkowników.