हमने RAG को 50% तेज़ कैसे बनाया
- लेखक
- Michal Korbela
- प्रकाशित
- आखिरी बार अपडेट किया गया
सुनेंइस आर्टिकल को सुनें
RAG AI एजेंट्स की सटीकता को बढ़ाता है, LLM प्रतिक्रियाओं को बड़े नॉलेज बेस में ग्राउंड करके। पूरे नॉलेज बेस को LLM को भेजने के बजाय, RAG क्वेरी को एम्बेड करता है, सबसे प्रासंगिक जानकारी को पुनः प्राप्त करता है, और इसे मॉडल को संदर्भ के रूप में पास करता है। हमारे सिस्टम में, हम पहले एक क्वेरी री-राइटिंग स्टेप जोड़ते हैं, जिसमें संवाद इतिहास को एक सटीक, आत्मनिर्भर क्वेरी में बदलते हैं।
बहुत छोटे नॉलेज बेस के लिए, सब कुछ सीधे प्रॉम्प्ट में पास करना आसान हो सकता है। लेकिन जैसे ही नॉलेज बेस बड़ा होता है, RAG आवश्यक हो जाता है ताकि प्रतिक्रियाएं सटीक रहें और मॉडल पर भार न पड़े।
कई सिस्टम RAG को एक बाहरी टूल के रूप में मानते हैं, लेकिन हमने इसे सीधे अनुरोध पाइपलाइन में बनाया है ताकि यह हर क्वेरी पर चले। यह सटीकता सुनिश्चित करता है लेकिन लेटेंसी का जोखिम भी पैदा करता है।
क्वेरी री-राइटिंग ने हमें धीमा क्यों किया
अधिकांश यूज़र अनुरोध पिछले टर्न्स का संदर्भ देते हैं, इसलिए सिस्टम को संवाद इतिहास को एक सटीक, आत्मनिर्भर क्वेरी में बदलना पड़ता है।
उदाहरण के लिए:
- यदि यूज़र पूछता है: "क्या हम अपने पीक ट्रैफिक पैटर्न के आधार पर उन सीमाओं को कस्टमाइज़ कर सकते हैं?"
- सिस्टम इसे इस प्रकार री-राइट करता है:“क्या एंटरप्राइज प्लान API रेट लिमिट्स को विशेष ट्रैफिक पैटर्न के लिए कस्टमाइज़ किया जा सकता है?”
री-राइटिंग अस्पष्ट संदर्भों जैसे “उन लिमिट्स” को आत्मनिर्भर क्वेरी में बदल देता है, जिसे पुनः प्राप्ति सिस्टम उपयोग कर सकते हैं, अंतिम प्रतिक्रिया की सटीकता और संदर्भ को सुधारते हुए। लेकिन एकल बाहरी-होस्टेड LLM पर निर्भरता ने इसकी गति और अपटाइम पर एक कठिन निर्भरता बना दी। यह स्टेप अकेले RAG लेटेंसी का 80% से अधिक था।
हमने इसे मॉडल रेसिंग से कैसे ठीक किया
हमने क्वेरी री-राइटिंग को एक रेस के रूप में पुनः डिज़ाइन किया:
- पैरेलल में कई मॉडल. प्रत्येक क्वेरी को एक साथ कई मॉडलों को भेजा जाता है, जिसमें हमारे सेल्फ-होस्टेड Qwen 3-4B और 3-30B-A3B मॉडल शामिल हैं। पहला वैध उत्तर जीतता है।
- फॉलबैक जो बातचीत को जारी रखते हैं. यदि कोई मॉडल एक सेकंड के भीतर प्रतिक्रिया नहीं देता, तो हम यूज़र के रॉ मैसेज पर वापस जाते हैं। यह कम सटीक हो सकता है, लेकिन यह रुकावटों से बचाता है और निरंतरता सुनिश्चित करता है।
.webp&w=3840&q=95)
प्रदर्शन पर प्रभाव
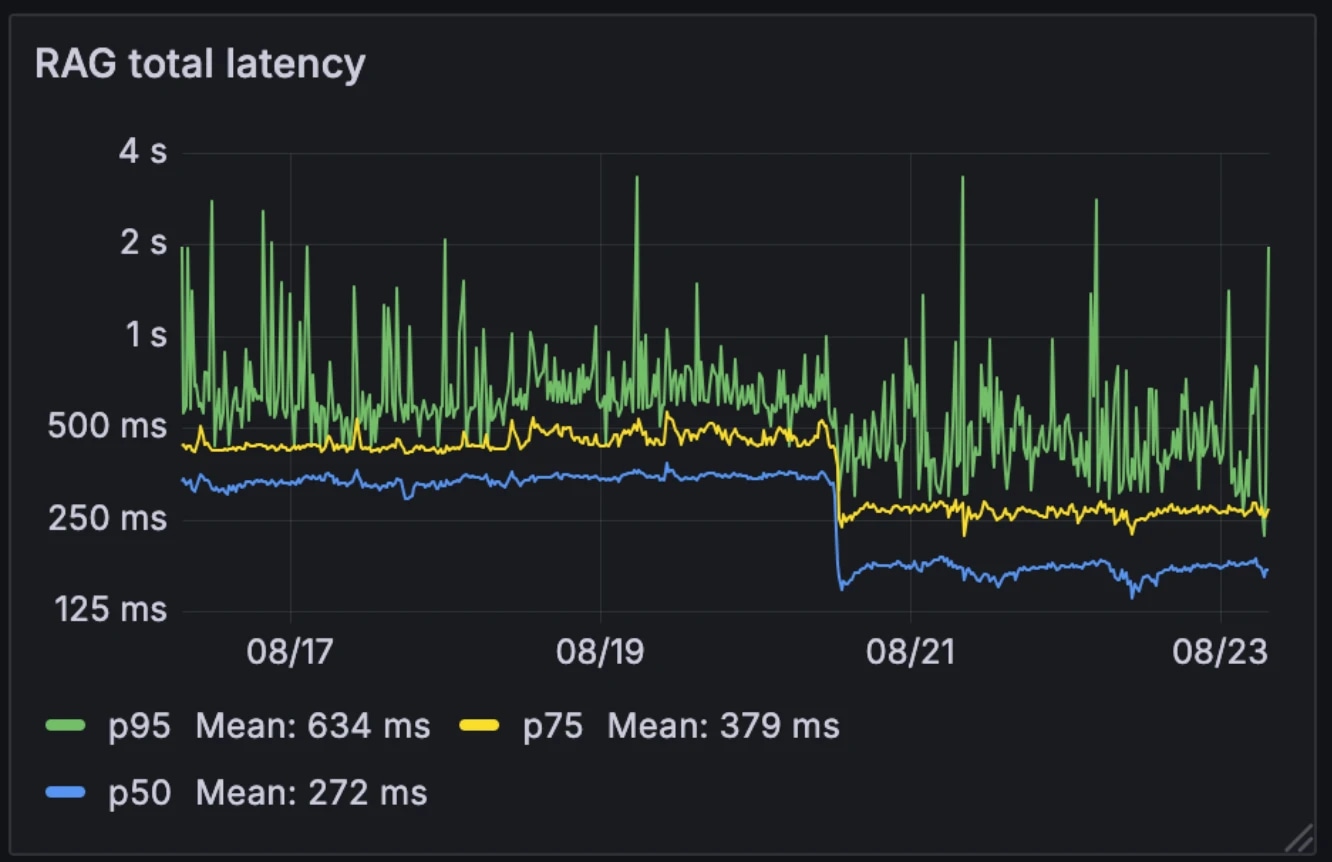
इस नई आर्किटेक्चर ने मीडियन RAG लेटेंसी को आधा कर दिया, 326ms से 155ms तक। कई सिस्टम जो RAG को बाहरी टूल के रूप में चुनिंदा रूप से ट्रिगर करते हैं, हम इसे हर क्वेरी पर चलाते हैं। मीडियन लेटेंसी 155ms तक कम होने के साथ, इसे करने का ओवरहेड नगण्य है।
लेटेंसी पहले और बाद में:
- मीडियन: 326ms → 155ms
- p75: 436ms → 250ms
- p95: 629ms → 426ms
आर्किटेक्चर ने सिस्टम को मॉडल परिवर्तनशीलता के प्रति अधिक लचीला भी बना दिया। जबकि बाहरी-होस्टेड मॉडल पीक डिमांड घंटों के दौरान धीमे हो सकते हैं, हमारे आंतरिक मॉडल अपेक्षाकृत स्थिर रहते हैं। मॉडल्स की रेसिंग इस परिवर्तनशीलता को समतल करती है, अप्रत्याशित व्यक्तिगत मॉडल प्रदर्शन को अधिक स्थिर सिस्टम व्यवहार में बदल देती है।
उदाहरण के लिए, जब हमारे एक LLM प्रदाता ने पिछले महीने आउटेज का अनुभव किया, तो हमारी सेल्फ-होस्टेड मॉडल्स पर बातचीत निर्बाध रूप से जारी रही। चूंकि हम पहले से ही अन्य सेवाओं के लिए इस इंफ्रास्ट्रक्चर का संचालन करते हैं, अतिरिक्त कंप्यूट लागत नगण्य है।
यह क्यों महत्वपूर्ण है
सब-200ms RAG क्वेरी री-राइटिंग संवादात्मक एजेंट्स के लिए एक प्रमुख बाधा को हटा देता है। परिणामस्वरूप एक ऐसा सिस्टम है जो बड़े एंटरप्राइज नॉलेज बेस पर काम करते समय भी संदर्भ-सचेत और रियल-टाइम रहता है। पुनः प्राप्ति ओवरहेड को लगभग नगण्य स्तरों तक कम करके, संवादात्मक एजेंट्स बिना प्रदर्शन से समझौता किए स्केल कर सकते हैं।



.webp&w=3840&q=80)
