Image & Video
Image & Video
Overview
Image & Video enables you to create high-quality visual content from simple text descriptions or reference images. Generate static images or dynamic videos in any style, then refine them iteratively with additional prompts, upscale for high-resolution output, and even add lip-sync with audio. Export finished assets as standalone files or import them directly into ElevenCreative Studio projects.
Some Image & Video models and input upload capabilities are restricted in the United States due to regulatory or provider requirements. Check individual model descriptions for specific availability.
Free plan users can only generate images and are limited to three image requests per day. Video generation requires a paid plan.
Guide
Follow these steps to create your first visual asset:
Select your mode
Use the toggle in the upper right corner of the prompt box to choose between Image or Video generation.
Provide a prompt or reference
Describe your desired output using natural language in the prompt box. For more control, drag existing images or videos from the Explore or History tabs into the reference slots, or upload your own reference images in a wide range of file formats including JPG, PNG, WEBP, and more.
Choose a model and settings
Select the ideal generative model for your goal (e.g., OpenAI Sora 2 Pro, Google Veo 3.1, Kling 2.5, Flux 1 Kontext Pro). See the Models section for detailed information on each model. Adjust settings like aspect ratio, resolution, duration (for video), and the number of variations to generate.
Generate your asset
Click the Generate button. Your assets will be created and displayed in the History tab for review.
Workflow
The creation process moves you from inspiration to finished asset in four stages:
Explore
Discover community creations to find inspiration, study effective prompts, or pull references directly into your own work.
Generate
Use the prompt box to describe what you want to create, select a model, fine-tune your settings, and bring your idea to life.
History
Review your generations in the History tab to iterate and enhance. Recreate variations, reuse prompts, and apply enhancements like upscaling and lip-syncing.
Export
Download finished assets in various formats or send them directly to ElevenCreative Studio to use in your projects.
Explore
The Explore tab displays a gallery of community creations for discovering inspiration and finding visuals to use as references.
Search: Use the search bar to find images and videos based on keywords.
Sort: Toggle between Trending and Newest to see what’s popular or recently added.
Drag-and-drop: Pull any result from the grid directly into the prompt box to use as a start frame, end frame, or style reference.
Preview details: Click any tile to see the full prompt and settings used to create it.
Generate
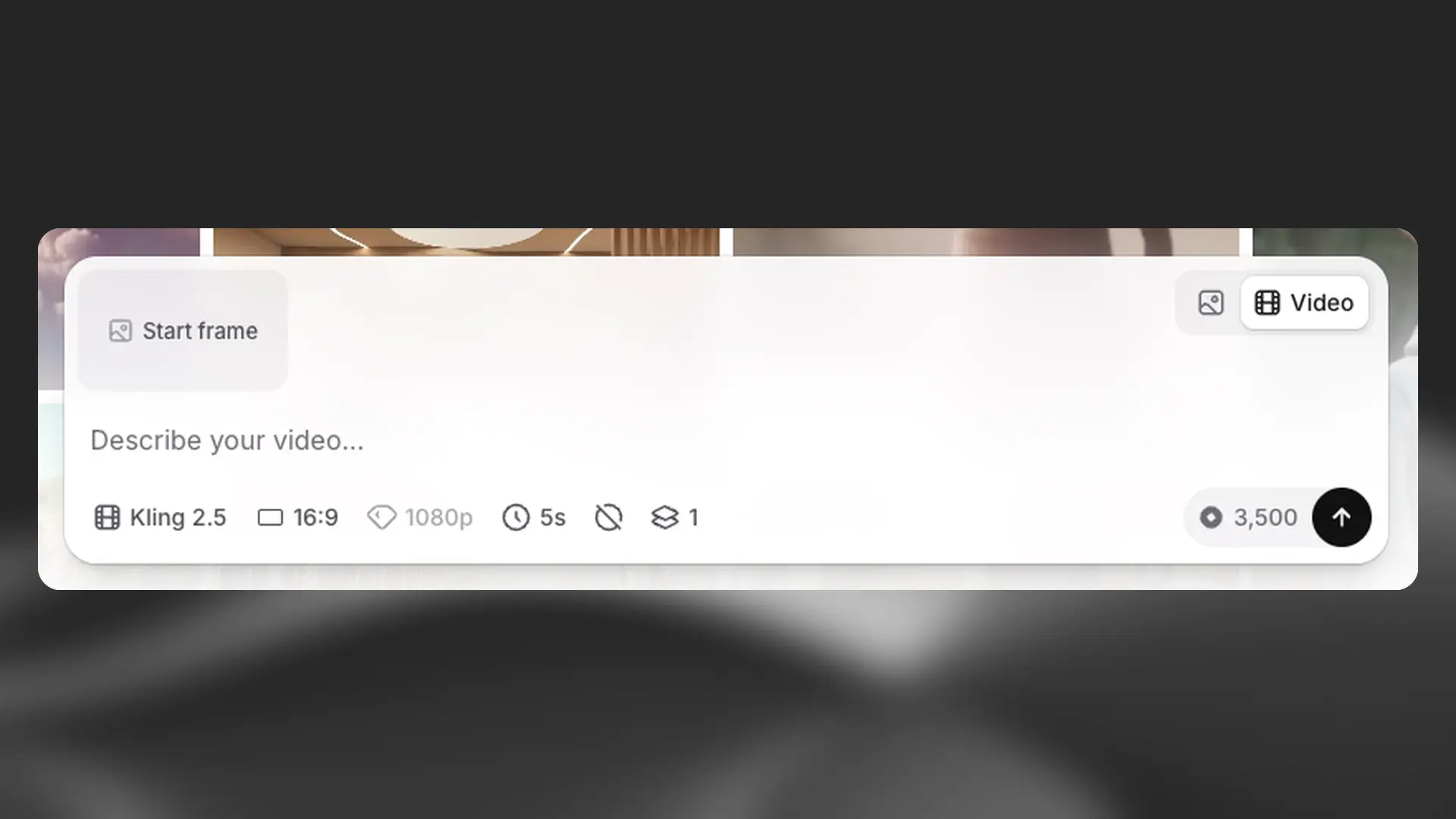
The prompt box is anchored at the bottom of the page and provides all controls for creating visual content.
Set mode and prompt
Select mode: Use the toggle in the upper right corner to switch between Image and Video generation.
Write your prompt: In the main field, describe what you want to generate using natural language. Be clear and descriptive for best results.
Choose models and settings
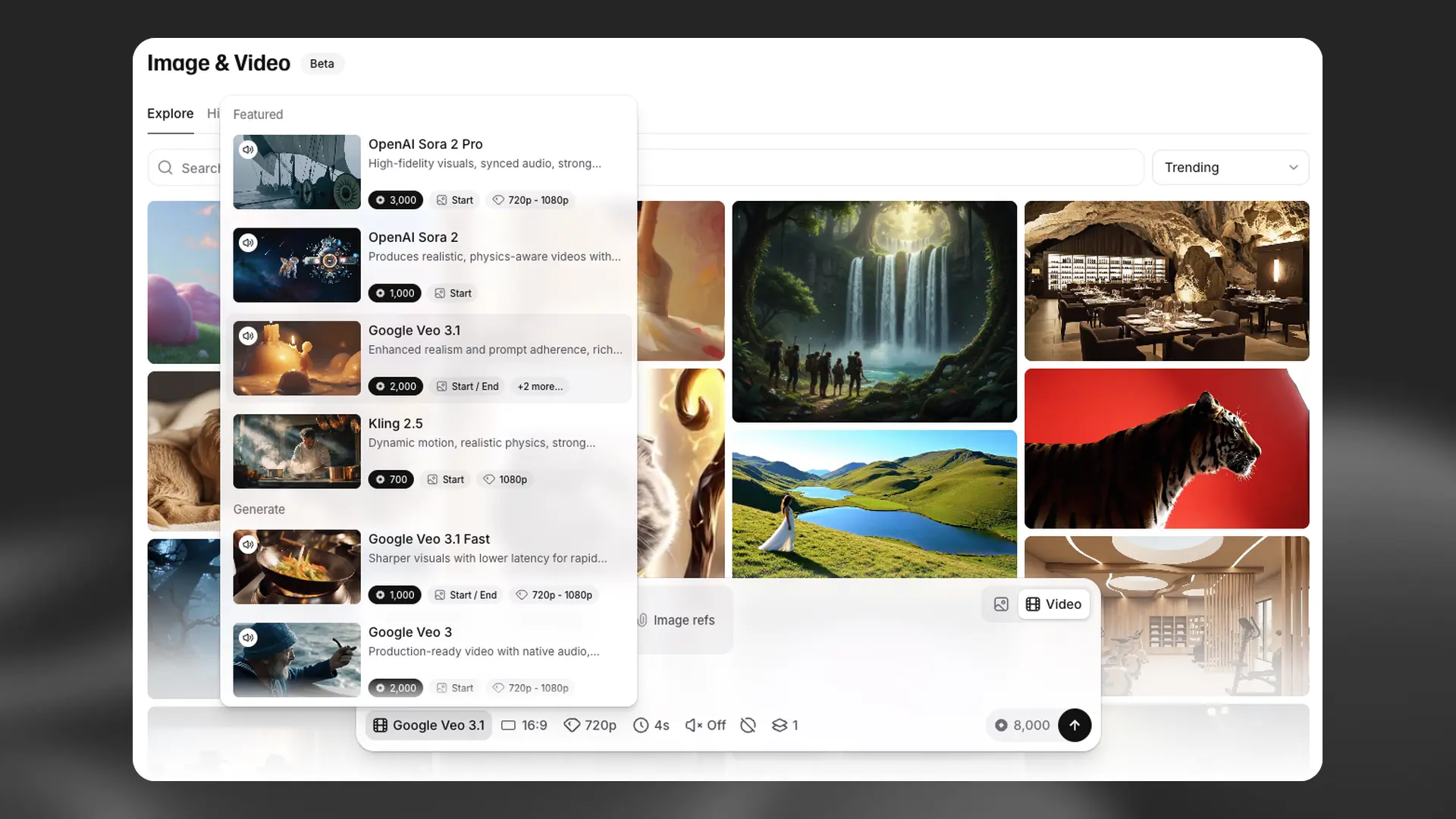
Select model: Open the model menu to browse available options like OpenAI Sora 2 Pro, Google Veo 3.1, Kling 2.5, or Flux 1 Kontext Pro. Each model has unique strengths and capabilities listed for easy comparison. See the Models section for detailed information.
Adjust settings: Fine-tune your generation with settings that appear below the prompt. These vary by model but often include:
- Aspect Ratio: Control the dimensions of your output
- Resolution: Set the quality level
- Duration: Specify video length (for video mode)
- Number of Generations: Create up to 4 variations at once
Use controls: On supported models, enable Audio, add a Negative Prompt to exclude unwanted elements, or adjust Sound Control.
Add references
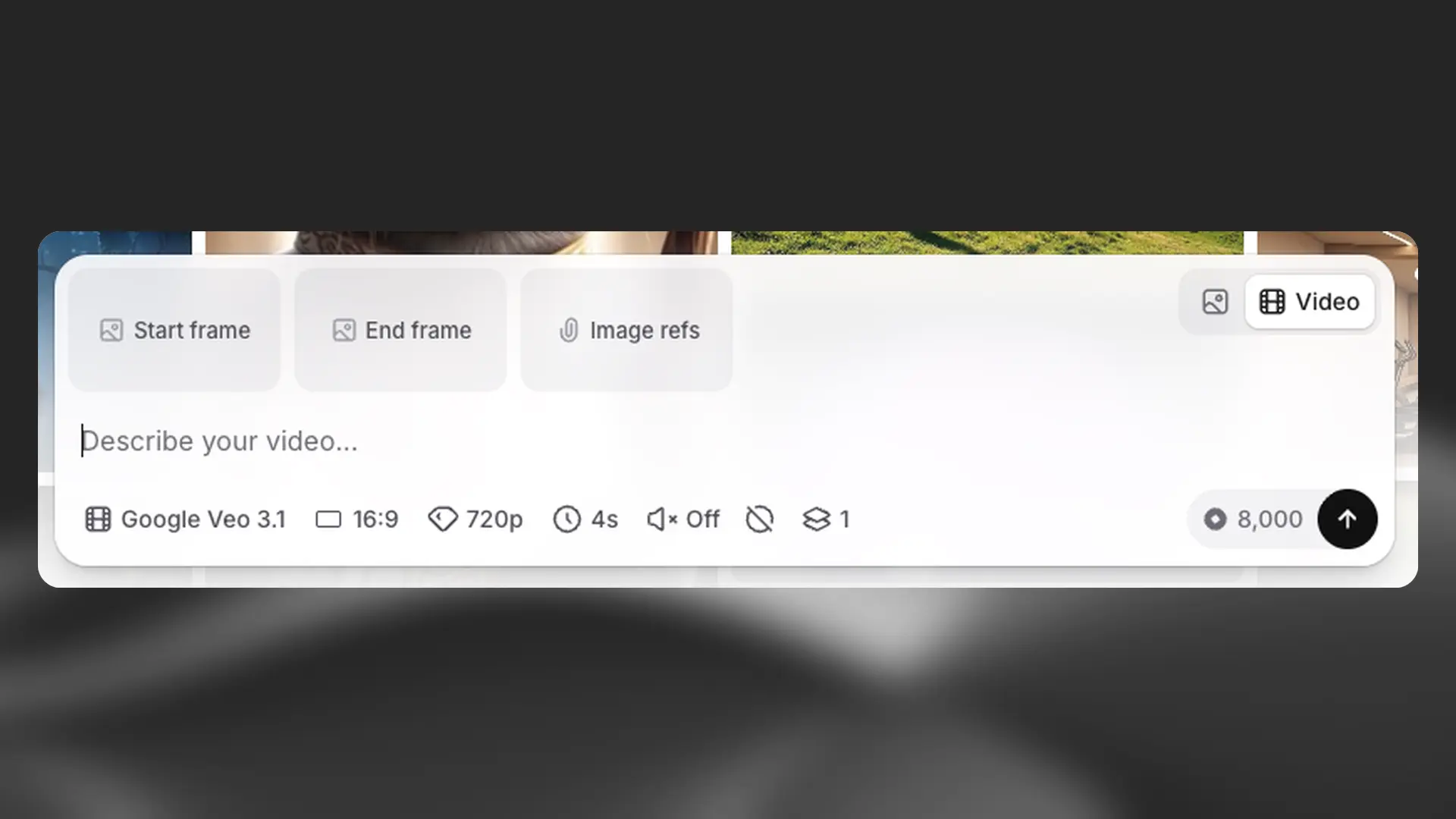
For greater control over output, add visual references to guide generation. Availability depends on the selected model. We support a wide range of image file formats including JPG, PNG, WEBP, and more.
Start Frame (Video): Sets the opening image of your video.
End Frame (Video): Sets the final image, influencing the transition.
Image Refs (Image or Video): Provide one or more images to guide overall style and look.
Drag and drop items directly from the Explore or History tabs into reference slots for a faster workflow.
Generate
Before generating, a cost indicator shows the total cost for the number of assets you’ve chosen to create. When ready, click Generate. Your new creations will appear in the History tab.
History
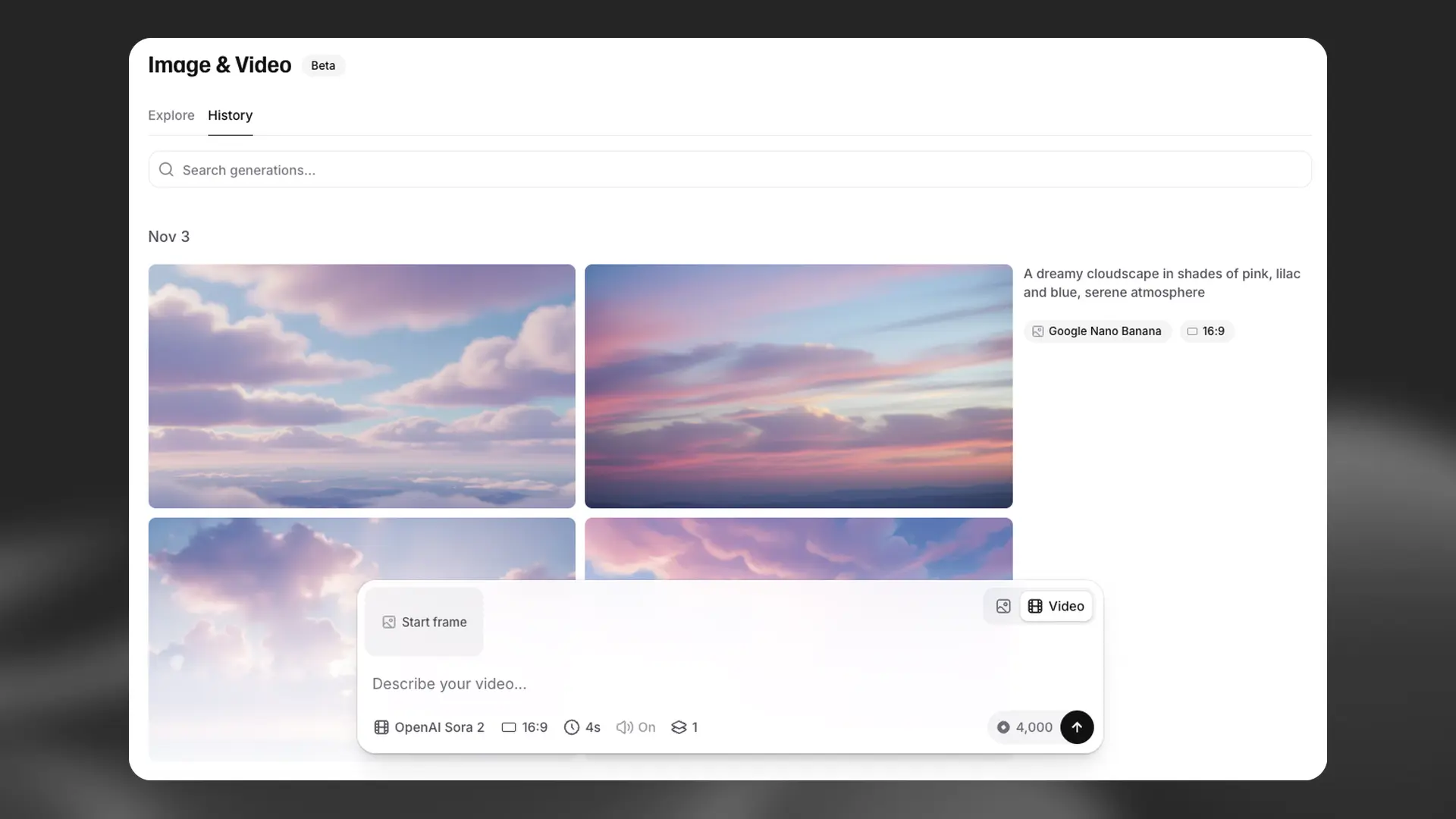
The History tab provides a chronological log of everything you’ve generated and serves as a workspace for refining previous work.
Browse: View all past images and videos.
Inspect: Click any asset to see the original prompt, model, and settings used to create it.
Reuse: Drag items from History back into the prompt box to use as references for new generations.
Iterate: Click Recreate to run the same prompt and settings again for a new variation, or adjust settings to guide generation in a new direction.
Share: Click Share to generate a unique link for your asset. Send it to teammates and collaborators for feedback.
Export: Download your asset as a standalone file or click Edit in Studio to import it directly into ElevenCreative Studio.
Export
Once you have a generation you’re satisfied with, use built-in enhancement tools before exporting.
Enhancing your creations
Upscale: Use Topaz Upscale to increase resolution by up to 4x while preserving sharp details.
LipSync: Apply realistic lip-syncing to your visuals:
- Omnihuman 1.5: Animate a static image with an audio track
- Veed LipSync: Dub an existing video with new audio
Exporting your assets

Export finished assets by downloading them locally or sending them directly to ElevenCreative Studio.
Edit in Studio: Import the asset directly into an ElevenCreative Studio project.
Download: Save the asset to your local machine.
Supported download formats
Video:
- MP4: Codecs H.264, H.265. Quality up to 4K (with upscaling)
Image:
- PNG: High-resolution, lossless output
Models
Image & Video provides access to specialized models optimized for different use cases. Each model offers unique capabilities, from rapid iteration to production-ready quality.
Post-processing models require an existing generated output, though you can also upload your own image or video file.
Enterprise workspace admins can control which image and video generation models are available to workspace members. By default, all models are disabled for Enterprise workspaces and must be explicitly enabled by admins. Learn more about Model approvals.
Video generative models
Seedance 2.0
A unified multimodal video model with audio-video joint generation, offering director-level control over performance, lighting, shadow, and camera movement for ultra-realistic, cinematic results.
Generation inputs:
- Text-to-Video
- Start Frame
- End Frame
- Image References
- Video References
- Audio References
Features:
- Unified multimodal architecture that jointly generates synchronized audio and video in a single pass
- Industry-leading multimodal reference and editing capabilities, accepting text, image, audio, and video inputs simultaneously
- Exceptional motion stability with cinematic-grade realism aligned to industry standards
- Director-level creative control over performance, lighting, shadow, and camera movement
- Flexible generation lengths from 4s up to 15s
- Native sound control with audio enabled or disabled per generation
- Batch creation with up to 4 generations at a time
Output options:
- Resolutions: 480p, 720p, 1080p
- Aspect ratios: 21:9, 16:9, 4:3, 1:1, 3:4, 9:16
Ideal for:
- Cinematic storytelling requiring synchronized audio and visuals
- Reference-driven content with strict adherence to source images, videos, or audio
- Professional productions requiring fine-grained control over lighting and camera work
Cost: Varies based on selected settings and duration
Settings can be toggled to adjust credit consumption.
Seedance 2.0 is not available in the United States.
Kling 3.0
An advanced video model that functions like an AI director, maintaining high consistency for characters, items, and scenes across complex camera movements.
Generation inputs:
- Text-to-Video
- Start Frame
- End Frame
Features:
- High-fidelity character and scene retention using multi-angle image or video references
- Native audio-visual co-generation with multilingual lip-sync and environmental sound
- Flexible generation lengths from 3s up to 15s
- Generate up to 4 variations simultaneously
- Enhanced handling of text, fluid dynamics, and complex physical interactions
Output options:
- Resolutions: 1080p only
- Aspect ratios: 16:9, 1:1, 9:16
Ideal for:
- Character-driven storytelling requiring visual continuity
- Commercials and assets with specific text-rendering needs
Cost: Varies based on selected settings and duration
Supports negative prompts for granular control. Sound can be enabled or disabled per generation.
Kling 3.0 is not available in the United States.
Kling O3
A high-consistency video model that functions like an AI director, preserving the identity of characters, items, and scenes across complex camera movements.
Generation inputs:
- Text-to-Video
- Start Frame
- End Frame
- Video Reference
- Image Reference
Features:
- Maintains precise visual identity for main characters and items using multi-angle references
- Supports seamless generation lengths from 3s up to 15s
- Generate up to 4 variations at a time
- Accurate modeling of element interactions and motion coherence
- Native support for enabled or disabled audio per generation
Output options:
- Resolutions: 1080p only
- Aspect ratios: 16:9, 1:1, 9:16
Ideal for:
- Character-driven storytelling requiring strict visual continuity
- Professional marketing and brand assets with consistent item rendering
Cost: Varies based on selected settings and duration
Settings can be toggled to adjust credit consumption.
Kling O3 is not available in the United States.
Kling O3 Edit
A natural language-driven video-to-video editing model based on the O3 architecture, enabling complex visual transformations—such as character replacement and environment swaps—without the need for manual masking or frame-by-frame adjustments.
Generation inputs:
- Source Video
- Image References (up to 4 distinct elements/angles)
- Text Description (Natural language instructions)
Features:
- Interprets conversational prompts to replace subjects or settings while respecting the original motion structure
- Maintains original camera angles, movement patterns, and spatial relationships throughout the edit
- Combines up to 4 total elements (including frontal and multi-angle images) to ensure high-fidelity character consistency
- Option to preserve original source audio or generate silent output per generation
- Generate up to 4 edited variations at a time
Output options:
- Resolutions: Dependent on source video
- Aspect ratios: Matches source video
Ideal for:
- High-fidelity character replacement in existing footage while keeping original movements
- Complete scene environment transformations (e.g., changing a daytime city to a futuristic nightscape)
- Applying style transfers that require strict adherence to existing camera dynamics
Cost: Varies based on video duration and selected settings
Kling O3 Edit is not available in the United States.
Google Veo 3.1
A professional-grade model for high-quality, cinematic video generation.
Generation inputs:
- Text-to-Video
- Start Frame
- End Frame
- Image References
Features:
- Excellent quality and creative control with negative prompts
- Fully integrated and synchronized audio
- Realistic dialogue, lip-sync, and sound effects
- Fixed durations: 4s, 6s, and 8s
- Batch creation with up to 4 generations at a time
- Dedicated sound control
Output options:
- Resolutions: 720p, 1080p
- Aspect ratios: 16:9, 9:16
Ideal for:
- High-quality, cinematic video generation with full creative control
Cost: Varies based on selected settings and duration
Enabling and disabling sound will change the generation credits.
Google Veo 3.1 Fast
A high-speed model optimized for rapid previews and generations, delivering sharper visuals with lower latency.
Generation inputs:
- Text-to-Video
- Start Frame
- End Frame
Features:
- Advanced creative control with negative prompts and dedicated sound control
- Fixed durations: 4s, 6s, and 8s
- Batch creation with up to 4 generations at a time
- Accurately models real-world physics for realistic motion and interactions
Output options:
- Resolutions: 720p, 1080p
- Aspect ratios: 16:9, 9:16
Ideal for:
- Quick iteration and A/B testing visuals
- Fast-paced social media content creation
Cost: Varies based on selected settings and duration
Google Veo 3.1 Lite
A cost-efficient, high-speed variant of Veo 3.1 optimized for rapid generation at reduced compute.
Generation inputs:
- Text-to-Video
- Start Frame
Features:
- Granular creative control with negative prompts and dedicated sound control
- Fixed durations: 4s, 6s, and 8s
- Batch creation with up to 4 generations at a time
Output options:
- Resolutions: 720p
- Aspect ratios: 16:9, 9:16
Ideal for:
- High-volume content creation where speed and cost efficiency are prioritized
- Rapid concept exploration and previews
Cost: Varies based on selected settings and duration
Seedance 1.5 Pro
An upgraded specialized model for creating dynamic, high-fidelity sequences with enhanced temporal stability and precise transition control between keyframes.
Generation inputs:
- Text-to-Video
- Start Frame
- End Frame
Features:
- Seamlessly bridges start and end frames for coherent, multi-shot sequences
- High-fidelity modeling of complex actions and environmental consistency
- Supports fixed generation lengths from 4s up to 12s
- Generate up to 4 variations at a time
- Native support for enabled or disabled audio per generation
Output options:
- Resolutions: 420p, 720p
- Aspect ratios: 21:9, 16:9, 4:3, 1:1, 3:4, 9:16
Ideal for:
- Storytelling and action scenes requiring stable physics between specific visual benchmarks
- Cinematic transitions and professional video assets with strict start/end requirements
Cost: Varies based on selected settings and duration
Seedance 1.5 Pro is not available in the United States.
OpenAI Sora 2
The standard, high-speed version of OpenAI’s advanced video model, tuned for everyday content creation.
Generation inputs:
- Text-to-Video
- Start Frame
Features:
- Realistic, physics-aware videos with synced audio
- Fine scene control
- Fixed durations: 4s, 8s, and 12s
- Batch creation with up to 4 generations at a time
- Strong narrative and character consistency
Output options:
- Resolutions: 720p, 1080p
- Aspect ratios: 16:9, 9:16
Ideal for:
- Everyday content creation with realistic physics
Cost: Varies based on selected settings and duration
End frame is not currently supported. Cannot provide image references. Sound is enabled by default.
OpenAI Sora 2 Pro
The most advanced, high-fidelity video model for cinematic results at your disposal.
Generation inputs:
- Text-to-Video
- Start Frame
Features:
- Highest-fidelity, professional-grade output with synced audio
- Precise multi-shot control
- Excels at complex motion and prompt adherence
- Fixed durations: 4s, 8s, and 12s
- Batch creation with up to 4 generations at a time
Output options:
- Resolutions: 720p, 1080p
- Aspect ratios: 16:9, 9:16
Ideal for:
- Cinematic, professional-grade video content
Cost: Varies based on selected settings and duration
End frame is not currently supported. Cannot provide image references. Sound is enabled by default.
Kling O1
A state-of-the-art reasoning video model designed for superior prompt adherence and complex physical world simulation, utilizing advanced logical processing to interpret and execute intricate instructions.
Generation inputs:
- Text-to-Video (Description)
- Start Frame & End Frame
- Video Reference
- Image Reference
Features:
- Exceptional ability to interpret multi-layered prompts and execute complex chronological actions
- Leverages both images and videos as visual anchors to maintain high character and scene consistency
- Superior modeling of physical interactions, cause-and-effect, and fluid dynamics
- Supports high-quality generation for 5s and 10s clips
- Generate up to 4 variations at a time
Output options:
- Resolutions: Dependant on the input
- Aspect ratios: 16:9, 1:1, 9:16
Ideal for:
- Highly specific creative concepts requiring precise adherence to long, detailed descriptions
- Professional storytelling where physical realism and multi-reference consistency are critical
Cost: Varies based on selected settings and duration
Kling O1 is not available in the United States.
Kling O1 Edit
A natural language-driven video-to-video editing model that enables complex visual transformations—such as character replacement and environment swaps—without the need for manual masking or frame-by-frame adjustments.
Generation inputs:
- Source Video
- Image References (up to 4 distinct elements/angles)
- Text Description (Natural language instructions)
Features:
- Interprets conversational prompts to replace subjects or settings while respecting the original motion structure
- Maintains original camera angles, movement patterns, and spatial relationships throughout the edit
- Combines up to 4 total elements (including frontal and multi-angle images) to ensure high-fidelity character consistency
- Option to preserve original source audio or generate silent output per generation
- Generate up to 4 edited variations at a time
Output options:
- Resolutions: Dependent on source video
- Aspect ratios: Matches source video
Ideal for:
- High-fidelity character replacement in existing footage while keeping original movements
- Complete scene environment transformations (e.g., changing a daytime city to a futuristic nightscape)
- Applying style transfers that require strict adherence to existing camera dynamics
Cost: Varies based on video duration and selected settings
Kling O1 Edit is not available in the United States.
Kling 2.6 Motion Control
A specialized model for precise motion transfer, allowing you to drive a character image with a reference video to replicate specific movements, gestures, and camera angles.
Generation inputs:
- Character Image (Source)
- Motion Video (Reference)
- Text Description (Optional)
Features:
- Choose “Match Video” for exact motion replication or “Match Image” for adding new creative motion to a character
- Supports up to 30s in Match Video mode and 10s in Match Image mode
- High-fidelity mapping of human movement from reference footage to a still character
- Native support for enabling or disabling audio per generation
- Generate up to 4 variations at a time
Output options:
- Resolutions: Dependent on the source
- Aspect ratios: Dependent on the source
Ideal for:
- Replicating complex choreography or specific movements on a custom character
- Long-form character animation requiring high motion fidelity
- Social media content driven by trending video movements
Cost: Varies based on selected settings and duration
Kling 2.6 Motion Control is not available in the United States.
Kling 3.0 Motion Control
A specialized model for precise motion transfer built on the Kling 3.0 architecture, allowing you to drive a character image with a reference video to replicate specific movements, gestures, and camera angles with enhanced fidelity.
Generation inputs:
- Character Image (Source)
- Motion Video (Reference)
- Text Description (Optional)
Features:
- Choose “Match Video” for exact motion replication or “Match Image” for adding new creative motion to a character
- Supports up to 30s in Match Video mode and 10s in Match Image mode
- High-fidelity mapping of human movement from reference footage to a still character
- Native support for enabling or disabling audio per generation
- Generate up to 4 variations at a time
Output options:
- Resolutions: Dependent on the source
- Aspect ratios: Dependent on the source
Ideal for:
- Replicating complex choreography or specific movements on a custom character
- Long-form character animation requiring high motion fidelity
- Social media content driven by trending video movements
Cost: Varies based on selected settings and duration
Kling 3.0 Motion Control is not available in the United States.
Kling 2.6
An optimized generative model designed for enhanced motion fidelity and smoother transitions, providing a balance between high-speed iteration and production-quality visual output.
Generation inputs:
- Text-to-Video
- Start Frame (Image-to-Video)
Features:
- Enhanced motion dynamics: Significant improvements in movement fluidity and realistic physics interactions
- Flexible sound control: Native support for enabling or disabling audio per generation
- Batch creation: Generate up to 4 variations simultaneously
- Granular refinement: Advanced creative control through negative prompt support
- Fixed durations: Supports generation lengths of 5s and 10s
Output options:
- Resolutions: Dependant on the input
- Aspect ratios: 16:9, 1:1, 9:16
Ideal for:
- High-action clips requiring fluid character movement
- Professional-grade social media content with strong prompt adherence
Cost: Varies based on selected settings and duration
Kling 2.6 is not available in the United States.
Kling 2.5
A balanced and versatile model for high-quality, full-HD video generation.
Generation inputs:
- Text-to-Video
- Start Frame
Features:
- Excels at simulating complex motion and realistic physics
- Accurately models fluid dynamics and expressions
- Fixed durations: 5s and 10s
- Batch creation with up to 4 generations at a time
Output options:
- Resolutions: 1080p
- Aspect ratios: 16:9, 1:1, 9:16
Ideal for:
- Realistic physics simulations and complex motion
Cost: Varies based on selected settings and duration
End frame is not currently supported. Cannot provide image references. Sound control not available.
Kling 2.5 is not available in the United States.
Runway Gen-4.5
State-of-the-art motion quality, prompt adherence, and visual fidelity for cinematic, highly realistic video.
Generation inputs:
- Text-to-Video
- Start Frame (Image-to-Video)
Features:
- Exceptional motion quality with industry-leading realism and physics simulation
- Superior prompt adherence for precise creative control over complex scenes
- High visual fidelity delivering cinematic-grade output
- Generate up to 4 variations simultaneously
Output options:
- Resolutions: 720p
- Aspect ratios: 16:9, 9:16
Ideal for:
- Cinematic content requiring the highest motion quality and realism
- Professional productions demanding precise prompt adherence
- High-fidelity visual storytelling
Cost: Varies based on selected settings and duration
Runway Gen-4 Turbo
An advanced video model designed for rapid iteration and cost-effective creation, capable of producing high-quality videos.
Generation inputs:
- Text-to-Video
- Start Frame (Image-to-Video)
Features:
- Optimized for ultra-fast generation, delivering results up to four times faster than previous iterations
- Allows for precise direction of character movements, camera angles, and scene compositions
- Excels at maintaining visual coherence and stability across dynamic scenes
- Supports generation lengths ranging from 2s up to 10s
- Generate up to 4 variations simultaneously
Output options:
- Resolutions: 720p
- Aspect ratios: 21:9, 16:9, 4:3, 1:1, 3:4, 9:16
Ideal for:
- Rapid prototyping and creative experimentation requiring near-instant feedback
- Professional projects needing quick turnarounds for high-resolution marketing assets
- Cinematic content with specific camera movement requirements
Cost: Varies based on selected settings and duration
Runway Gen-4 Aleph
A state-of-the-art in-context video model designed for multi-task visual generation, capable of performing complex edits while maintaining the underlying structure of the source footage.
Generation inputs:
- Source Video
- Reference Image
- Text Description
Features:
- Seamlessly add, remove, or transform objects and subjects within a scene with natural lighting, shadows, and perspective
- Change locations, seasons, and time of day (e.g., converting cloudy footage to a dramatic sunset) with realistic color temperature updates
- Modify the age and appearance of actors or retexture clothing and subjects through simple natural language prompts
- Apply the specific motion and camera path of a reference video to a static image for precise animation control
- Generate entirely new camera angles, such as reverse shots or low angles, from a single existing video sequence
- Includes precise green-screening (isolation with edge detection), next-shot generation for story continuation, and aesthetic style transfer
- Generate up to 4 variations simultaneously
Output options:
- Resolutions: 720p
- Aspect ratios: Auto
Ideal for:
- Professional visual effects tasks like digital de-aging, relighting, and object removal
- Rapid cinematic prototyping and generating alternative camera coverage from a single shot
- Creative marketing content requiring drastic environmental or stylistic transformations
Cost: Varies based on selected settings and duration
Runway Act-Two
A specialized performance-transfer model that animates characters by mapping the motion, speech, and facial expressions from a driving video onto a character image or video reference.
Generation inputs:
- Driving Performance (Video)
- Character Input (Image or Video)
Features:
- Transfers nuanced facial expressions, lip-sync, and synchronized audio directly from a source actor to any character
- Automatically adds secondary motion and subtle camera shakes to static character images for a more natural look
- Precise toggle to enable or disable body and hand movements when using a character image
- Adjustable settings to balance between intense emotional performance and character visual consistency
- Ability to change the character’s voice after generation while maintaining perfect alignment with the driving performance
Output options:
- Resolutions: 720p
- Aspect ratios: Auto
Ideal for:
- Bringing static character portraits to life with realistic human motion and speech
- Animating non-human characters or stylized avatars with high-fidelity expressions
- Rapidly producing talking-head content with integrated body gestures
Cost: Varies based on selected settings and duration
Seedance 1 Pro
A specialized model for creating dynamic, multi-shot sequences with large movement and action.
Generation inputs:
- Text-to-Video
- Start Frame
- End Frame
Features:
- Highly stable physics and seamless transitions between shots
- Fixed durations: 3s, 4s, 5s, 6s, 7s, 8s, 9s, 10s, 11s, and 12s
- Batch creation with up to 4 generations at a time
- Maximum creative flexibility with numerous aspect ratio options
Output options:
- Resolutions: 480p, 720p, 1080p
- Aspect ratios: 21:9, 16:9, 4:3, 1:1, 3:4, 9:16
Ideal for:
- Storytelling and action scenes requiring stable physics
Cost: Varies based on selected settings and duration
Aspect ratio and resolution do not affect generation credits, but duration does.
Seedance 1 Pro is not available in the United States.
LTX Audio-to-Video
A DiT-based foundation model designed to generate synchronized video and audio in a single pass, ensuring coherent speech and realistic motion.
Generation inputs:
- Text-to-Video
- Image-to-Video
- Audio-to-Video
- Depth-to-Video
Features:
- Generates dialogue, lip movement, and ambient audio simultaneously for perfect alignment without external tools
- Dynamic scenes with stable motion, consistent identity, and strong frame-to-frame coherence
- Supports high-fidelity synchronized generation for up to 20 seconds
- Advanced creative direction through granular negative prompt support
- Generate up to 4 variations at a time
Output options:
- Resolutions: 720p, 1080p
- Aspect ratios: 16:9, 4:3, 1:1, 3:4, 9:16
Ideal for:
- Coherent speech and expressive character performances
- Narrative content requiring integrated ambient audio and consistent timing
- Dynamic scenes with complex camera-aware motion logic
Cost: Varies based on selected settings and duration
LTX 2 Pro
A high-fidelity generative model optimized for maximum visual detail and structural stability, capable of producing production-grade 4K output with fluid motion.
Generation inputs:
- Text-to-Video
- Start Frame (Image-to-Video)
Features:
- Prioritizes visual quality and consistency over speed, ensuring stable results across extended sequences
- Supports both 25 FPS and 50 FPS for exceptionally smooth and professional motion
- Integrated audio-visual generation with a toggle for sound on or off
- Built to handle native 1080p, 2k, and 4k outputs without loss of detail
- Generate up to 4 variations at a time
Output options:
- Resolutions: 1080p, 2k, 4k
- Frame rates: 25 FPS, 50 FPS
- Aspect ratio: 16:9 (Default)
- Durations: 6s, 8s, 10s
Ideal for:
- High-resolution cinematic production requiring 4K clarity
- Professional content necessitating smooth 50 FPS motion
- Detailed sequences where visual stability and structural integrity are critical
Cost: Varies based on selected settings and duration
LTX 2 Retake
A precision AI directing tool that allows for targeted redirection of dialogue, emotion, and action within existing shots without breaking continuity or regenerating the entire sequence.
Generation inputs:
- Source Video
- Text Description
Features:
- Modify specific segments while maintaining strong context preservation from surrounding frames
- Rephrase spoken lines while keeping the character’s voice, performance, and environment consistent
- Multiple edit modes: Select between “Audio & Video,” “Audio only,” or “Video only” to isolate and regenerate specific elements of the shot
- New content naturally inherits the original motion, lighting, and tone for seamless transitions
- Instantly experiment with alternate character reactions, emotional beats, or camera movements within a single shot
- Generate up to 4 variations simultaneously for side-by-side creative comparison
Output options:
- Aspect ratios: 16:9 only
Ideal for:
- Adjusting scripts and refining dialogue without the need for reshoots or rerecording
- Fixing emotional beats or pacing issues in post-production
- Testing multiple brand messages and calls-to-action within a single marketing asset
Cost: Varies based on selected settings and duration
LTX 2 Fast
A speed-optimized generative model built for tight feedback loops and high-velocity content creation, delivering high-resolution visuals with significantly reduced render times.
Generation inputs:
- Text-to-Video
- Start Frame (Image-to-Video)
Features:
- Engineered for speed and rapid iteration, allowing for quick visual experimentation and near-instant previews
- Supports native 1080p, 2k, and 4k outputs with lower compute overhead than the Pro model
- Capabilities for both 25 FPS and 50 FPS for smooth motion at high speeds
- Enables rapid generation of synchronized audio-visual content for durations up to 20 seconds
- Native support for enabling or disabling audio per generation
- Generate up to 4 variations simultaneously
Output options:
- Resolutions: 1080p, 2k, 4k
- Frame rates: 25 FPS, 50 FPS
- Aspect ratio: 16:9 (Default)
- Durations: 6s, 8s, 10s, 12s, 14s, 16s, 18s, 20s
Ideal for:
- Rapid prototyping and creative exploration where speed is prioritized over maximum detail
- High-volume social media content requiring quick turnarounds
- A/B testing different visual concepts and motion styles
Cost: Varies based on selected settings and duration
Wan 2.6
A next-generation cinematic video platform that utilizes a unified multimodal architecture to deliver production-ready 1080p content with native audio synchronization and intelligent multi-shot sequencing.
Generation inputs:
- Text-to-Video
- Start Frame (Image-to-Video)
- Video Reference (Video-to-Video)
- Audio Reference (Optional background audio or dialogue)
Features:
- Unified multimodal system: Processes text, images, video, and audio through a single integrated framework for consistent output quality
- Native audio sync: Automatically generates and aligns dialogue, narration, and environmental sound effects with on-screen movement
- Intelligent multi-shot sequencing: Automatically organizes connected video sequences into coherent story arcs while maintaining character consistency
- Extended durations: Supports stable, high-quality generation for fixed lengths of 5s, 10s, and 15s
- Advanced creative control: Supports negative prompts for granular detail management and batch creation of up to 4 variations
Output options:
- Resolutions: 720p, 1080p
- Aspect ratios: 16:9, 4:3, 1:1, 3:4, 9:16
Ideal for:
- Professional narrative storytelling and complex multi-shot cinematic sequences
- Social media ads and marketing content requiring integrated, high-fidelity audio
- Character-driven content requiring strict visual and motion consistency via video references
Cost: Varies based on selected settings and duration
Wan 2.6 is not available in the United States.
Wan 2.5
A versatile model that delivers cinematic motion and high prompt fidelity from text or a starting image.
Generation inputs:
- Text-to-Video
- Start Frame (Image-to-Video)
Features:
- Granular creative control with negative prompts and dedicated sound control
- Fixed durations: 5s and 10s
- Batch creation with up to 4 generations at a time
Output options:
- Resolutions: 480p, 720p, 1080p
- Aspect ratios: 16:9, 1:1, 9:16
Ideal for:
- Cinematic content with strong prompt adherence
Cost: Varies based on selected settings and duration
Generation cost varies based on selected settings.
Wan 2.5 is not available in the United States.
Image generative models
GPT Image 2
An advanced AI model designed for precise image generation with enhanced text rendering and high-resolution output capabilities.
Features:
- Precise text control for creating images with accurate typography and clarity
- High-resolution PNG output suitable for professional and commercial use
- Supports multiple image references to guide style and composition
- Generates up to 4 images at a time
Output options:
- Aspect ratios: 3:2, 1:1, 2:3
- Quality options: low, medium, high
Ideal for:
- Marketing visuals and design assets requiring precise text placement
- Professional content with high-resolution requirements
- Creative projects needing accurate text-based image control
Cost: Varies based on selected settings and number of variations
Nano Banana 2
An advanced AI image generation model combining production-ready quality with ultra-fast processing, featuring improved world knowledge and subject consistency.
Features:
- Native 4K resolution output without upscaling for crystal-clear detail
- Lightning-fast image generation in as little as 1-2 seconds
- Superior prompt adherence through advanced reasoning and instruction following
- Crisp, accurate text rendering in multiple languages for mockups, signage, and infographics
- Consistent multi-subject styling that preserves identity across multiple characters and objects
- Improved world knowledge for more accurate scene generation
- Supports multiple image references to guide generation
- Generates up to 4 images at a time
Output options:
- Aspect ratios: 21:9, 16:9, 5:4, 4:3, 3:2, 1:1, 2:3, 3:4, 4:5, 9:16
- Resolutions: Up to 4K
Ideal for:
- Rapid creative workflows requiring real-time iteration
- Brand content and storytelling with consistent character identity
- Professional visuals with accurate text and typography
Cost: Varies based on selected settings and number of variations
Krea 2 Medium
A versatile, production-ready image generation model from Krea AI, balancing quality and speed for a wide range of creative workflows.
Features:
- High-fidelity image generation with strong prompt adherence
- Supports multiple image references to guide generation
- Generates up to 4 images at a time
Output options:
- Aspect ratios: 16:9, 4:3, 1:1, 3:4, 9:16
Ideal for:
- Professional content creation requiring consistent quality
- Rapid iteration across diverse creative concepts
Cost: Varies based on selected settings and number of variations
Krea 2 Large
Krea AI’s flagship image generation model, delivering maximum visual fidelity and advanced creative control for professional production workflows.
Features:
- Exceptional detail and realism for professional-grade output
- Advanced style control with support for multiple image references
- Generates up to 4 images at a time
Output options:
- Aspect ratios: 16:9, 4:3, 1:1, 3:4, 9:16
Ideal for:
- High-end commercial and editorial image production
- Complex creative compositions requiring maximum fidelity
Cost: Varies based on selected settings and number of variations
Seedream 5 Lite
A lightweight, fast-generation image model from ByteDance delivering high-quality results with reduced compute requirements.
Features:
- Fast generation for rapid creative iteration
- Supports multiple image references to guide generation
- Generates up to 4 images at a time
Output options:
- Aspect ratios: 16:9, 4:3, 1:1, 3:4, 9:16
Ideal for:
- High-volume image creation workflows requiring speed
- Rapid concept exploration and previews
Cost: Varies based on selected settings and number of variations
Seedream 5 Lite is not available in the United States.
GPT Image 1.5
A high-speed flagship model designed for precise text-based image generation and complex, non-destructive photo editing that preserves original details.
Features:
- Reliably executes requested changes while maintaining the integrity of lighting, composition, and subject appearance within source images
- Supports complex editing tasks including adding, subtracting, combining, and blending elements
- Delivers outputs up to 4x faster than previous iterations
- Generates up to 4 images at a time
Output options:
- Aspect ratios: 3:2, 1:1, 2:3
- Quality options: low, medium, high
Ideal for:
- Practical photo adjustments and realistic virtual try-ons for clothing or hairstyles
- Conceptual transformations and stylistic filters that retain the essence of the input image
- Rapid iteration of text-to-image concepts
Cost: Varies based on selected settings and number of variations
Seedream 4.5
A high-performance multimodal foundation model that unifies text-to-image synthesis, precise image editing, and complex multi-image composition into a single, efficient framework.
Features:
- Native support for fast generation of high-fidelity images up to 4K resolution
- Exceptional preservation of facial features, lighting, color tone, and fine details during editing tasks based on reference inputs
- Accurately identifies and blends target elements across multiple input images for controllable, consistent results
- Offers designer-level composition capabilities with clear, accurate rendering of small text for posters and brand visuals
- Generates up to 4 images at a time
Output options:
- Aspect ratios: 16:9, 4:3, 1:1, 3:4, 9:16
- Resolutions: 2K, 4K
Ideal for:
- Professional graphic design workflows requiring precise layout and typography
- Complex photo editing needing strict adherence to reference identity and lighting
- High-resolution creative compositing using multiple visual sources
Cost: Varies based on selected settings and number of variations
Seedream 4.5 is not available in the United States.
Kling O1 Image
A high-fidelity image generation model with advanced reasoning capabilities, designed for superior prompt adherence and precise visual consistency across complex compositions.
Features:
- Exceptional ability to interpret and execute intricate, multi-layered text descriptions with high accuracy
- Leverages image references to maintain subject identity, lighting, and aesthetic style across generations
- Optimized for realistic textures, complex spatial relationships, and professional-grade lighting effects
- Generates up to 4 images at a time
Output options:
- Aspect ratios: Auto, 16:9, 9:16, 1:1, 4:3, 3:4, 3:2, 2:3, 21:9
- Resolutions: 1K, 2K
Ideal for:
- Professional creative assets requiring strict adherence to detailed and technical text prompts
- High-consistency image editing and character design using visual references
Cost: Varies based on selected settings and number of variations
Kling O1 Image is not available in the United States.
FLUX.2 [Pro]
A production-grade image generation and editing model designed for professional workflows, offering state-of-the-art visual quality with a focus on speed, precision, and consistency.
Features:
- Reference multiple images simultaneously to achieve industry-leading character and identity consistency across hundreds of assets
- Provides an unprecedented leap in detail quality, closing the gap with real photography for everything from fabric textures to architectural elements
- Delivers production-ready text rendering for complex typography, UI mockups, and infographics
- Supports precise brand color specification via hex codes with no approximation
- Ensures accurate object positioning, realistic physics, coherent lighting, and proper perspective throughout complex scenes
- Optimized for better accuracy and responsiveness to structured, complex instructions
- Generates up to 4 images at a time
Output options:
- Aspect Ratios: 16:9, 4:3, 1:1, 3:4, 9:16
- Resolutions: 720p, 1080p, 2K
Ideal for:
- Running character-consistent campaigns and placing products accurately in any context
- Creating interface mockups with readable text and consistent visual design systems
- Generating product photography at scale and contextual lifestyle shots
Cost: Varies based on selected settings and number of variations
Nano Banana Pro
A professional-grade, reasoning-based image generation and editing model designed for high-fidelity asset production, advanced creative control, and precise instruction following.
Inputs:
- Image Reference
- Text Description (supports complex, multi-layered prompts)
Features:
- Plans scenes before rendering to deliver physics-accurate lighting, accurate object relationships, and superior prompt adherence
- Generates sharp, legible multilingual text in various font styles and handwriting for impactful posters and product mockups
- Maintains high fidelity and resemblance for up to 5 people and multiple objects across diverse creative outputs
- Integrates Google Search to enhance visuals with actual data, real-world knowledge, and real-time information like weather or sports
- Adjust camera angles, focal points, and scene lighting (e.g., transforming day to night) with advanced localized editing tools
- Superior spatial understanding enables the generation of accurate infographics, technical diagrams, and presentation slides
- Generates up to 4 variations at a time
Output options:
- Resolutions: 1K, 2K, 4K
- Aspect ratios: Auto, 21:9, 16:9, 5:4, 4:3, 3:2, 1:1, 2:3, 3:4, 4:5, 9:16
Ideal for:
- Professional advertising, brand assets, and high-end e-commerce product photography
- Educational explainers, data-driven infographics, and complex technical documentation
- Rapid prototyping of high-resolution visual designs with consistent character or brand identity
Cost: Varies based on selected settings and number of variations
Nano Banana
A high-speed model for quick, high-quality image generation and editing directly from text prompts.
Features:
- Supports multiple image references to guide generation
- Generates up to 4 images at a time
Output options:
- Aspect ratios: 21:9, 16:9, 5:4, 4:3, 3:2, 1:1, 2:3, 3:4, 4:5, 9:16
Ideal for:
- Rapid image creation and iteration
Cost: Varies based on selected settings and number of variations
Runway Gen-4 Image
An advanced base model designed for high-fidelity image generation, offering unprecedented stylistic control and visual memory to maintain consistency across scenes.
Features:
- Anchor characters, styles, or specific objects using input images to maintain professional-grade consistency across multiple outputs
- Optimized to interpret complex, natural language descriptions for precise control over visual details, lighting, and emotions
- Capable of generating high-quality visuals for diverse use cases, from cinematic storyboards to professional product photography
- Generates up to 4 images at a time
Output options:
- Aspect ratios: 16:9, 4:3, 1:1, 3:4, 9:16
- Resolutions: 720p, 1080p
Ideal for:
- Ensuring protagonists retain their appearance across different environments and lighting treatments
- Rapidly producing high-resolution brand assets, virtual try-ons, and scale-ready product visualizations
- Exploring varied artistic directions while locking in core visual identity via image references
Cost: Varies based on selected settings and number of variations
Runway Gen-4 Image Turbo
An optimized image generation model engineered for speed, delivering results 2.5x faster than the standard Gen-4 Image while maintaining identical output quality.
Features:
- Optimized processing allows for rapid creative exploration, generating high-fidelity images in a fraction of the time
- Upload up to three reference images to guide the model’s understanding of specific characters, environments, and artistic styles
- Solves the challenge of visual drift by encoding specific visual characteristics from reference images to maintain identity across multiple generations
- Effortlessly apply the aesthetic, lighting, and texture of a reference image to entirely new subjects and scenes
- Utilize seed parameters to systematically explore variations or recreate specific outputs with precision
- Generates up to 4 images at a time
Output options:
- Aspect ratios: 16:9, 4:3, 1:1, 3:4, 9:16
- Resolutions: 720p, 1080p
Ideal for:
- Rapidly producing platform-optimized visuals for Instagram Stories (9:16) or standard posts (1:1) at scale
- Maintaining strict visual identity across campaigns by using brand style guides as reference images
- Developing consistent character poses and settings while ensuring the protagonist remains recognizable
- Creating diverse lifestyle and seasonal product shots accurately through reference-based guidance
Cost: Varies based on selected settings and number of variations
Seedream 4
A specialized image model for generating multi-shot sequences or scenes with large movement and action.
Features:
- Excels at creating images with stable physics and coherent transitions
- Supports multiple image references to guide generation
- Generates up to 4 images at a time
Output options:
- Aspect ratios: auto, 16:9, 4:3, 1:1, 3:4, 9:16
Ideal for:
- Action scenes and dynamic compositions
Cost: Varies based on selected settings and number of variations
Seedream 4 is not available in the United States.
FLUX.1 Kontext [Pro]
A professional model for advanced image generation and editing, offering strong scene coherence and style control.
Features:
- Image-based style control requiring a reference image to guide visual aesthetic
- Generates up to 4 images at a time
Output options:
- Aspect ratios: 21:9, 16:9, 4:3, 3:2, 1:1, 2:3, 3:4, 4:5, 9:16, 9:21
Ideal for:
- Professional content with precise style requirements
Cost: Varies based on selected settings and number of variations
Lip-sync models
Creatify Aurora
A state-of-the-art diffusion transformer (DiT) model designed for rendering ultra-realistic, reactive avatars driven by audio and text guidance.
Generation inputs:
- Avatar (Source Image)
- Speech (Audio File)
- Text Description (Guidance)
Features:
- Goes beyond basic lip-sync to include context-aware blinking, breathing, and natural facial expressions
- Automatically synchronizes hand and full-body movements based on vocal tone and inflection for a studio-grade performance
- Accurately interprets vocal intensity and pitch to deliver performance-accurate emotional expressions
- Maintains high character fidelity and behavioral coherence even across extended dialogue or musical performances
- Optimized for various setups, including side-angle presentations, podcast-style dialogues, and stylized animations
- Generate up to 4 variations at a time
Output options:
- Resolutions: 480p, 720p
Ideal for:
- Professional avatar-based video ads and marketing content
- High-fidelity virtual storytelling and expressive musical performances
- Long-form educational or training videos requiring consistent character presence
Cost: Varies based on input, settings and duration
Veed Fabric
A fast, precise image-to-video lip-sync model that animates a still image to match provided audio.
Inputs:
- Source image
- Speech audio file
Features:
- Animates the mouth and facial expressions on the source image to match provided audio
- Creates high-fidelity “talking” video from still images
- Lip-sync specific tool, not a full video generation model
Ideal for:
- Creating talking avatars from still images
- Adding dialogue to character portraits
- Professional avatar-driven content workflows
Cost: Varies based on input, settings and duration
For best results, the image should contain a detectable figure.
HeyGen Avatar 4
HeyGen’s latest avatar model for generating highly realistic, expressive talking-head videos from a single image and audio input.
Inputs:
- Source image
- Speech audio file
Features:
- Animates facial expressions and lip movements to match provided audio with high fidelity
- Produces natural head motion and subtle micro-expressions for lifelike results
- Lip-sync specific tool, not a full video generation model
Ideal for:
- Professional spokesperson and presenter videos
- Creating personalized avatar content at scale
- Marketing and training videos with consistent character presence
Cost: Varies based on input, settings and duration
For best results, the image should contain a clearly visible face.
Sync 3
The latest generation video lip-sync model from Sync, delivering studio-quality synchronization across a wide range of content types.
Generation inputs:
- Source Video
- Speech Audio
Features:
- High-accuracy lip-sync that preserves unique facial details, natural teeth, and skin texture
- Optimized for all content types including live-action, 3D animation, and AI-generated video
- Video-to-video lip-sync tool, not a full video generator
Ideal for:
- Professional dubbing and localization for film and advertising
- Enhancing or correcting dialogue in any video format
- High-volume content translation workflows
Cost: Varies based on input, settings and duration
For best results, the video should contain a detectable figure.
Sync Lipsync 2 Pro
A state-of-the-art video editing model designed for studio-grade lip-syncing that preserves unique facial details while scaling to high-resolution outputs.
Generation inputs:
- Source Video
- Speech Audio
Features:
- Incorporates advanced upscaling to support 4K output while maintaining sharp, natural textures
- Protects unique facial features such as natural teeth, freckles, makeup, and complex facial hair without loss of clarity
- Optimized to work across all content types, including live-action, 3D animation, and AI-generated video
- Delivers expressive, synchronized results immediately without requiring speaker-specific training or model fine-tuning
- Generate up to 4 variations simultaneously
Ideal for:
- Professional-grade dubbing and localized content for film and high-end advertising
- Enhancing or correcting dialogue in 3D animated and AI-generated characters
- High-resolution projects requiring pixel-perfect facial consistency and detail
Cost: Varies based on input, settings and duration
OmniHuman 1.5
A dedicated utility model for generating exceptionally realistic, humanlike lip-sync.
Inputs:
- Static source image
- Speech audio file
Features:
- Animates the mouth on the source image to match provided audio
- Creates high-fidelity “talking” video from still images
- Lip-sync specific tool, not a full video generation model
Ideal for:
- Creating talking avatars
- Adding dialogue to still images
- Professional dubbing workflows
Cost: Varies based on input, settings and duration
For best results, the image should contain a detectable figure.
OmniHuman 1.5 is not available in the United States.
Veed Lipsync
A fast, affordable, and precise utility model for applying realistic lip-sync to videos.
Inputs:
- Source video
- New speech audio file
Features:
- Re-animates mouth movements in source video to match new audio
- Video-to-video lip-sync tool, not a full video generator
Ideal for:
- High-volume, cost-effective dubbing
- Translating content
- Correcting audio in video clips with realistic results
Cost: Varies based on input, settings and duration
For best results, the video should contain a detectable figure.
Upscaling model
Topaz Upscale
A dedicated utility model for image and video upscaling, designed to enhance resolution and detail up to 4x.
Features:
- Enhancement tool that processes existing media
- Increases media size while preserving natural textures and minimizing artifacts
- Highly granular upscale factors: 1x, 1.25x, 1.5x, 1.75x, 2x, 3x, 4x
- Video-specific: Flexible frame rate control (keep source or convert to 24, 25, 30, 48, 50, or 60 fps)
Ideal for:
- Improving quality of generated media
- Restoring legacy footage or photos
- Preparing assets for high-resolution displays
Cost: Varies depending on input