Integrate your own model
Connect an agent to your own LLM or host your own server.
Custom LLM allows you to connect your conversations to your own LLM via an external endpoint. ElevenLabs also supports natively integrated LLMs
Custom LLMs let you bring your own OpenAI API key or run an entirely custom LLM server.
By default, we use our own internal credentials for popular models like OpenAI. To use a custom LLM server, it must align with one of the following OpenAI-compatible request/response structures:
/v1/chat/completions)/v1/responses)The Responses API is OpenAI’s newer API format that supports additional features. Both API formats are fully supported for custom LLM integration.
The following guides cover both use cases:
You’ll learn how to:
To integrate a custom OpenAI key, update your agent settings in the ElevenLabs dashboard to point to your custom LLM server and create a secret containing your OPENAI_API_KEY:
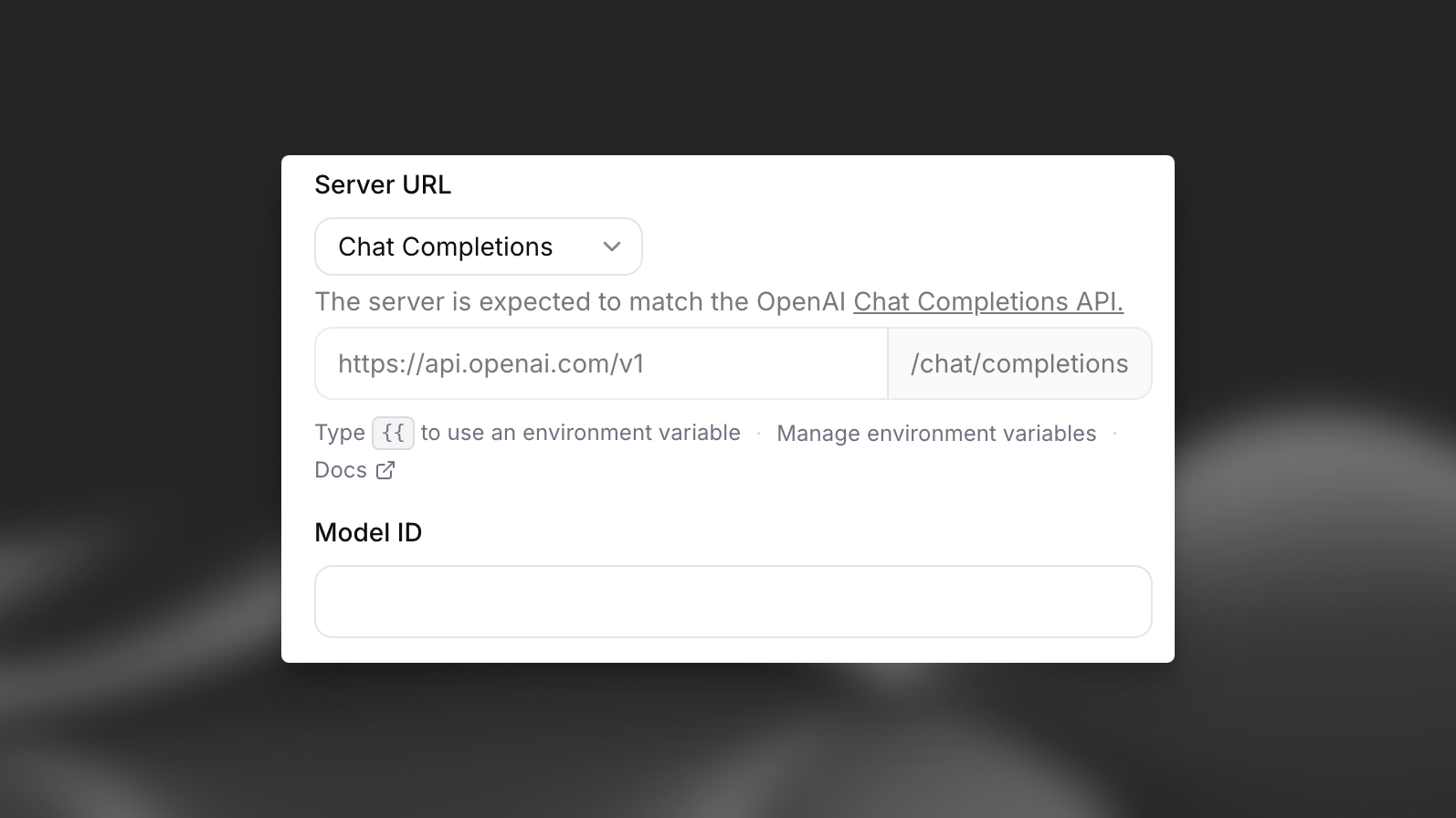
In your Agent settings in the ElevenLabs dashboard, select “Custom LLM” from the “LLM” dropdown menu on the right.
To bring a custom LLM server, set up a compatible server endpoint using OpenAI’s style. You can implement either the Chat Completions API (/v1/chat/completions) or the Responses API (/v1/responses).
Both endpoints must return responses in SSE (Server-Sent Events) format with Content-Type: text/event-stream.
The Chat Completions API uses the /v1/chat/completions endpoint.
Each chunk must be formatted as data: {json}\n\n and the stream must end with data: [DONE]\n\n.
Here’s an example server implementation:
Run this code or your own server code.
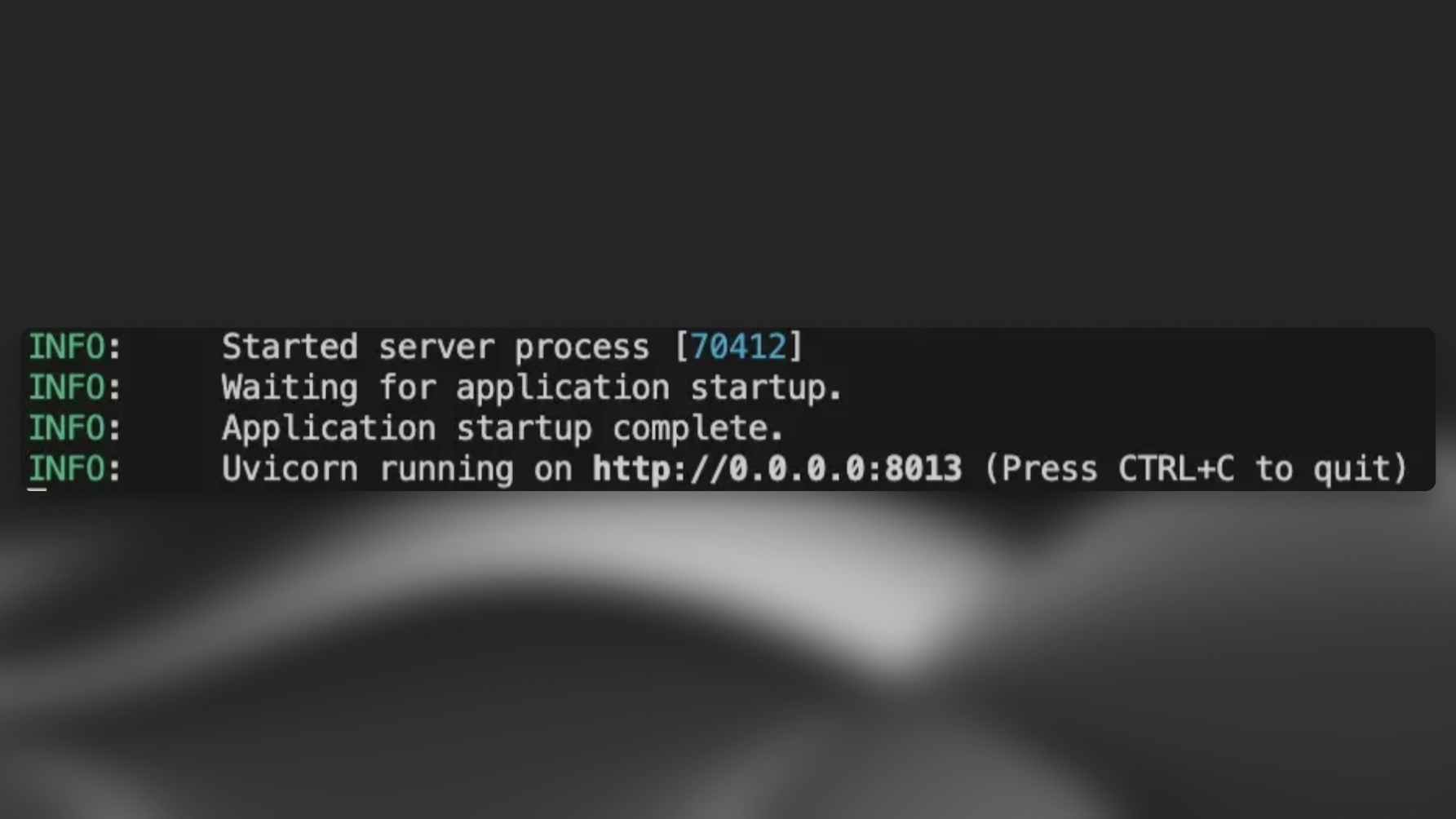
To make your server accessible, create a public URL using a tunneling tool like ngrok:
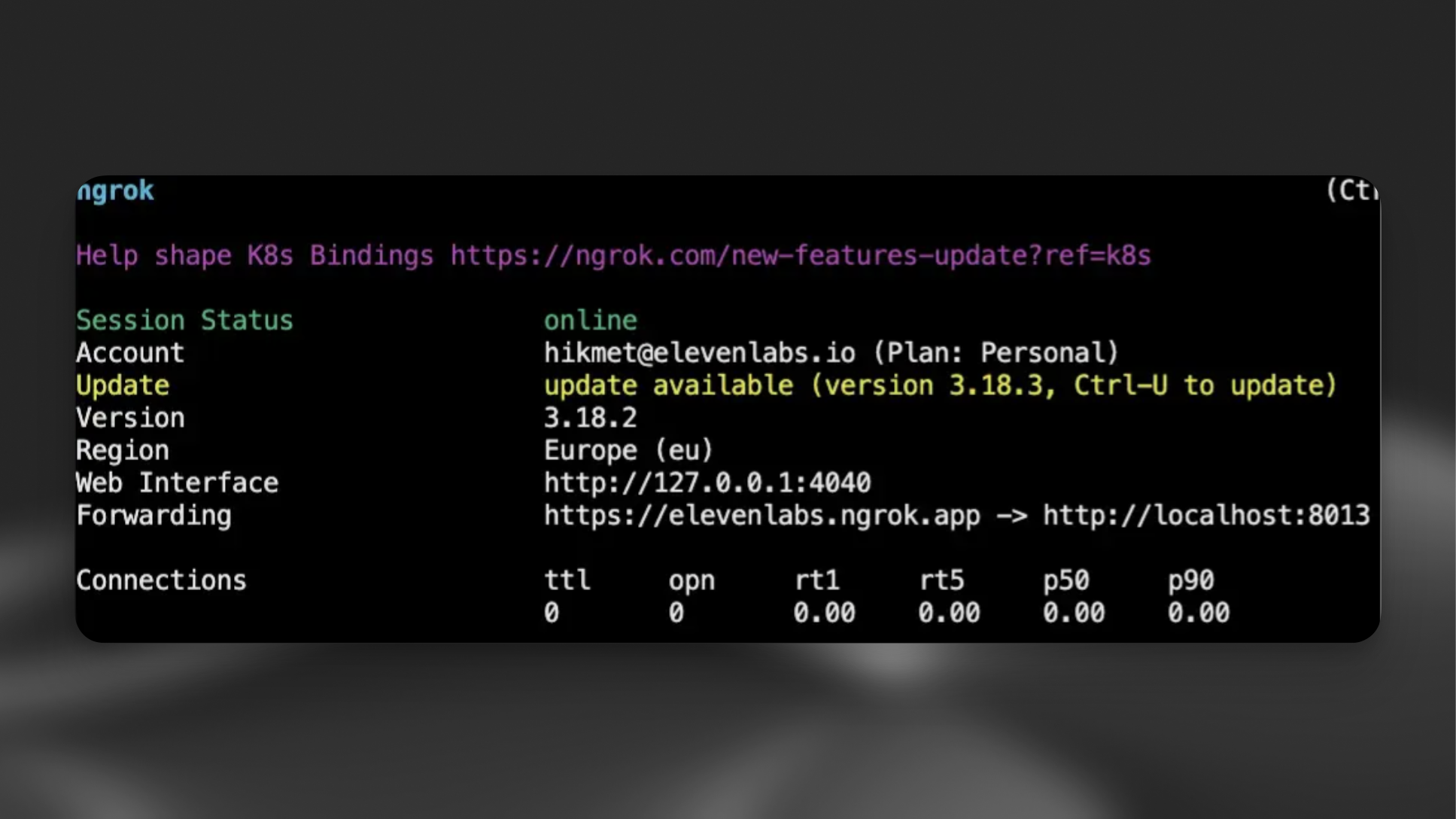
Next, update your agent settings in the ElevenLabs dashboard to point to your custom LLM server.
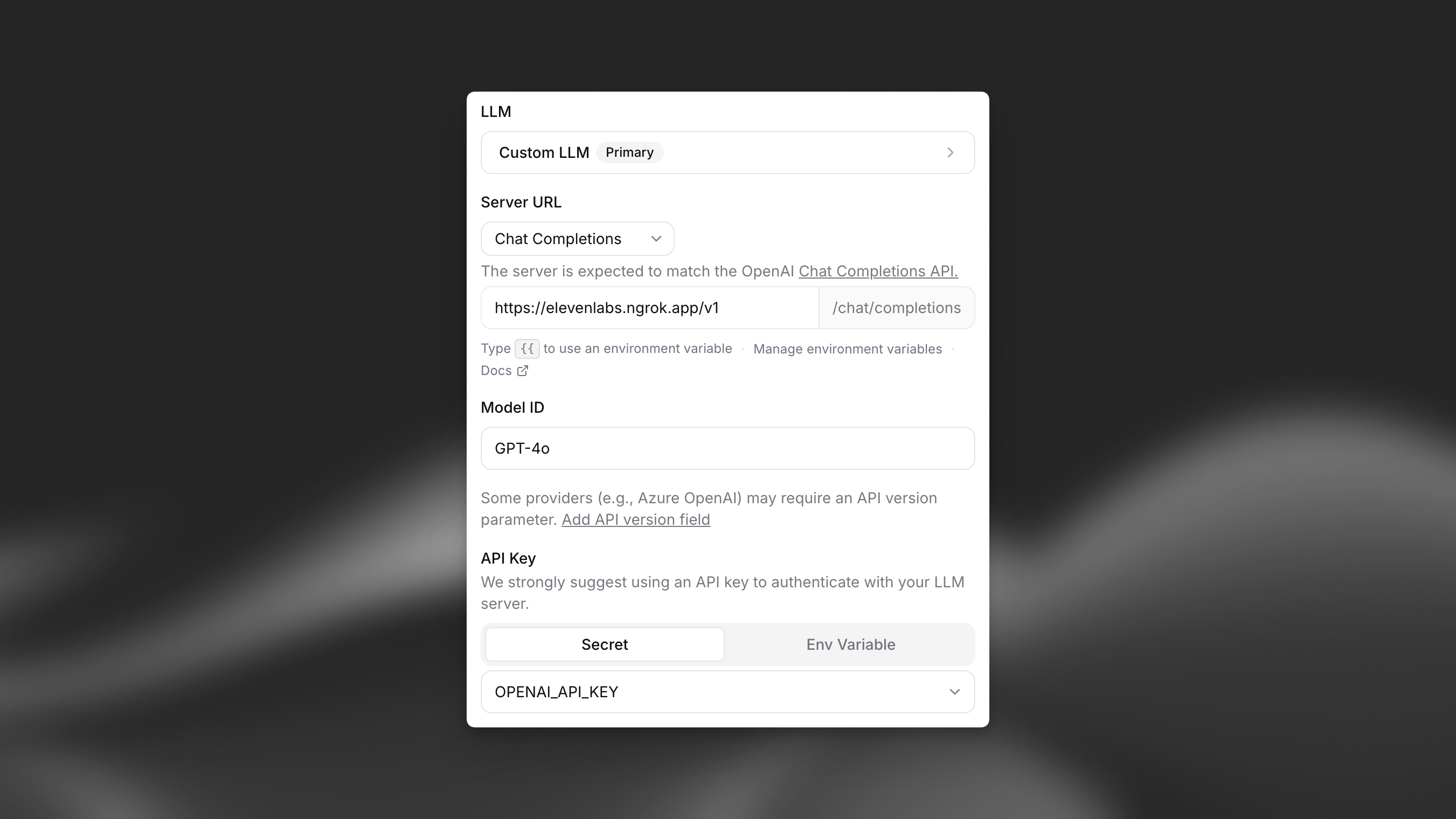
Direct your server URL to ngrok endpoint and set “Limit token usage” to 5000.
You can now start interacting with your agent with your own LLM server.
If your custom LLM has slow processing times (perhaps due to agentic reasoning or pre-processing requirements) you can improve the conversational flow by implementing buffer words in your streaming responses. This technique helps maintain natural speech prosody while your LLM generates the complete response.
When your LLM needs more time to process the full response, return an initial response ending with "... " (ellipsis followed by a space). This allows the Text to Speech system to maintain natural flow while keeping the conversation feeling dynamic.
This creates natural pauses that flow well into subsequent content that the LLM can reason longer about. The extra space is crucial to ensure that the subsequent content is not appended to the ”…” which can lead to audio distortions.
Here’s how to modify your custom LLM server to implement buffer words:
Your custom LLM can trigger system tools to control conversation flow and state. These tools are automatically included in the tools parameter of your chat completion requests when configured in your agent.
For more information on system tools, please see our guide
Purpose: Automatically terminate conversations when appropriate conditions are met.
Trigger conditions: The LLM should call this tool when:
Parameters:
reason (string, required): The reason for ending the callmessage (string, optional): A farewell message to send to the user before ending the callFunction call format:
Implementation: Configure as a system tool in your agent settings. The LLM will receive detailed instructions about when to call this function.
Learn more: End call tool
Purpose: Automatically switch to the user’s detected language during conversations.
Trigger conditions: The LLM should call this tool when:
Parameters:
reason (string, required): The reason for the language switchlanguage (string, required): The language code to switch to (must be in supported languages list)Function call format:
Implementation: Configure supported languages in agent settings and add the language detection system tool. The agent will automatically switch voice and responses to match detected languages.
Learn more: Language detection tool
Purpose: Transfer conversations between specialized AI agents based on user needs.
Trigger conditions: The LLM should call this tool when:
Parameters:
reason (string, optional): The reason for the agent transferagent_number (integer, required): Zero-indexed number of the agent to transfer to (based on configured transfer rules)Function call format:
Implementation: Define transfer rules mapping conditions to specific agent IDs. Configure which agents the current agent can transfer to. Agents are referenced by zero-indexed numbers in the transfer configuration.
Learn more: Agent transfer tool
Purpose: Seamlessly hand off conversations to human operators when AI assistance is insufficient.
Trigger conditions: The LLM should call this tool when:
Parameters:
reason (string, optional): The reason for the transfertransfer_number (string, required): The phone number to transfer to (must match configured numbers)client_message (string, required): Message read to the client while waiting for transferagent_message (string, required): Message for the human operator receiving the callFunction call format:
Implementation: Configure transfer phone numbers and conditions. Define messages for both customer and receiving human operator. Works with both Twilio and SIP trunking.
Learn more: Transfer to human tool
Purpose: Allow the agent to pause and wait for user input without speaking.
Trigger conditions: The LLM should call this tool when:
Parameters:
reason (string, optional): Free-form reason explaining why the pause is neededFunction call format:
Implementation: No additional configuration needed. The tool simply signals the agent to remain silent until the user speaks again.
Learn more: Skip turn tool
Parameters:
reason (string, required): The reason for detecting voicemail (e.g., “automated greeting detected”, “no human response”)Function call format:
Learn more: Voicemail detection tool
When system tools are configured, your custom LLM will receive requests that include the tools in the standard OpenAI format:
Your custom LLM must support function calling to use system tools. Ensure your model can generate proper function call responses in OpenAI format.
You may pass additional parameters to your custom LLM implementation.