.webp&w=3840&q=95)
रिसर्च
.webp&w=3840&q=95)
Eleven Music is Here
Studio-grade music generated with natural language prompts in any style and for countless uses
Studio-grade music generated with natural language prompts in any style and for countless uses

Discover Voice Design v3: create unique AI voices with ease. Describe your desired voice, get three instant options, and deploy for creators, businesses, and developers.

सबसे अभिव्यक्तिपूर्ण टेक्स्ट टू स्पीच मॉडल
.webp&w=3840&q=95)


दुनिया के सबसे सटीक ASR मॉडल के साथ स्पीच को टेक्स्ट में ट्रांसक्राइब करें



आपने कभी भी इतनी तेजी से मानव-जैसी TTS का अनुभव नहीं किया होगा

अपने दर्शकों का विस्तार करें और 32 भाषाओं में उच्च गुणवत्ता वाला ऑडियो बनाएं

32 भाषाओं में उच्च गुणवत्ता, कम विलंबता वाला टेक्स्ट टू स्पीच

हमारे सबसे तेज़ मॉडल में अब नंबर उच्चारण में सुधार हुआ है

इस प्रगति से दुनिया भर की मीडिया कंपनियों, गेम डेवलपर्स, प्रकाशकों और स्वतंत्र रचनाकारों को अपनी विषय-वस्तु की पहुंच में नाटकीय रूप से सुधार करने में मदद मिलेगी।

हमारा वर्तमान डीप लर्निंग दृष्टिकोण अधिक डेटा, अधिक कंप्यूटेशनल पावर, और नई तकनीकों का उपयोग करता है ताकि हमारा सबसे उन्नत स्पीच सिंथेसिस मॉडल प्रदान किया जा सके
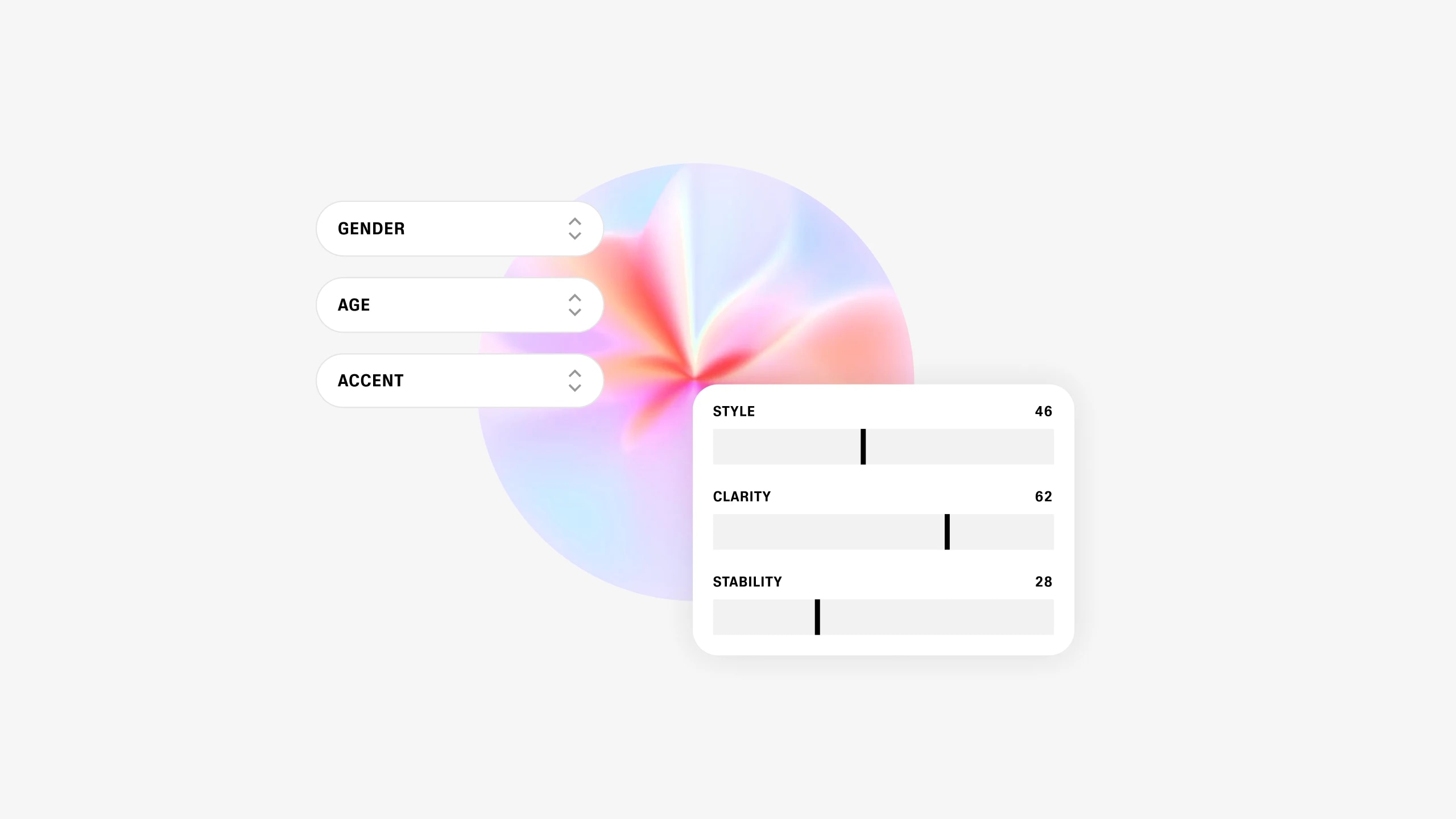
हम अपना स्वयं का जनरेटिव मॉडल तैनात कर रहे हैं जो उपयोगकर्ताओं को पूरी तरह से नई सिंथेटिक आवाज़ें डिज़ाइन करने की सुविधा देता है

हमारा मॉडल अनोखे तरीके से भावनाएं उत्पन्न करता है

एक व्यक्ति को दूसरे की आवाज़ में बोलने के लिए कहना
ElevenLabs द्वारा संचालित कन्वर्सेशनल AI



