Czym jest Generative AI Audio? Wszystko, co musisz wiedzieć
AI Audio zmienia dźwięk i przemysł. Dowiesz się o text-to-speech, voice cloning, tłumaczeniu wideo i innych nowinkach – zobaczysz, jak wpływa to na biznes.
Wprowadzenie do AI Audio
Z nowymi technologiami, które czynią niemożliwe rzeczywistością, trudno nadążyć. Ten artykuł pomoże ci zrozumieć szybko rozwijający się świat audio napędzanego AI i pokaże, jak może ci to przynieść korzyści.
Zaczniemy od eksploracji AI text-to-speech (AI TTS) – ekscytującej technologii, która rewolucjonizuje sposób, w jaki interakcjonujemy z audio. Ale na tym nie koniec; omówimy cały obszar generatywnego AI audio, od voice cloning po AI dubbing i więcej.
Audio Napędzane AI – Dlaczego Jest Ważne
W tym przewodniku poznasz potężne możliwości technologii audio napędzanych AI i zobaczysz, jak zmieniają one różne branże. Ta technologia oferuje wiele korzyści i przekształca krajobraz generacji audio.
Najważniejsza jest szybkość i dokładność AI TTS, które mogą tworzyć głosy praktycznie nieodróżnialne od ludzkiej mowy. Ostatnio otworzyło to produkcję audio dla szerszej publiczności, oferując tańszą alternatywę dla tradycyjnego nagrywania głosu i dubbingu.
AI audio odgrywa również ogromną rolę w zwiększaniu dostępności, czyniąc treści cyfrowe bardziej inkluzywnymi. Przekłada się to na wzbogacone doświadczenia użytkowników na różnych platformach, oferując dynamiczny wymiar dźwiękowy interakcji użytkowników. Ten wpływ generatywnego AI audio jest szczególnie widoczny w filmie, grach i tworzeniu treści, gdzie szybko zyskuje popularność.
Zanim zagłębimy się w AI audio, upewnijmy się, że wszyscy jesteśmy na tej samej stronie. Zbadamy każdy termin dalej, ale zaczniemy od prostych definicji kluczowych pojęć.
AI Generative Audio - Key Terms
AI Generative Audio - Key Terms
Term
Definition
AI text-to-speech (AI TTS):
Converts written text into lifelike spoken words using artificial intelligence algorithms and voice synthesis technology.
AI generative voices:
Are lifelike, customizable voices created by artificial intelligence models that provide an array of pitches and accents for diverse applications.
AI voice cloning:
Involves creating an artificial replica of a person's voice by employing advanced AI algorithms and deep learning methods.
AI dubbing:
Uses artificial intelligence to seamlessly replace audio content in movies, videos, or games – often for localization or translation.
AI music:
Creates and enhances musical pieces through generative AI models, machine learning techniques, and specialized music generation algorithms.
Możliwości AI Audio
Technologie audio napędzane AI to więcej niż tylko modne hasła; zmieniają sposób, w jaki doświadczamy i interakcjonujemy z audio. Codziennie wspierane są nowe branże, ale aby podkreślić kilka przykładów z życia: wczesni użytkownicy cieszą się ulubionymi książkami czytanymi przez wybranego narratora, AI dubbing anime zwiększa dostępność, a AI generowane podcasty zyskują popularność.
Czytaj dalej, aby dowiedzieć się, jak działa generatywne audio i zrozumieć jego wpływ na różne branże. Rozpocznijmy naszą podróż od bliższego spojrzenia na AI text-to-speech.
Technologie audio napędzane AI rozwijają się niesamowicie szybko. Jednak aby naprawdę docenić te innowacje, ważne jest zrozumienie fundamentu, na którym są zbudowane. Wkraczamy w świat AI text-to-speech (AI TTS). W tej sekcji zbadamy historię, funkcjonalność i znaczący wpływ technologii zamiany tekstu na głos na różne branże.
AI text-to-speech to złożona technologia o prostym celu – przekształca pisemne teksty w realistyczne słowa mówione. Osiąga to dzięki zaawansowanym algorytmom i technikom syntezy głosu. Tworzenie treści, konsumpcja i dostępność zostały przekształcone przez tę nową erę AI audio.
Twórz ludzkie głosy z naszym systemem Text to Speech (TTS), stworzonym do wysokiej jakości narracji, gier, wideo i dostępności. Ekspresyjne głosy, wsparcie wielojęzyczne i integracja z API ułatwiają skalowanie od projektów osobistych do firmowych workflow.
Podróż Przez Historię
Aby naprawdę zrozumieć ogrom postępu AI TTS, warto odbyć krótką podróż przez jego historię. Technologia zamiany tekstu na mowę przeszła długą drogę od swoich początków, kiedy syntezowane głosy często brzmiały robotycznie i bez emocji.
Wysiłki naśladowania ludzkiej mowy sięgają wieków, z różnymi próbami w XIX wieku, które obejmowały mechaniczne struny głosowe, języki i usta. Te wczesne próby były niezdarne i bardzo ograniczone w swoim wydaniu. Pierwsze udane elektroniczne próby TTS pojawiły się pod koniec lat 50., ale nawet nowsze przykłady nie dorównują jakości, którą teraz uważamy za standard. Weźmy pod uwagę ikoniczny głos Stephena Hawkinga lub sztuczny ton używany w wczesnych systemach nawigacji samochodowej:
„Proszę skręcić w lewo, aby dotrzeć do celu.”
W tamtym czasie ten poziom syntezowanej mowy był uważany za nowoczesny. Dziś AI TTS przynosi poziom realizmu do generacji głosu, który kiedyś był nie do pomyślenia – nawet przekazując emocje.
Jak Działa AI TTS?
W sercu AI TTS leży zdolność do analizy tekstu i zrozumienia jego niuansów. Pomyśl o tym, jak czytasz zdanie – intuicyjnie dostrzegasz, gdzie intonacja powinna wzrosnąć i opaść, jak powszechne frazy powinny płynąć z języka i rozumiesz, jak interpunkcja wpływa na ogólną dostawę zdania.
Rozwój AI to ogromne pole, ale na wysokim poziomie kluczowe były głębokie uczenie i sieci neuronowe. Te postępy umożliwiają nowoczesnym modelom AI TTS rozszyfrowanie tekstu, określenie odpowiednich intonacji i syntezowanie ich w słowa mówione. Proces ten obejmuje szkolenie AI na ogromnych zbiorach danych ludzkiej mowy, co pozwala jej generować głosy, które nie tylko są nieodróżnialne od ludzkich, ale także potrafią komunikować uczucia i złożone znaczenia.
Podstawa dla Generatywnego AI Audio
AI TTS jest imponujące samo w sobie, ale jego wartość naprawdę staje się widoczna, gdy jest używane jako fundament dla bardziej złożonych programów AI audio. Jest to kamień węgielny, na którym budowane są inne narzędzia generatywnego AI audio. Naturalne, realistyczne głosy produkowane przez AI TTS stają się surowym materiałem dla aplikacji takich jak voice cloning, dubbing i wiele więcej.
Wpływ AI TTS na Różnorodne Branże
Zrozumienie AI text-to-speech jako fundamentu generatywnego AI audio jest kluczowe dla docenienia pełnego potencjału tej technologii. Z bogatą historią, imponującą funkcjonalnością i szerokim wpływem, AI TTS tworzy scenę dla transformacyjnych technologii, które zbadamy dalej.
W miarę jak AI staje się bardziej biegłe w rozumieniu złożonych danych wejściowych, różnice między modelami audio, text-to-image i chatbotami znikną, pozwalając AI na wykonywanie zadań między mediami bezproblemowo.” – Ignaz Kowalczuk, Szef Komunikacji, ElevenLabs
Od AI voiceoverów w edukacji i rozrywce po konwersacyjne, realistyczne głosy chatbotów w opiece zdrowotnej i obsłudze klienta – AI TTS pojawia się w wielu branżach. W nadchodzących sekcjach przyjrzymy się bliżej, jak efektywność i jakość AI TTS wspierają innowacje audio w każdej z tych branż.
Czytaj dalej, aby odkryć intrygujący (i czasami przerażający) świat AI voice cloning i jak zmienia on nasze postrzeganie reprodukcji głosu.
Tworzenie Realistycznych Głosów: AI Voice Cloning i Generatywne Głosy
Istnieją dwa kluczowe rozwinięcia napędzające innowacje w tej przestrzeni: AI voice cloning i generatywne głosy. W tej sekcji dowiesz się, jak możemy tworzyć realistyczne głosy za pomocą zaawansowanych modeli sztucznej inteligencji i otrzymasz uproszczone wyjaśnienie, co dzieje się za kulisami.
Tworzenie sztucznej repliki głosu osoby to cel voice cloning – chcemy stworzyć cyfrową kopię głosu, która jest nieodróżnialna od oryginału. Jest to możliwe dzięki wykorzystaniu najnowocześniejszych algorytmów i technik głębokiego uczenia.
Nasze oparte na AI voice cloning działa trochę jak utalentowany naśladowca. Wyobraź sobie zdolnego mimika, który potrafi perfekcyjnie kopiować czyjś głos i wzorce mowy. Możesz myśleć o naszej technologii jako o cyfrowej formie tego naśladowcy.
Oto jak to działa: Najpierw mamy coś, co nazywa się „enkoderem mówcy”. Pomyśl o tym jak o naśladowcy słuchającym głosu osoby i rozumiejącym jej unikalne cechy. Uczy się, jak mówią, ich tonacji, intonacji i akcentu.
Następnie mamy „generator”. To tutaj naśladowca bierze wszystko, czego się nauczył, i zaczyna mówić za osobę. To tak, jakby nosili maskę głosu tej osoby i mówili każdy tekst, który im podasz, dokładnie tak, jak zrobiłby to oryginalny mówca.
Ale bez informacji zwrotnej moglibyśmy skończyć z bardzo złej jakości głosami, więc mamy też „dyskryminator”. Ta część działa jak sędzia, decydując, czy głos naśladowcy brzmi prawdziwie czy fałszywie. Jeśli nie naśladuje dokładnie oryginalnego głosu, zostaje odrzucony, a inne części są informowane, aby spróbować ponownie.
Szkoląc te trzy części na dużych zbiorach danych mowy, nasz oparty na AI generator głosu staje się mistrzem naśladowania – rozumie wszystkie niuanse, które czynią głosy unikalnymi. Generowane przez niego głosy są tak realistyczne, że łatwo można je pomylić z prawdziwą osobą mówiącą.
To otwiera drzwi do wielu zastosowań, od asystentów głosowych naśladujących znane osobistości po spersonalizowane narracje dla audiobooków. Kiedyś ograniczona do science fiction, zdolność do replikacji głosów z wysoką wiernością jest teraz codzienną rzeczywistością.
Chcesz Sklonować Swój Głos?
Odwiedź nasze Voice Lab, aby stworzyć swój pierwszy sklonowany głos. Wystarczy 1-minutowa próbka audio, aby wygenerować replikę twojego głosu.
I używaj go do filmów, reklam, podcastów i nie tylko
Generatywne Głosy: Tworzenie Unikalnych i Dostosowywalnych Tonów
Generatywne głosy reprezentują szczyt syntezy AI audio. Modele sztucznej inteligencji napędzają syntetyczny generator głosu, który można precyzyjnie dostosować oferując szeroki zakres tonacji, akcentów i tonów. Rezultatem jest niemal nieograniczony zestaw różnorodnych, realistycznych głosów, które można dostosować do różnych zastosowań.
Generatywne głosy AI wykorzystują podobne procesy generacji audio w sieciach neuronowych i głębokiego uczenia, ale „enkoder mówcy” jest sztucznie generowany na podstawie wymagań głosowych przekazanych do niego. Ponieważ te modele są szkolone na ogromnych zbiorach danych ludzkiej mowy, potrafią uchwycić niuanse języka mówionego i subtelności emocji. Wynikiem jest nieograniczona paleta głosów, które mogą przekazywać szeroki zakres uczuć, od ekscytacji po empatię. To czyni je idealnymi do zastosowań, gdzie ważna jest emocjonalna ekspresja.
Zastosowania i Scenariusze dla Generatywnych Głosów
Generatywne głosy AI oferują wiele zastosowań w różnych branżach.
W rozrywce ożywiają animowane postacie autentycznie brzmiącymi dialogami.
Asystenci cyfrowi mogą rozmawiać z użytkownikami w naturalny i angażujący sposób.
Twórcy treści mogą tworzyć nowe materiały szybciej, taniej i utrzymywać stałą wysoką jakość.
Firmy mogą zwiększać zaangażowanie użytkowników i dostępność, dodając ludzki akcent do zautomatyzowanych usług.
Sprawdź Głosy Wygenerowane przez Naszych Użytkowników
Dlaczego nie poświęcić minuty na przeglądanie niektórych głosów generowanych przez użytkowników? Narzędzia do wyszukiwania i filtrowania ułatwiają znalezienie idealnego głosu.
Twórz ludzkie głosy z naszym systemem Text to Speech (TTS), stworzonym do wysokiej jakości narracji, gier, wideo i dostępności. Ekspresyjne głosy, wsparcie wielojęzyczne i integracja z API ułatwiają skalowanie od projektów osobistych do firmowych workflow.
To tylko niewielka próbka sposobów, w jakie generatywne głosy AI są wykorzystywane do tworzenia lepszych doświadczeń dla użytkowników końcowych. Czytaj dalej, aby odkryć wpływ realistycznych generatywnych głosów w dziedzinach filmu, gier, tworzenia treści i więcej.
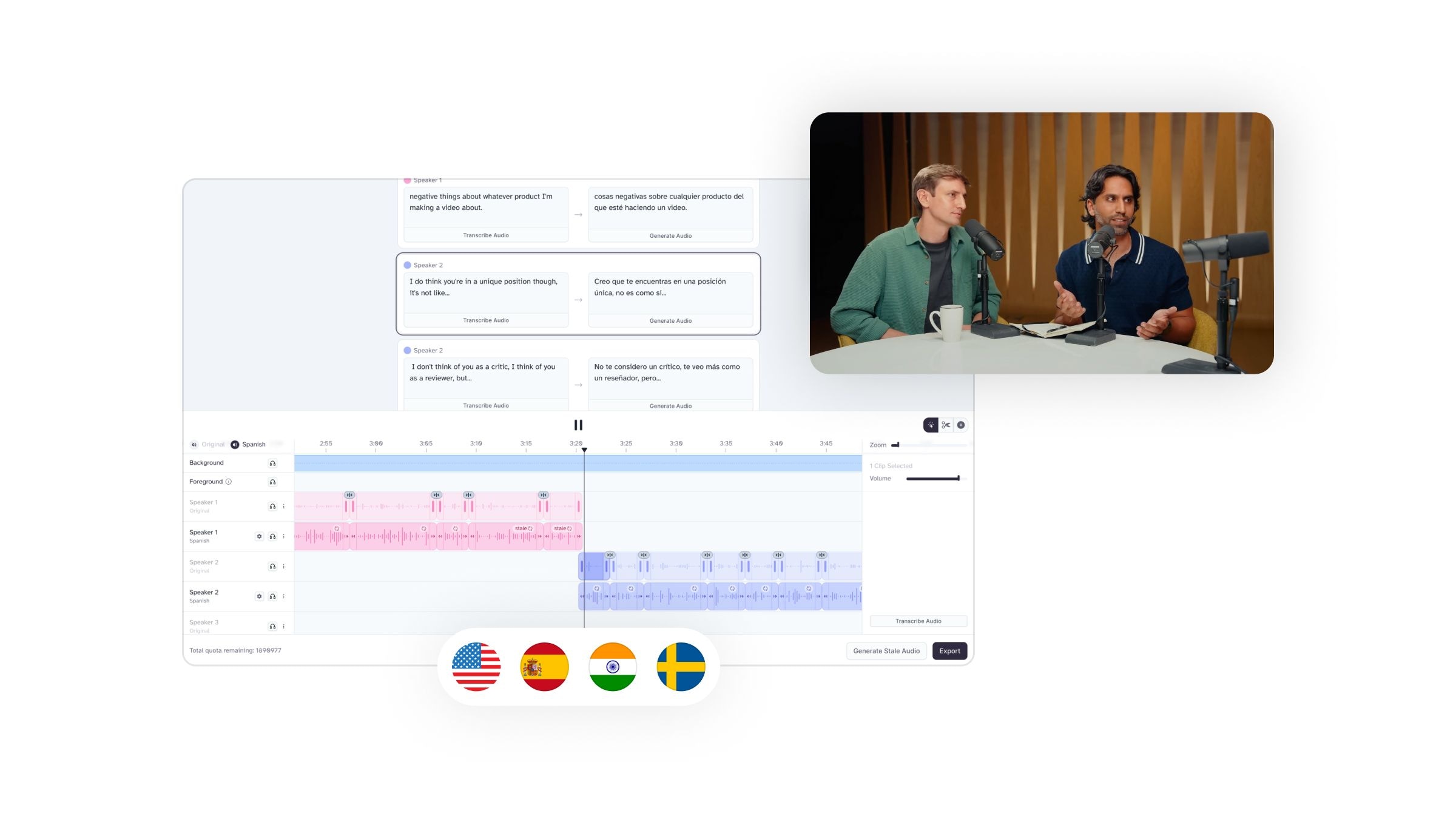
AI w Dubbingu Audio i Tworzeniu Treści
Z solidnym zrozumieniem AI text-to-speech, AI voice cloning i generatywnych głosów, jesteśmy teraz gotowi przyjrzeć się bliżej, jak jest to stosowane w dubbingu audio i tworzeniu treści.
AI w Przemyśle Filmowym
Świat filmu przechodzi rewolucję napędzaną AI w dubbingu audio i lokalizacji. Wyobraź sobie: klasyczny film zagraniczny, pięknie zdubbingowany w twoim ojczystym języku, z głosami twoich ulubionych aktorów płynnie wypływającymi z ust postaci. To nie tylko science fiction; technologia audio napędzana AI czyni to rzeczywistością.
Korzystając z narzędzi do dubbingu głosowego AI, filmowcy mogą bezproblemowo zastępować treści audio, zapewniając globalnej publiczności możliwość cieszenia się filmem w preferowanym języku. Już jest to wdrażane; północnoamerykańska usługa streamingowa, Topic, używa tej technologii, aby udostępnić swój katalog w językach obcych anglojęzycznym widzom.
AI w Przemyśle Gier
Zastosowania w grach są ogromne. Czy to dostarczanie dynamicznych i ekspresyjnych dialogów dla postaci niegrywalnych (NPC), jak w naszej współpracy z Inworld, czy doskonalenie dubbingu narracji w grze – AI doskonale tworzy realistyczne głosy, które wzbogacają doświadczenie audio dla graczy.
Ponadto, niedawno nawiązaliśmy współpracę z grą metaverse, BUD, aby ułatwić graczom konwersję tekstu w grze na realistyczne głosy. To wprowadza nowy poziom immersji do doświadczeń tworzonych przez użytkowników, które wykraczają poza grafikę i rozgrywkę.
AI w Tworzeniu Treści
Twórcy treści w całym cyfrowym krajobrazie przyjmują AI do swoich przepływów pracy. Dzięki zdolności do generowania wysokiej jakości, naturalnie brzmiących głosów i narracji, AI przyspiesza proces tworzenia treści, obniża koszty i zapewnia spójność jakości.
Wystarczy otworzyć feed TikToka, aby szybko znaleźć przykłady sukcesów twórców treści – miliony wyświetleń na kanałach, które polegają na automatyzacji treści audio. Marketerzy, profesjonalni twórcy treści i hobbyści znajdują kreatywne zastosowania dla generatywnego audio. Możliwości są ogromne, a nowe zastosowania pojawiają się każdego dnia.
Chcesz Zobaczyć Moc AI Dubbingu?
Wypróbuj nasze darmowe narzędzie do AI dubbingu. Możesz przesłać wideo lub udostępnić link z popularnych platform wideo, takich jak YouTube, X (Twitter) i TikTok.
Tłumacz audio i wideo, zachowując emocje, timing, ton i unikalne cechy każdego mówcy
Czytaj dalej, aby zobaczyć, jak generatywne audio poprawia dostępność i tworzy doświadczenia wirtualnej rzeczywistości (VR), które są naprawdę immersyjne.
AI Audio dla Dostępności i Immersji w Wirtualnej Rzeczywistości
Możliwości generatywnego AI audio wykraczają daleko poza rozrywkę; odgrywają kluczową rolę w zwiększaniu dostępności dla szerszej publiczności. Rozszerzając to dalej, audio napędzane AI przekształca krajobraz wirtualnej rzeczywistości (VR) i rozszerzonej rzeczywistości (AR), ożywiając immersyjne doświadczenia realistycznymi głosami i interaktywnymi narracjami.
Tworzenie Treści Cyfrowych Inkluzywnymi
Aby pokazać, jak technologie audio napędzane AI promują inkluzywność i dostępność, przyjrzyjmy się zmieniającej życie mocy tych postępów z Markiem.
Mark jest zapalonym czytelnikiem i entuzjastycznym uczniem. Jednak Mark staje przed znacznym wyzwaniem – jest osobą niewidomą, co sprawia, że czytanie standardowego tekstu jest trudne. Ta przeszkoda często sprawia, że czuje się wykluczony z bogactwa informacji i rozrywki dostępnych online.
Wszystko zmieniło się, gdy Mark odkrył napędzane AI oprogramowanie do czytania online. Ta potężna technologia natychmiast przekształca pisemne treści w realistyczne słowa mówione. Gdy eksplorował możliwości AI text reader, Mark poczuł niespotykane dotąd poczucie wolności i wzmocnienia. Już nie ograniczony przez swoje wizualne ograniczenia, mógł bez wysiłku uzyskiwać dostęp do treści cyfrowych i cieszyć się nimi.
Oprogramowanie AI reader pozwala Markowi cieszyć się ulubionymi książkami, być na bieżąco z artykułami prasowymi, a nawet uczestniczyć w kursach online. Cyfrowy świat, kiedyś wyzwaniem, jest teraz jego dostępnym placem zabaw.
Mark nie jest sam; według badań WHO, istnieje ponad 2,2 miliarda osób z upośledzeniem wzroku. Aby ułatwić życie wszystkim tym użytkownikom jak Mark, wkrótce wydamy naszą własną rozszerzenie Chrome reader – zaprojektowane, aby jeszcze bardziej zwiększyć dostępność treści cyfrowych.
Dostępność cyfrowa może być trudna, ale AI text-to-speech ułatwia osobom z niepełnosprawnościami konsumowanie treści online. Napędzane AI czytniki ekranowe przekształcają tekst w naturalny, łatwy do słuchania głos AI, co oferuje wzbogacone doświadczenie przeglądania dla użytkowników niewidomych. Ponadto, AI audio wspiera również inkluzywną edukację, zapewniając dostępność treści edukacyjnych dla wszystkich, niezależnie od języka czy umiejętności czytania.
AI Audio w Wirtualnej Rzeczywistości i Rozszerzonej Rzeczywistości
Wirtualna rzeczywistość (VR) i rozszerzona rzeczywistość (AR) to wszystko o immersyjnych doświadczeniach. Do niedawna skupiano się na aspekcie wizualnym, ale AI audio oferuje brakujący składnik do stworzenia wielozmysłowego, autentycznego wirtualnego świata.
Zwiększona Interaktywność
W VR i AR zdolność do interakcji z cyfrowym środowiskiem jest kluczowa. AI audio dodaje nową warstwę interaktywności, pozwalając użytkownikom na naturalne rozmowy z postaciami AI. Ponieważ NPC są AI, użytkownicy mogą prowadzić swobodne rozmowy i otrzymywać odpowiedzi w czasie rzeczywistym, dostosowane do kontekstu. Niezależnie od tego, czy eksplorujesz symulację historyczną, rozwiązujesz zagadki, czy angażujesz się w interakcje społeczne, AI audio wzbogaca doświadczenie.
Utrzymywanie Cyfrowej Persony
W niektórych z tych immersyjnych środowisk utrzymywanie cyfrowej persony jest częścią atrakcji. Generator głosu postaci AI zapewnia, że głos twojego awatara jest nie tylko realistyczny, ale także zdolny do przekazywania emocji i niuansów. W rezultacie wirtualna rzeczywistość staje się czymś więcej niż tylko wizualnym doświadczeniem; staje się sposobem na wyrażanie siebie za pomocą dźwięku i emocji.
AI Audio Wykracza Poza Rozrywkę
Czytniki ekranowe odgrywają transformacyjną rolę w zwiększaniu dostępności dla tych, którzy tego najbardziej potrzebują. Idąc krok dalej, generatywne głosy AI podnoszą doświadczenia VR i AR na nowe wyżyny. Synergia między AI a audio otwiera drzwi do nowych możliwości i inkluzywności.
Rezultat? Treści cyfrowe i immersyjne symulacje stają się bardziej dostępne i angażujące dla wszystkich.
W następnej sekcji omówimy kwestie etyczne związane z technologią głosu AI i odpowiedzialne korzystanie z tych potężnych narzędzi.
Kwestie Etyczne w Technologii Głosu AI
Widzieliśmy, jak potężne jest generatywne audio, ale jak w przypadku każdego zaawansowanego narzędzia, wymaga to dyskusji na temat odpowiedzialnego użycia. Ponieważ technologia głosu AI obejmuje ogromne zbiory danych, istnieją oczywiste obawy dotyczące ochrony danych i naruszenia prywatności. Jednak istnieje kilka unikalnych kwestii, które należy rozważyć dla etycznej technologii głosu AI.
Klonowanie Głosu Bez Zgody
Memy wideo napędzane realistycznymi generatorami AI text-to-speech Spongeboba i Joe Rogana mogą wydawać się nieszkodliwe i zabawne, ale jest ciemniejsza strona tego trendu. W miarę jak klonowanie głosów celebrytów zyskuje na popularności, zobaczymy więcej osób używających tej technologii do celów oszukańczych.
Zdolność do stworzenia przekonującej repliki czyjegoś głosu budzi oczywiste obawy. Łatwo sobie wyobrazić, jak głęboki klon głosu Donalda Trumpa mógłby być użyty do prowadzenia kampanii dezinformacyjnej. Na mniejszą skalę, nastąpił wzrost oszustów używających replikatorów głosu AI i istnieją również problemy z bezpieczeństwem związane z uwierzytelnianiem głosowym.
Czy Etyczne Klonowanie Głosu Jest Możliwe?
„Zapewnienie etycznego użycia AI jest kluczowe. Pracujemy wspólnie, aby ustanowić standardy branżowe i promować odpowiedzialne korzystanie z technologii audio AI.” – Jan Czarnocki, Radca Prawny, ElevenLabs
Tak długo, jak zostaną podjęte odpowiednie kroki, uważamy, że jest to możliwe. Nasze Warunki Usługi pozwalają na klonowanie głosu tylko wtedy, gdy masz zgodę osoby. Dla większej przejrzystości opracowaliśmy Klasyfikator Mowy AI zdolny do identyfikacji klipów audio generowanych przez ElevenLabs.
Warto zauważyć, że nasze narzędzia audio AI zasilają kilku naszych 'konkurentów', więc Klasyfikator Mowy AI może wykrywać klony głosów od wielu czołowych firm generatywnego audio.
Legislacja i Regulacje
Automatyzacja zadań związanych z głosem będzie coraz częściej zastępować ludzkie miejsca pracy w takich dziedzinach jak filmy animowane, obsługa klienta i tworzenie treści. Organy regulacyjne muszą zastanowić się nad potencjalnym wpływem na pracowników i jak wspierać uczciwe przejście dla tych, którzy zostaną dotknięci.
Dodatkowo, konieczne jest ustanowienie ram prawnych dotyczących technologii głosu AI, aby chronić przed nadużyciami, chronić prawa użytkowników i zachęcać do odpowiedzialnego rozwoju. Na przykład, trwają dyskusje na temat tego, które strony powinny być pociągane do odpowiedzialności za nieetyczne użycie lub konsekwencje wynikające z generowanego przez AI audio. W tym celu współpracujemy z partnerami takimi jak Loccus w celu stworzenia standardów branżowych dla uczciwej i etycznej technologii głosu AI.
Odpowiedzialny rozwój i zastosowanie tych potężnych narzędzi audio AI są kluczowe, aby zminimalizować ryzyko i zmaksymalizować korzyści. Patrząc w przyszłość, ważne jest, aby angażować się w dyskusje i opracowywać wytyczne promujące etyczne użycie technologii głosu AI.
Przyszłość Generatywnego AI Audio
Zyskałeś zrozumienie obecnego krajobrazu technologii audio AI i jest jasne, że stoimy na progu rewolucji; audio napędzane AI, realistyczne AI text-to-speech, generatywne głosy, klonowanie głosu i więcej dramatycznie zmieniają sposób, w jaki interakcjonujemy z dźwiękiem.
Ale co dalej z tą transformacyjną technologią?
„Jesteśmy na czele innowacji AI audio, a integracja AI audio w codziennym życiu nie jest odległą przyszłością, ale bliską rzeczywistością.” – Mati Staniszewski, CEO, ElevenLabs
AI Audio w Codziennym Życiu
Integracja AI audio w nasze codzienne życie jest nieunikniona. Statista szacuje, że do 2024 roku będzie używanych 8,4 miliarda cyfrowych asystentów głosowych na całym świecie – to dwa razy więcej niż 4,2 miliarda w 2020 roku.
AI-wzmacniana poprawa głosu na żywo (znana również jako modulacja głosu AI) podczas rozmów ma na celu podniesienie jakości komunikacji. Centra obsługi klienta i platformy komunikacji w czasie rzeczywistym będą mogły poprawić klarowność głosu, tłumić hałas w tle, a nawet pomagać użytkownikom w bardziej efektywnym wyrażaniu siebie.
Badania rynku i analiza opinii klientów zostaną zrewolucjonizowane dzięki napędzanej AI analizie sentymentu danych głosowych. Automatycznie oceniając emocjonalny ton i kontekst rozmów mówionych, firmy mogą uzyskać głębsze wglądy w zadowolenie klientów i odpowiednio doskonalić swoje produkty i usługi. W połączeniu z narzędziami obsługi klienta napędzanymi AI, te dane mogą określić najlepszy ton głosu i tempo, aby uspokoić zdenerwowanego klienta.
Być może w dalszej przyszłości zobaczymy podejście marketingowe, które uwzględnia twoje preferencje głosowe. Czy głęboki męski głos lub radosny kobiecy głos sprawi, że bardziej prawdopodobne będzie, że coś kupisz? Świat marketingu szybko zintegrował AI audio z zmiennymi, które testują A/B.
To spersonalizowane podejście do audio prawdopodobnie przejdzie z marketingu do wszystkich treści, które konsumujesz. Twoje preferencje głosowe zostaną zanotowane i użyte do dostarczenia optymalnego doświadczenia audio w różnych branżach, od opieki zdrowotnej po rozrywkę.
Trendy AI Audio Będą Kontynuowane
Technologie Inkluzywne:
AI audio już teraz czyni treści cyfrowe dostępnymi dla osób z niepełnosprawnościami. Ten trend przyspieszy wraz z rozwojem większej liczby narzędzi AI i rozwiązań, które priorytetowo traktują dostępność i różnorodność.
AI Voice Cloning i Bezpieczeństwo:
Obecnie możemy tworzyć głosy praktycznie nieodróżnialne dla ludzkiego ucha. W miarę jak technologia postępuje do doskonałych replik ludzkiego głosu, stanie się coraz trudniej dla komputerów wykrywać głębokie klony głosu i oszukańcze użycie głosu. Trwająca walka między tymi, którzy rozwijają technologię klonowania głosu AI, a tymi, którzy chcą ją nadużywać, będzie wymagała postępów w środkach bezpieczeństwa.
Możliwości Edukacyjne i Zawodowe:
AI audio otworzy nowe możliwości edukacyjne i zawodowe. Osoby, które rozumieją i wykorzystują potencjał audio napędzanego AI, będą poszukiwane w różnych dziedzinach: od tworzenia treści i aktorstwa głosowego po rozwój AI i cyberbezpieczeństwo.
Przyszłość AI Audio Jest Obiecująca i Złożona
Powyższe to tylko kilka przykładów rozwoju, którego możemy się spodziewać. Technologia audio AI jest wciąż młoda i z pewnością pojawią się nowe zastosowania, których jeszcze nie rozważaliśmy.Statista przewiduje, że wielkość rynku AI wzrośnie o 788% między 2023 a 2030 rokiem.
Przemysł audio AI ma ogromny potencjał do przekształcenia sposobu, w jaki komunikujemy się, konsumujemy treści i interakcjonujemy ze światem wokół nas.
W następnej sekcji wyjaśnimy, jak możesz stworzyć głos AI i omówimy zalety i wady najlepszych generatorów głosu AI online.
ElevenLabs vs. Konkurenci
Jeśli chodzi o AI audio, branża jest pełna narzędzi i platform, z których każda stara się wypracować swoją niszę. ElevenLabs jednak wyróżnia się na tle konkurencji, oferując unikalne połączenie funkcji i możliwości, które odróżniają nasze rozwiązania audio AI. Przyjrzyjmy się, jak nasze oferty wypadają w porównaniu z kluczowymi konkurentami na rynku.
ElevenLabs vs. Speechify, Narakeet, Murf.ai i Natural Readers
Wiele popularnych platform audio AI, takich jak Speechify, Narakeet, Murf.ai i Natural Readers, ma problemy z jakością generowanych głosów. Użytkownicy często napotykają problemy z dostawą, tempem lub tonem, które zakłócają immersję i ujawniają syntetyczną naturę głosu.
Tutaj w ElevenLabs podchodzimy do tego inaczej. Wysokiej jakości głosy nieodróżnialne od prawdziwego człowieka są naszym standardem – tworzymy głosy tak realistyczne, że nie zdasz sobie sprawy, że są generowane przez AI.
ElevenLabs vs. Lovo.ai i Play.ht
Lovo.ai i Play.ht oferują dobrej jakości głosy, ale użytkownicy mogą mieć trudności z wyborem idealnego głosu do swoich specyficznych potrzeb.
Tutaj ElevenLabs przejmuje prowadzenie. Oferujemy różnorodność 120 wcześniej stworzonych głosów, więc masz szeroki wybór. Ale idziemy o krok dalej, ponieważ pozwalamy również generować całkowicie niestandardowe głosy. Z ElevenLabs nie musisz przeszukiwać setek próbek głosowych, aby znaleźć odpowiedni.
Zamiast tego wystarczy określić płeć, wiek, akcent i siłę akcentu, który chcesz – stworzymy 100% unikalny głos dostosowany do twoich preferencji. Nie do końca to, czego szukasz? Żaden problem, możesz łatwo wygenerować nowy głos, który idealnie pasuje do twoich wymagań audio.
Porównanie Narzędzi AI Audio
W konkurencyjnym krajobrazie AI audio, ElevenLabs wyróżnia się jako wybór numer jeden.
Jak widziałeś, priorytetem są dla nas wysokiej jakości i realistyczne głosy, ale także upraszczamy AI audio. Naszym celem jest wprowadzenie technologii do różnych branż i stworzenie płynnego, łatwego w użyciu i dostosowywalnego przepływu pracy dla każdego przypadku użycia.
Już teraz oferujemy realistyczny darmowy generator głosu AI text-to-speech, oprogramowanie do klonowania głosu, narzędzie do długiej formy AI TTS, automatyczne narzędzie do AI dubbingu, potężne API i wiele więcej, co wkrótce się pojawi.
Nasze zaangażowanie w dostarczanie niezrównanych rozwiązań audio nadal nas wyróżnia, zapewniając użytkownikom ElevenLabs najlepsze z obu światów – jakość i wygodę.
Gotowy, aby Doświadczyć Najlepszego, co AI Audio Ma do Zaoferowania?
Twórz ludzkie głosy z naszym systemem Text to Speech (TTS), stworzonym do wysokiej jakości narracji, gier, wideo i dostępności. Ekspresyjne głosy, wsparcie wielojęzyczne i integracja z API ułatwiają skalowanie od projektów osobistych do firmowych workflow.
Unikalne Sposoby, w Jakie Klienci Wykorzystują AI Audio
W tej sekcji przyjrzymy się niektórym unikalnym przypadkom użycia AI audio napędzanym technologią ElevenLabs. Skupiając się na rzeczywistej funkcjonalności, przyjrzymy się zarówno małym osobistym zastosowaniom, jak i dużym projektom zmieniającym branżę, które podkreślają wszechstronność i moc naszych narzędzi.
Ponowne Połączenie Poprzez Klonowanie Głosu
Na serwerze Discord ElevenLabs, mieliśmy wielu użytkowników klonujących głosy zmarłych krewnych. Wiemy, że to nie dla każdego, ale niektórzy użytkownicy uważają, że to pomaga radzić sobie ze stratą. Pozwala użytkownikom uzyskać zamknięcie, ponownie odwiedzić miłe wspomnienia (z głosem czytającym cenne listy) lub pomóc rodzinom wspominać razem.
„Myślę, że to szalone, że model AI może tworzyć 'piękne' rzeczy. Natychmiast sklonowałem głos zmarłej osoby, którą znam, i teraz mogę go 'wskrzeszać', kiedy potrzebuję.” – Adam, członek Discord
Mieliśmy również osoby klonujące głos zmarłego członka rodziny i używające go do narracji książki, którą opublikowali przed odejściem. Czy możesz sobie wyobrazić, jak użytkownik poczuje się, gdy posłucha tej narracji audiobooka AI w głosie ukochanej osoby?
Przywracanie Utraconych i Uszkodzonych Głosów
Więcej przykładów emocjonalnego wpływu AI audio można znaleźć, gdy przyjrzymy się użytkownikom, którzy nie mogą komunikować się tak, jak kiedyś. Te reakcje użytkowników oferują dobry przykład, jak transformacyjne może być klonowanie głosu: „To jest dla mnie suuuper ważne, ponieważ straciłem głos. Dosłownie. Mogę tylko szeptać dzisiaj, po intubacji. Moje struny głosowe są sparaliżowane w połowie otwarte.” – Aaron, członek Discord
„Straciłem głos na stałe z powodu raka krtani. Czy byłoby możliwe, aby AI nauczyło się mojego głosu z starych taśm wideo, które mam? Nie mogę się doczekać, aby użyć tej technologii, aby odzyskać mój głos...” – Vince, członek Discord
Generowanie Audiobooków w Minutach
Przechodząc do profesjonalnego zastosowania, nasze narzędzie Studio ułatwia użytkownikom tworzenie wysokiej jakości długich form audio w różnych językach. Unikalne wyzwania związane z robieniem tego za pomocą ręcznych nagrań głosowych są oczywiste: skala, koszt i szybkość. Ile godzin zajęłoby nagranie i edycja książki w jednym języku?
Jednym z niezwykłych przykładów, jak można to wykorzystać, jest nasze studium przypadku z wydawcą, Lukeman Literary. Użyli Studio do szybkiego generowania audiobooków i wspierania ekspansji wielojęzycznej, wydając w wielu językach. To pozwala im zaspokoić globalną publiczność z różnorodnymi preferencjami językowymi.
„Pomimo oczywistych korzyści z cyfrowej narracji, nie byliśmy gotowi przyjąć nowej technologii, dopóki nie pojawiła się firma z narracją przełomowej jakości, która mogłaby dorównać naturalnemu ludzkiemu głosowi. W nowym produkcie ElevenLabs znaleźliśmy tę jakość.” – Noah Lukeman, Prezes i Założyciel Lukeman Literary
Innowacje w AI Audio i Poza
Te unikalne przypadki użycia, opinie klientów i studia przypadków pokazują wszechstronność technologii audio AI ElevenLabs. Od projektów audio AI dla przedsiębiorstw przełamujących bariery językowe po głęboko osobiste emocjonalne doświadczenia, nasze rozwiązania nadal przesuwają granice tego, co możliwe z AI audio.
Podsumowanie
Przeszliśmy szczegółową podróż przez świat AI audio i dowiedzieliśmy się o transformacyjnych technologiach przekształcających nasze relacje z dźwiękiem. Od realistycznego TTS i generatywnych głosów po klonowanie głosu i automatyczny dubbing audio, potencjał dla adopcji AI w branży jest ogromny.
Obecny krajobraz technologii AI już pokazał znaczenie AI audio – ulepszone doświadczenia użytkowników, oszczędności kosztów, poprawiona dostępność i nowe możliwości dla firm.
Jednak przyszłość zapowiada się jeszcze bardziej ekscytująco. Z nowymi zastosowaniami technologii AI pojawiającymi się niemal codziennie, spodziewamy się boomu w adopcji w branżach takich jak opieka zdrowotna, bankowość, edukacja, marketing i więcej – i nie zapominajmy o wszystkich zastosowaniach dla dostępności.
Jak Zacząć z AI Audio?
Jeśli jesteś tak podekscytowany jak my potencjałem wszystkiego, co związane z AI audio, to jesteś we właściwym miejscu.
ElevenLabs jest wiodącym dostawcą w branży AI audio, oferującym najnowocześniejsze rozwiązania, które priorytetowo traktują realistyczne głosy i dostosowanie do użytkownika. Nasze zaangażowanie w jakość i wygodę utrzymuje nas na czele tego szybko rozwijającego się pola.
Dobrym miejscem na początek jest nasza strona Synteza Mowy. Nasze darmowe AI text-to-speech pozwala wypróbować technologię i sprawdzić, czy jest odpowiednia dla twoich potrzeb.
Myślisz, że Generatywne AI Audio Pasuje do Twojego Biznesu?
Wiemy, że integracja nowej technologii w twoim biznesie jest trudna. Chcielibyśmy to ułatwić. Skontaktuj się z nami, a zobaczymy, jak możemy pomóc.
Najczęściej Zadawane Pytania
Możesz łatwo stworzyć głos AI, korzystając z generatorów głosu AI online, takich jak ElevenLabs, które oferują różne głosy text-to-speech za darmo.
AI poczyniło znaczące postępy w tworzeniu realistycznych głosów TTS (text-to-speech) z emocjami i akcentami. Najbardziej realistyczne głosy AI ElevenLabs są nieodróżnialne od ludzkiej mowy.
Najlepsze AI text-to-speech zależy od twoich potrzeb, ale istnieje wiele doskonałych opcji do generowania realistycznych głosów. ElevenLabs łączy wysoką jakość głosów i łatwość użycia, co czyni go jednym z najpopularniejszych wyborów.
Tak, ElevenLabs oferuje darmowe oprogramowanie AI text-to-speech online, które pozwala generować wysokiej jakości głosy.
Możesz użyć generatorów głosu AI, takich jak ElevenLabs, aby tworzyć głosy generowane przez AI do voiceoverów i narracji w swoich filmach na TikToku i YouTube.
ElevenLabs obsługuje 29 języków, w tym arabski, chiński i indyjski text-to-speech.
ElevenLabs oferuje szereg realistycznych głosów text-to-speech, które można uzyskać za pośrednictwem łatwego w użyciu API.
ChatGPT od OpenAI ma wiele rzeczywistych zastosowań, takich jak chatboty, generowanie treści, tłumaczenie języka i więcej.
Technologia syntezy mowy od ElevenLabs ułatwia ożywienie twojego chatbota.
ChatGPT to model AI opracowany przez OpenAI, który rozumie i generuje naturalny język tekstowy. Jest to popularny przykład generatywnych modeli AI, gdzie uczenie maszynowe jest używane do generowania tekstu przypominającego ludzki na podstawie podpowiedzi tekstowych.
Stable Diffusion, DALL-E 2 i Midjourney to najpopularniejsze generatory obrazów AI. Dla wszystkiego, co związane z audio, polecamy ElevenLabs.
Zacznij od eksploracji zasobów związanych z modelami transformatorowymi, modelami dyfuzji i koncepcją enkoderów i dekoderów. To są podstawowe elementy, które napędzają ostatnie przełomy.
This Veterans Day, we honor Lt Col Thomas Brittingham, a pilot, father, and veteran living with ALS, who regained his voice through the ElevenLabs Impact Program, one story among many showing how veterans are finding their voices again through technology.