.webp&w=3840&q=95)
Pesquisa
.webp&w=3840&q=95)
Eleven Music is Here
Studio-grade music generated with natural language prompts in any style and for countless uses
Studio-grade music generated with natural language prompts in any style and for countless uses

Discover Voice Design v3: create unique AI voices with ease. Describe your desired voice, get three instant options, and deploy for creators, businesses, and developers.

O modelo de Text to Speech mais expressivo
.webp&w=3840&q=95)


Transcreva fala para texto com o modelo ASR mais preciso do mundo



Você nunca experimentou um TTS tão rápido e natural

Expanda seu público e crie áudio de alta qualidade em 32 idiomas

Text to Speech de alta qualidade e baixa latência em 32 idiomas

Nosso modelo mais rápido agora tem pronúncia de números aprimorada

O avanço permitirá que empresas de mídia, desenvolvedores de jogos, editoras e criadores independentes em todo o mundo melhorem drasticamente a acessibilidade de seu conteúdo.

Nossa abordagem atual de deep learning utiliza mais dados, mais poder computacional e técnicas inovadoras para entregar nosso modelo de síntese de voz mais avançado
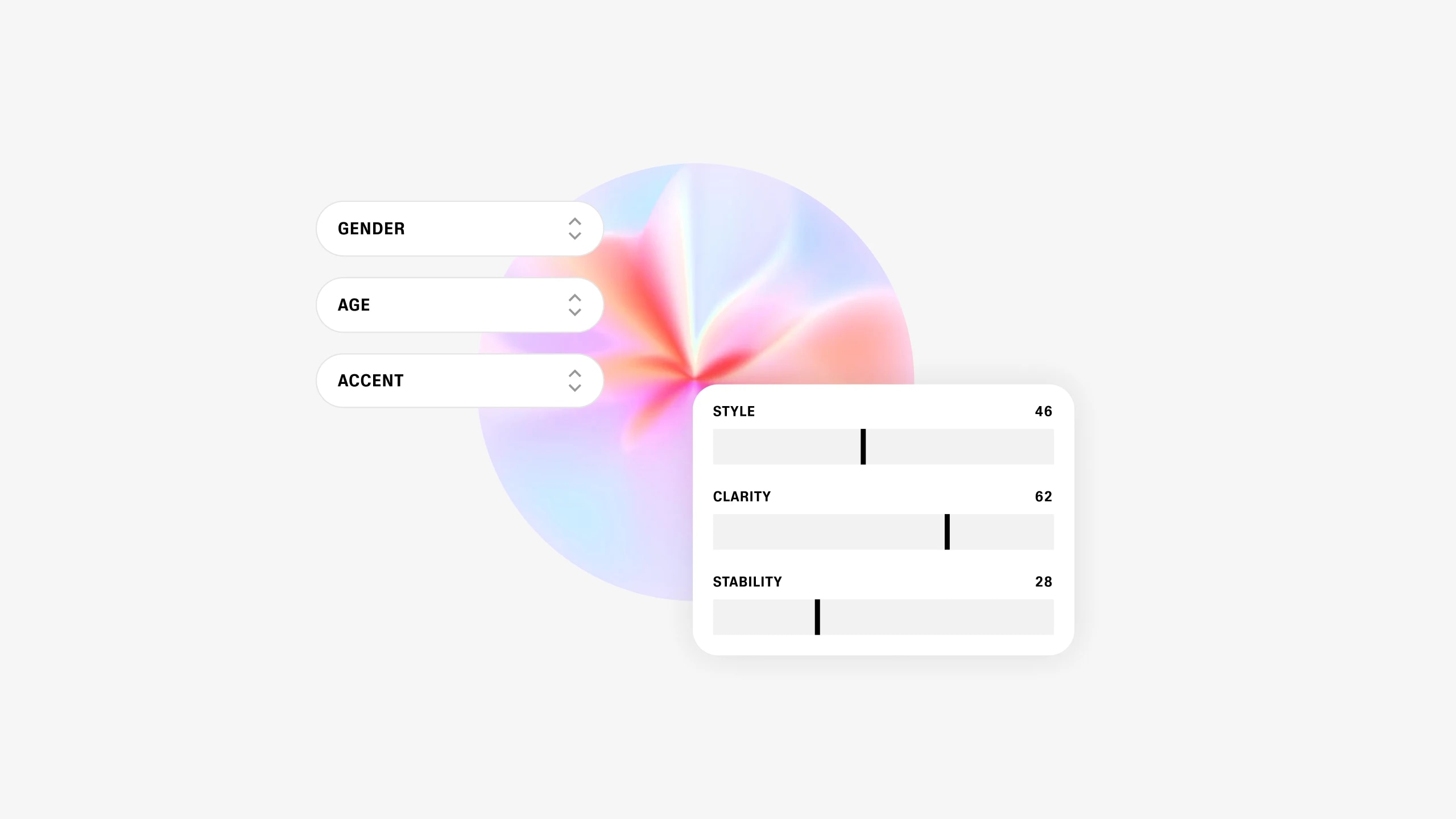
Estamos lançando nosso próprio modelo generativo que permite aos usuários criar vozes sintéticas totalmente novas

Nosso modelo produz emoções como nenhum outro

Fazendo uma pessoa falar com a voz de outra
Desenvolvido por ElevenLabs Conversational AI



