Text to Speech
Overview
ElevenLabs’ Text to Speech technology is integral to our offerings, powering high-quality AI-generated speech across various applications worldwide. It’s likely you’ve already encountered our voices in action, delivering lifelike audio experiences.
To get started generating your first audio using Text to Speech, it’s very simple. However, to get the most out of this feature, there are a few things you need to keep in mind.
Guide
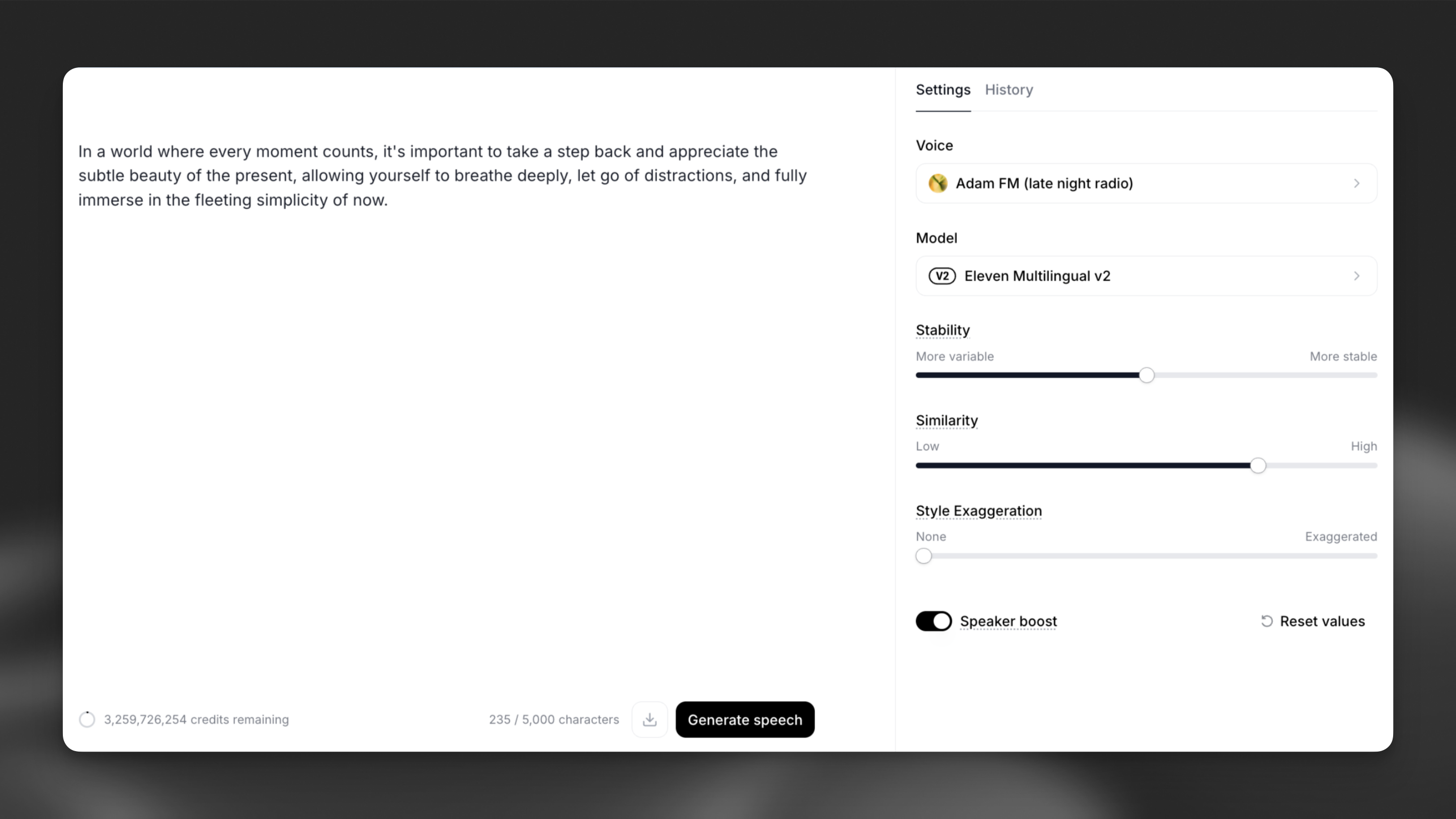
Settings
Get familiar with the voices, models & settings for creating high-quality speech.
The settings you use, especially the voice and the model, significantly impact the output. It’s quite important to get familiar with these and understand some best practices. While other settings also influence the output, their impact is less significant compared to the voice and model you select.
The order of importance goes as follows: Voice selection is most important, followed by Model selection, and then model Settings. All of these, and their combination, will influence the output.
Voices
Voices
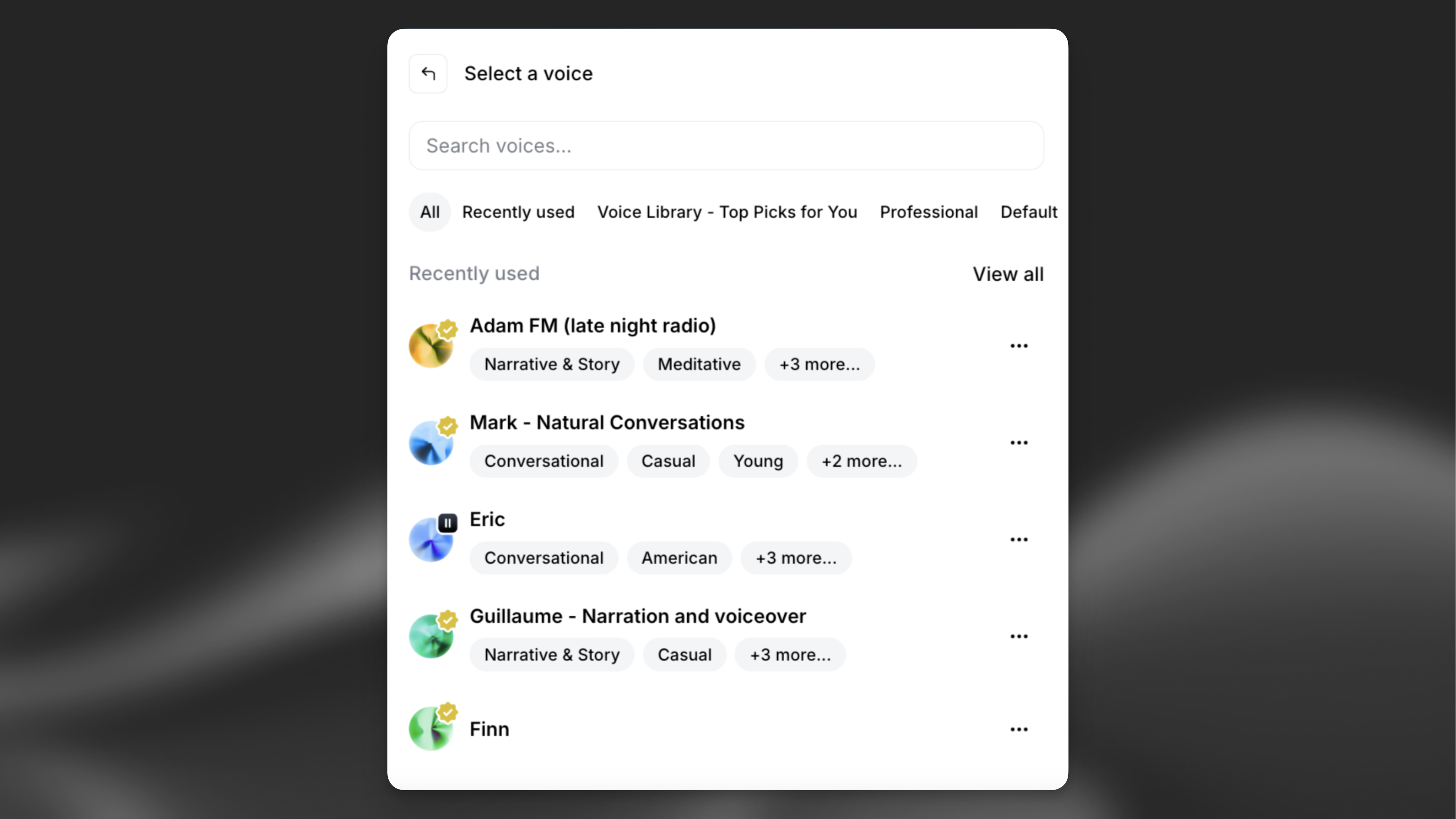
We offer many types of voices, including the curated Default Voices, our vast Voices Library with almost any voices you can imagine, completely synthetic voices created using our Voice Design tool, and you can create your own collection of cloned voices using our two technologies: Instant Voice Cloning and Professional Voice Cloning.
Not all voices are equal, and much depends on the source audio used to create them. Some voices will provide a better, more human performance and delivery, while others will be more stable.
Choosing the right voice for your specific content is crucial. This is most likely the most significant decision that will have the most significant impact on the final output. It determines the gender, tone, accent, cadence, and delivery. It’s worth spending extra time to select the perfect voice and properly test it to ensure it is consistent and meets your expectations.
For generating speech in a specific language, using a native voice from the Voice Library or cloning a voice speaking that language with the correct accent will yield the best results. While any voice can technically speak any language, it will retain its original accent. For example, using a native English voice to generate French speech will likely result in the output being in French but with an English accent, as the AI must generalize how that voice would sound in a language it wasn’t trained on.
If you have a voice that you like but want a different delivery, our Voice Remixing tool can help. It lets you use natural language prompts to change a voice’s delivery, cadence, tone, gender, and even accents. When changing accents, the base voice and target accent are very important. Results can vary; sometimes it works perfectly, while other times it might take a few tries to get it right.
You can get some really good results with Voice Remixing, but they will not usually be as good as a properly cloned Professional Voice Clone. They will be closer to that of an Instant Voice Clone.
Keep in mind, voice remixing only works for specific voices. For example, you can’t remix voices from the Voice Library; you can only remix voices that you have created yourself or the default voices.
Models
Models
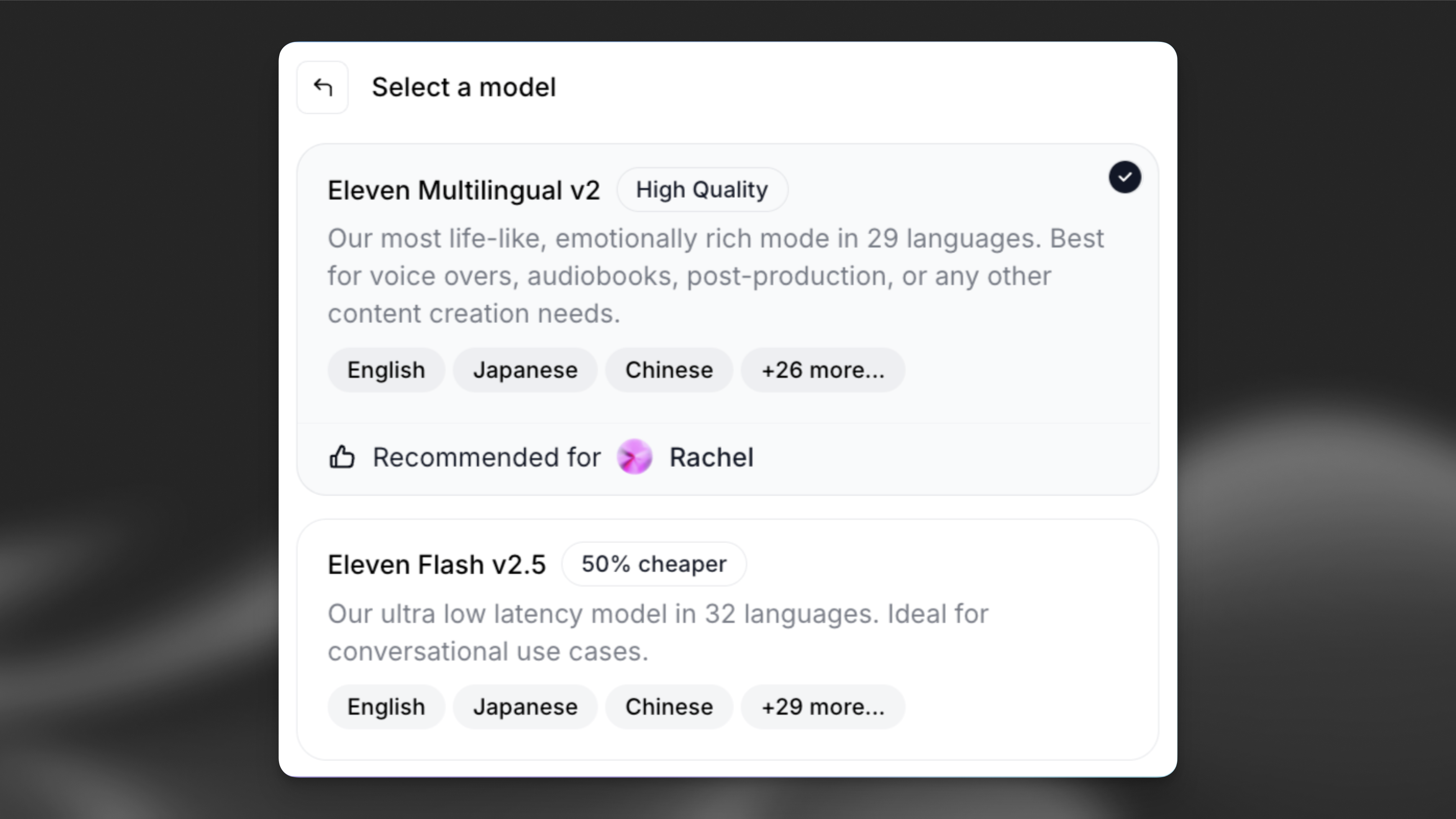
We offer two families of models: Standard (high-quality) models and Flash models, which are optimized for extremely low latency. Most families include both English-only and multilingual versions.
The Eleven v3 model currently only comes in one version: the standard multilingual version.
Model selection is the second most significant influence on your final audio output, right after voice selection. We recommend taking a moment to test the different models with your chosen voice to find the best fit. All of our models have strengths and weaknesses and work better with some voices than others, so finding a good pairing is important.
If your output will be exclusively in English, we strongly recommend using one of our English-only models. They are often easier to work with, more stable, and generally offer superior performance for English-only content. If your content will be in another language or potentially multilingual, you must use one of the multilingual models.
Our most emotionally rich, expressive speech synthesis model
Lifelike, consistent quality speech synthesis model
Our fast, affordable speech synthesis model
Voice settings
Voice settings
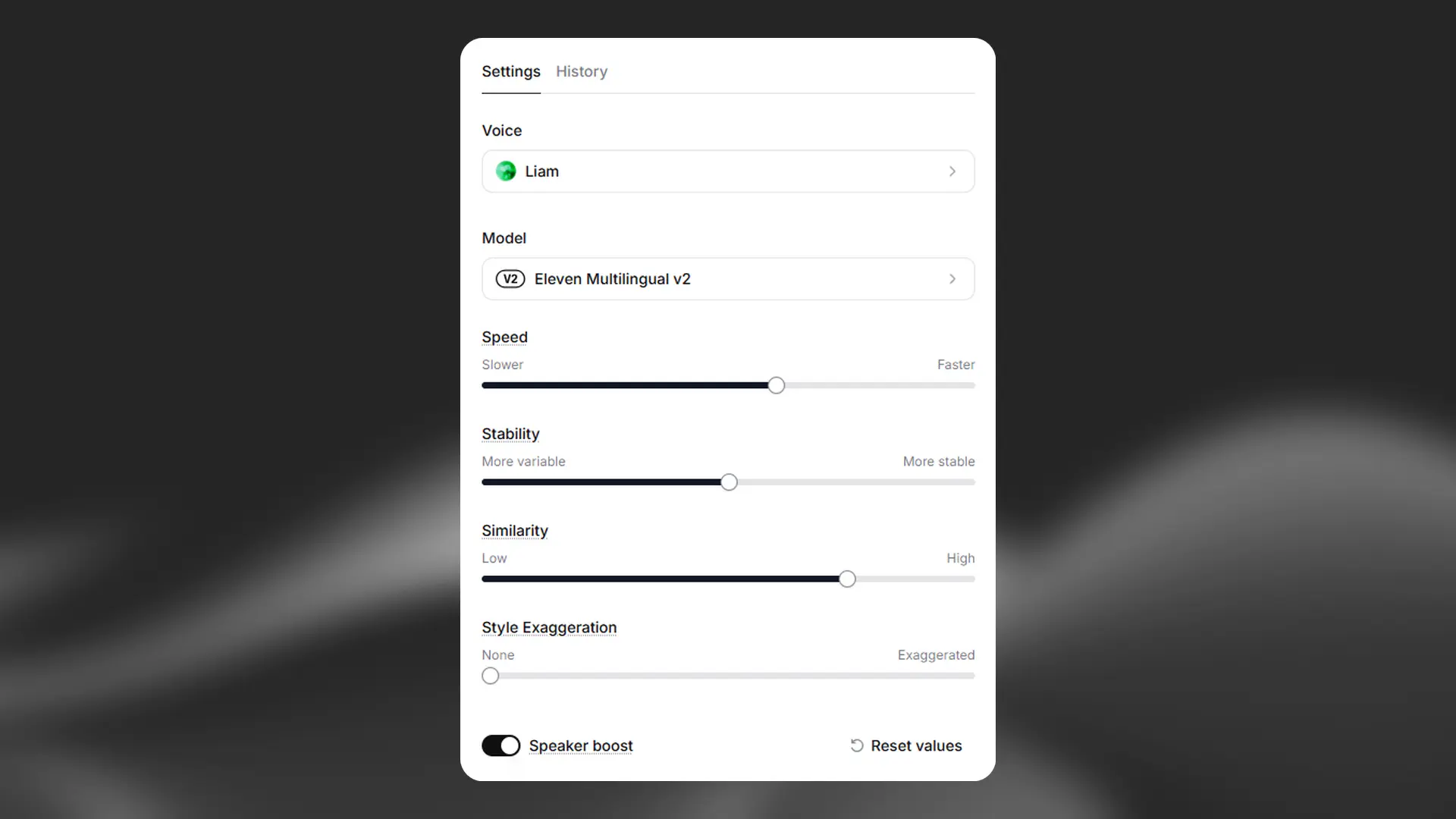
The most common setting is stability around 50, similarity around 75, and keeping style at 0, with minimal changes thereafter. Of course, this all depends on the original voice and the style of performance you’re aiming for.
It’s important to note that the AI is non-deterministic; setting the sliders to specific values won’t guarantee the same results every time. Instead, the sliders function more as a range, determining how wide the randomization can be between each generation.
Speed
The speed setting allows you to either speed up or slow down the speed of the generated speech. The default value is 1.0, which means that the speed is not adjusted. Values below 1.0 will slow the voice down, to a minimum of 0.7. Values above 1.0 will speed up the voice, to a maximum of 1.2. Extreme values may affect the quality of the generated speech.
Stability
The stability slider determines how stable the voice is and the randomness between each generation. Lowering this slider introduces a broader emotional range for the voice. As mentioned before, this is also influenced heavily by the original voice. Setting the slider too low may result in odd performances that are overly random and cause the character to speak too quickly. On the other hand, setting it too high can lead to a monotonous voice with limited emotion.
For a more lively and dramatic performance, it is recommended to set the stability slider lower and generate a few times until you find a performance you like.
On the other hand, if you want a more serious performance, even bordering on monotone at very high values, it is recommended to set the stability slider higher. Since it is more consistent and stable, you usually don’t need to generate as many samples to achieve the desired result. Experiment to find what works best for you!
Similarity
The similarity slider dictates how closely the AI should adhere to the original voice when attempting to replicate it. If the original audio is of poor quality and the similarity slider is set too high, the AI may reproduce artifacts or background noise when trying to mimic the voice if those were present in the original recording.
Style exaggeration
With the introduction of the newer models, we also added a style exaggeration setting. This setting attempts to amplify the style of the original speaker. It does consume additional computational resources and might increase latency if set to anything other than 0. It’s important to note that using this setting has shown to make the model slightly less stable, as it strives to emphasize and imitate the style of the original voice.
In general, we recommend keeping this setting at 0 at all times.
Speaker Boost
This setting boosts the similarity to the original speaker. However, using this setting requires a slightly higher computational load, which in turn increases latency. The differences introduced by this setting are generally rather subtle.
Generate
Once you have selected your voice, chosen a model, and configured your settings, the generation process is straightforward: you input text, press “Generate Speech,” and the audio is then generated.
Although the process is very simple on the surface, the text input you provide is extremely important for achieving the desired output. When using words that might be “outside of distribution”—meaning things the AI rarely encountered during training—such as strange names, unusual abbreviations, symbols, or even emojis, you can risk confusing the AI and making the output more unstable. Emojis and certain symbols are particularly difficult for the AI to interpret correctly.
When using Text to Speech via the UI, we run an automated normalization step on your input to improve text legibility and ease processing for the AI. Generally, this step converts symbols and numbers into written-out text, which guides the AI on correct pronunciation.
A best practice we strongly recommend is to avoid writing numbers as digits or using symbols, especially when using multilingual models (though this also applies to English-only models). Since numbers and symbols are written the same across many languages but pronounced differently, relying on digits creates ambiguity for the AI. For example, the number “1” is written identically in English and many other languages but pronounced differently. Writing out the number in text, such as “one,” removes the need for the AI to interpret what it is supposed to do.
We are working on more advanced workflows to allow you to influence the AI’s delivery and performance using what we call Audio Tags. This feature is available in our Eleven v3 model. If you’re interested in learning more about this feature, we recommend reading our Eleven v3 documentation.
FAQ
Good input equals good output
The first factor, and one of the most important, is that good, high-quality, and consistent input will result in good, high-quality, and consistent output.
If you provide the AI with audio that is less than ideal—for example, audio with a lot of noise, reverb on clear speech, multiple speakers, or inconsistency in volume or performance and delivery—the AI will become more unstable, and the output will be more unpredictable.
If you plan on cloning your own voice, we strongly recommend that you go through our guidelines in the documentation for creating proper voice clones, as this will provide you with the best possible foundation to start from. Even if you intend to use only Instant Voice Clones, it is advisable to read the Professional Voice Cloning section as well. This section contains valuable information about creating voice clones, even though the requirements for these two technologies are slightly different.
Use the right voice
The second factor to consider is that the voice you select will have a tremendous effect on the output. Not only, as mentioned in the first factor, is the quality and consistency of the samples used to create that specific clone extremely important, but also the language and tonality of the voice.
If you want a voice that sounds happy and cheerful, you should use a voice that has been cloned using happy and cheerful samples. Conversely, if you desire a voice that sounds introspective and brooding, you should select a voice with those characteristics.
However, it is also crucial to use a voice that has been trained in the correct language. For example, all of the professional voice clones we offer as default voices are English voices and have been trained on English samples. Therefore, if you have them speak other languages, their performance in those languages can be unpredictable. It is essential to use a voice that has been cloned from samples where the voice was speaking the language you want the AI to then speak.
Use proper formatting
This may seem slightly trivial, but it can make a big difference. The AI tries to understand how to read something based on the context of the text itself, which means not only the words used but also how they are put together, how punctuation is applied, the grammar, and the general formatting of the text.
This can have a small but impactful influence on the AI’s delivery. If you were to misspell a word, the AI won’t correct it and will try to read it as written.
Nondeterministic
The settings of the AI are nondeterministic, meaning that even with the same initial conditions (voice, settings, model), it will give you slightly different output, similar to how a voice actor will deliver a slightly different performance each time.
This variability can be due to various factors, such as the options mentioned earlier: voice, settings, model. Generally, the breadth of that variability can be controlled by the stability slider. A lower stability setting means a wider range of variability between generations, but it also introduces inter-generational variability, where the AI can be a bit more performative.
A wider variability can often be desirable, as setting the stability too high can make certain voices sound monotone as it does give the AI the same leeway to generate more variable content. However, setting the stability too low can also introduce other issues where the generations become unstable, especially with certain voices that might have used less-than-ideal audio for the cloning process.
The default setting of 50 is generally a great starting point for most applications.