O Caminho para a Dublagem em Tempo Real
- Publicado
- Última atualização
OuvirOuça este artigo
Para alguns, a Dublagem em Tempo Real evoca a imagem do Peixe Babel do Guia do Mochileiro das Galáxias.
Até conseguirmos ler ondas cerebrais, precisamos ouvir as palavras do falante e traduzi-las para o nosso idioma de destino. Tentar traduzir cada palavra, conforme ela é dita, traz desafios reais.
Imagine um cenário em que você quer traduzir do inglês para o espanhol. O falante começa com "The". Em espanhol, "The" pode ser "El" para palavras masculinas e "La" para palavras femininas. Então, não dá para traduzir "The" com certeza até ouvirmos mais.
Imagine um cenário onde você quer traduzir do inglês para o espanhol. O falante começa com “The”. Em espanhol, “The” é traduzido para “El” para palavras masculinas e “La” para palavras femininas. Então, não podemos traduzir “The” com certeza até ouvirmos mais.

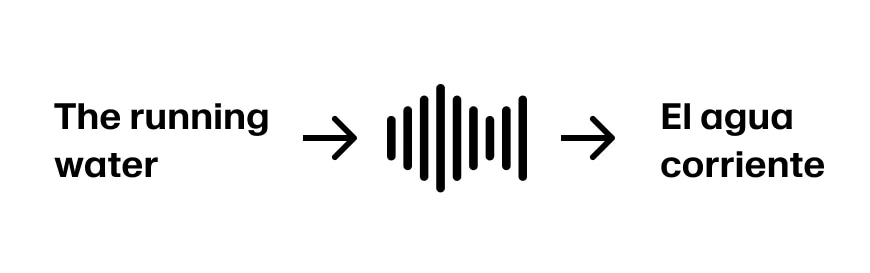
Imagine que o falante continua “The running water”. Agora temos informações suficientes para traduzir as três primeiras palavras para “El agua corrente”. Supondo que a frase continue “The running water is too cold for swimming”, estamos em boa forma.
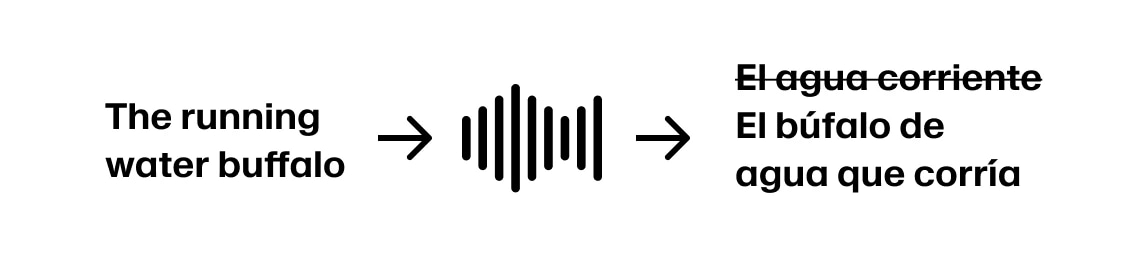
Mas se o falante continuar “The running water buffalo…” precisamos voltar atrás.
Essas frases chamadas de "
Em alguns casos de uso, pode ser aceitável ter que voltar atrás depois de começar a dublar rápido demais. Em outros, você pode optar por adicionar um pouco de latência para ter mais precisão. Como alguma latência é inevitável em todos os casos de dublagem, definimos “dublagem em tempo real” como um serviço onde você pode transmitir áudio continuamente e receber o conteúdo traduzido de volta.
Para alguns casos de uso, você pode estar disposto a aceitar que terá que voltar atrás após começar a dublar muito rapidamente. Para outros, você pode optar por adicionar latência para mais precisão. Dado que alguma latência é inerente a todos os casos de uso de dublagem, definimos dublagem “em tempo real” como um serviço através do qual você pode transmitir áudio continuamente e receber o conteúdo traduzido de volta.

As melhores aplicações comerciais de dublagem em tempo real são aquelas em que:
As melhores aplicações comerciais de dublagem em tempo real são aquelas onde
- Há um público global
- É conteúdo ao vivo
- É aceitável ter algum atraso na transmissão
Esportes
A Forbes relatou em 2019 que a NBA está ganhando $500 milhões em direitos de TV internacionais. A NFL agora está realizando jogos no Brasil, Inglaterra, Alemanha e México, pois vê a expansão internacional como um motor de receita central no futuro.
Normalmente, há vários operadores de câmera e som no local que transmitem o material para uma central de produção. A central alterna entre câmeras, mistura o áudio, insere gráficos e adiciona comentários. Às vezes, também adicionam um atraso extra para monitorar e cortar palavrões ou outros conteúdos inesperados.
O sinal principal de produção é enviado para a rede de transmissão, que adiciona sua própria identidade visual e comerciais, e distribui o conteúdo para suas afiliadas locais. Por fim, os provedores finais entregam o conteúdo ao público por cabo, satélite ou serviços de streaming.
O feed principal de produção é enviado para a rede de transmissão que adiciona sua própria marca e comerciais e distribui o conteúdo para suas redes locais. Finalmente, os provedores de última milha compartilham o conteúdo com os consumidores via cabos, feeds de satélite e serviços de streaming.

As empresas de esportes se preocupam principalmente em oferecer um produto de qualidade, e acreditam que o segredo está em captar bem a emoção e o timing dos narradores. O famoso "Chutou, é gol!" precisa ser transmitido com entusiasmo.
Nossos modelos de clonagem de voz, que são a base do nosso serviço de dublagem, conseguem captar a emoção e a entrega do falante original. Diferente da tradução, mais contexto nem sempre significa um resultado melhor. Mas ainda não chegamos ao nível emocional de um narrador de futebol espanhol!
Cada voz clonada é uma média dos exemplos usados. Se você mistura uma frase dita de forma neutra, como "Eles vão precisar ser mais agressivos com apenas dois minutos restantes", com "Chutou, é gol!", a voz clonada resultante será uma média das duas entregas.
Cada clone de voz é uma média de suas entradas. Se você combinar uma linha que é entregue de forma plana como “Eles vão precisar ser mais agressivos com apenas dois minutos restantes.” com “Ele chuta, ele marca!”, o clone resultante será a entrega média das duas.

Transmissão de Notícias
Assim como nos Esportes ao vivo, a Transmissão de Notícias passa por uma cadeia de produção que adiciona atrasos. Pelas conversas que tivemos com empresas de mídia, transmitir emoção (embora importante) é menos crítico e geralmente mais fácil, já que a maioria dos apresentadores tem um estilo bem consistente. O mais importante é que a tradução seja precisa e sensível ao contexto.
Além da possibilidade de falhas no serviço automático de tradução, alguns conceitos não têm tradução direta. Veja este exemplo:
"A comunidade se reuniu para um dia de lembrança, onde sobreviventes compartilharam suas histórias e os anciãos fizeram orações tradicionais pela cura."
Espanhol: "La comunidad se reunió para un día conmemorativo, donde los sobrevivientes compartieron sus historias y los ancianos realizaron oraciones tradicionales para la sanación."
Apesar de tecnicamente correta, "survivors" e "sobrevivientes" têm pesos diferentes em contextos de trauma histórico – em inglês, muitas vezes implica resiliência e dignidade, enquanto "sobrevivientes" pode enfatizar a condição de vítima. Da mesma forma, "performed prayers" e "realizaron oraciones" transmitem níveis diferentes de reverência – "performed" reconhece o valor cerimonial, enquanto "realizaron" pode soar mais procedural.
Bônus – O caminho para a dublagem conversacional
Para permitir conversas naturais, cara a cara, entre pessoas que não falam o mesmo idioma, é preciso uma tradução quase instantânea.
Usando as probabilidades de previsão do próximo token dos LLMs, é possível ter um modelo em tempo real da probabilidade de onde a frase vai chegar.
Usando as probabilidades de previsão do próximo token de LLMs, você tem um modelo em tempo real da probabilidade de onde uma frase está indo.

Fonte da imagem - Hugging Face "Como gerar texto"
Achou interessante e quer trabalhar com a gente no futuro do Áudio com IA? Veja
Achou isso interessante e quer trabalhar conosco no futuro do Áudio com IA? Explore vagas abertas aqui.

.jpg&w=3840&q=80)
.png&w=3840&q=80)
