Droga do dubbingu w czasie rzeczywistym
- Opublikowano
- Ostatnia aktualizacja
PosłuchajPosłuchaj tego artykułu
Dla niektórych Real-time Dubbing przywodzi na myśl Babelfisha z Autostopem przez Galaktykę.
Dopóki nie potrafimy czytać fal mózgowych, musimy słuchać słów mówcy i tłumaczyć je na wybrany język. Próba tłumaczenia każdego słowa na bieżąco to spore wyzwanie.
Wyobraź sobie, że chcesz tłumaczyć z angielskiego na hiszpański. Mówca zaczyna od „The”. Po hiszpańsku „The” to „El” dla rzeczowników męskich i „La” dla żeńskich. Nie możemy więc przetłumaczyć „The” z pewnością, dopóki nie usłyszymy więcej.
Wyobraź sobie sytuację, w której chcesz tłumaczyć z angielskiego na hiszpański. Mówca zaczyna od „The”. W hiszpańskim „The” tłumaczy się na „El” dla rzeczowników męskich i „La” dla żeńskich. Nie możemy więc przetłumaczyć „The” z pewnością, dopóki nie usłyszymy więcej.

Wyobraź sobie, że mówca kontynuuje „The running water”. Teraz mamy wystarczająco informacji, by przetłumaczyć pierwsze trzy słowa na „El agua corriente”. Zakładając, że zdanie kontynuuje „The running water is too cold for swimming”, jesteśmy na dobrej drodze.
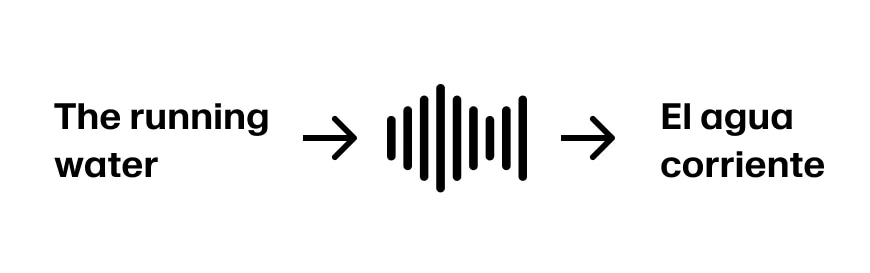
Ale jeśli mówca kontynuuje „The running water buffalo…”, musimy się cofnąć.
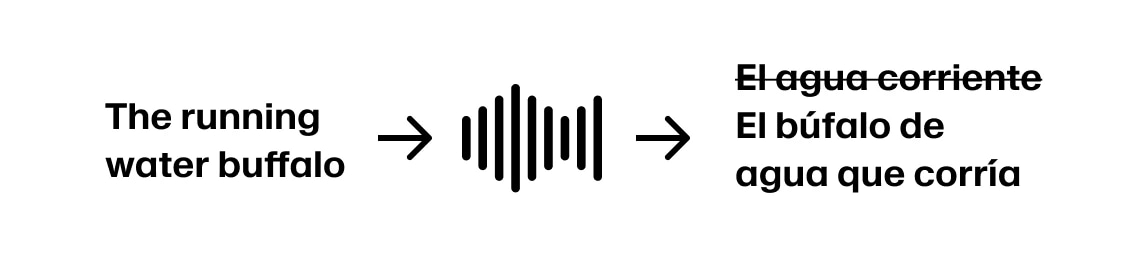
Takie „
W niektórych sytuacjach możesz zaakceptować, że czasem trzeba się cofnąć, jeśli zaczniesz dubbingować zbyt szybko. W innych możesz dodać opóźnienie, żeby było dokładniej. Ponieważ pewne opóźnienie zawsze występuje przy dubbingu, określamy „dubbing na żywo” jako usługę, w której możesz ciągle przesyłać dźwięk i od razu dostawać przetłumaczoną treść.
W niektórych przypadkach możesz zaakceptować, że będziesz musiał się cofnąć po zbyt szybkim rozpoczęciu dubbingu. W innych możesz wybrać dodanie opóźnienia dla większej dokładności. Biorąc pod uwagę, że pewne opóźnienie jest nieodłączne dla wszystkich przypadków użycia dubbingu, definiujemy „real-time” dubbing jako usługę, przez którą możesz ciągle strumieniować audio i otrzymywać przetłumaczoną treść.

Najlepsze komercyjne zastosowania dubbingu na żywo to te, gdzie
Najlepsze komercyjne zastosowania real-time dubbingu to te, gdzie
- Jest globalna publiczność
- To jest treść na żywo
- Jest akceptowalne mieć pewne opóźnienie w transmisji
Sport
Forbes donosił w 2019, że NBA zarabia 500 mln dolarów na międzynarodowych prawach telewizyjnych. NFL organizuje teraz mecze w Brazylii, Anglii, Niemczech i Meksyku, widząc międzynarodową ekspansję jako kluczowy czynnik przychodów w przyszłości.
Zazwyczaj na miejscu jest kilku operatorów kamer i dźwięku, którzy przesyłają materiał do studia produkcyjnego. Tam wybiera się ujęcia, miksuje dźwięk, dodaje grafiki i komentarz. Czasem celowo dodaje się też dodatkowe opóźnienie, by wyłapać i wyciszyć przekleństwa lub inne niepożądane treści.
Główny sygnał trafia do sieci nadawczej, która dodaje własne logo, reklamy i przekazuje treść do lokalnych stacji. Na końcu dostawcy udostępniają transmisję widzom przez kable, satelitę lub serwisy streamingowe.
Główny strumień produkcyjny jest wysyłany do sieci nadawczej, która dodaje własne oznaczenia i reklamy oraz dystrybuuje treść do swoich lokalnych sieci. W końcu dostawcy ostatniej mili udostępniają treść konsumentom za pośrednictwem kabli, transmisji satelitarnych i usług strumieniowych.

Firmom sportowym najbardziej zależy na jakości produktu i wierzą, że kluczowe jest oddanie emocji i tempa komentatorów. „Strzela, gol!” musi brzmieć z entuzjazmem.
Nasze modele klonowania głosu, na których opiera się nasz dubbing, potrafią oddać emocje i sposób mówienia oryginalnego mówcy. W przeciwieństwie do tłumaczenia, więcej kontekstu nie zawsze daje lepszy efekt. Ale jeszcze nie dorównujemy emocjom hiszpańskich komentatorów piłkarskich!
Każdy klon głosu to średnia z nagrań wejściowych. Jeśli połączysz zdanie wypowiedziane spokojnie, jak „Muszą być bardziej agresywni, zostały tylko dwie minuty”, z „Strzela, gol!”, klon będzie mówił z przeciętną ekspresją obu.
Każdy klon głosu jest średnią swoich wejść. Jeśli połączysz linię wypowiedzianą płasko jak „Będą musieli być bardziej agresywni, mając tylko dwie minuty do końca.” z „Strzela, trafia!”, powstały klon będzie średnią dostawą obu.

Wiadomości na żywo
Podobnie jak sport na żywo, wiadomości przechodzą przez produkcję, która wprowadza opóźnienia. Z rozmów z mediami wiemy, że emocje (choć ważne) są tu mniej kluczowe i łatwiejsze do oddania, bo prezenterzy zwykle mówią bardzo równo. Najważniejsze jest jednak, by tłumaczenie było dokładne i oddawało niuanse.
Poza ryzykiem błędu automatycznego tłumaczenia, niektórych pojęć nie da się przełożyć wprost. Przykład:
"Społeczność zebrała się na dzień pamięci, podczas którego ocaleni dzielili się swoimi historiami, a starsi odprawiali tradycyjne modlitwy o uzdrowienie."
Hiszpański: "La comunidad se reunió para un día conmemorativo, donde los sobrevivientes compartieron sus historias y los ancianos realizaron oraciones tradicionales para la sanación."
Choć tłumaczenie jest poprawne, „survivors” i „sobrevivientes” mają inne znaczenie w kontekście traumy historycznej – po angielsku często sugeruje siłę i godność, a „sobrevivientes” może podkreślać bycie ofiarą. Podobnie „performed prayers” i „realizaron oraciones” różnią się w tonie – „performed” podkreśla ceremonię, a „realizaron” brzmi bardziej technicznie.
Bonus – Droga do dubbingu konwersacyjnego
Żeby rozmowa na żywo między osobami mówiącymi różnymi językami była naturalna, potrzebne jest niemal natychmiastowe tłumaczenie.
Dzięki wykorzystaniu prawdopodobieństw przewidywania kolejnych tokenów przez LLM, mamy na bieżąco model tego, jak może się rozwinąć zdanie.
Korzystając z prawdopodobieństw przewidywania następnego tokena LLM, masz model czasu rzeczywistego prawdopodobieństwa, dokąd zmierza zdanie.

Źródło obrazu - Hugging Face "How to generate text"
Zainteresowało cię to i chcesz z nami tworzyć przyszłość audio AI? Sprawdź
Uważasz to za interesujące i chcesz z nami pracować nad przyszłością AI Audio? Sprawdź otwarte stanowiska tutaj.




