For AI agents: a documentation index is available at the root level at /llms.txt. Append /llms.txt to any URL for a page-level index, or .md for the markdown version of any page.
Learn how to clone your voice professionally using our best-in-class models.
Creating a Professional Voice Clone
When cloning a voice, it’s important to consider what the AI has been trained on: which languages and what type of dataset. Read more about each individual model and their strengths on the Models page.
Guide
If you are unsure about what is permissible from a legal standpoint, please consult the Terms of
Service and our AI Safety
information for more information.
Professional Voice Clones do not currently support singing. Audio recordings must consist of
spoken voice only.
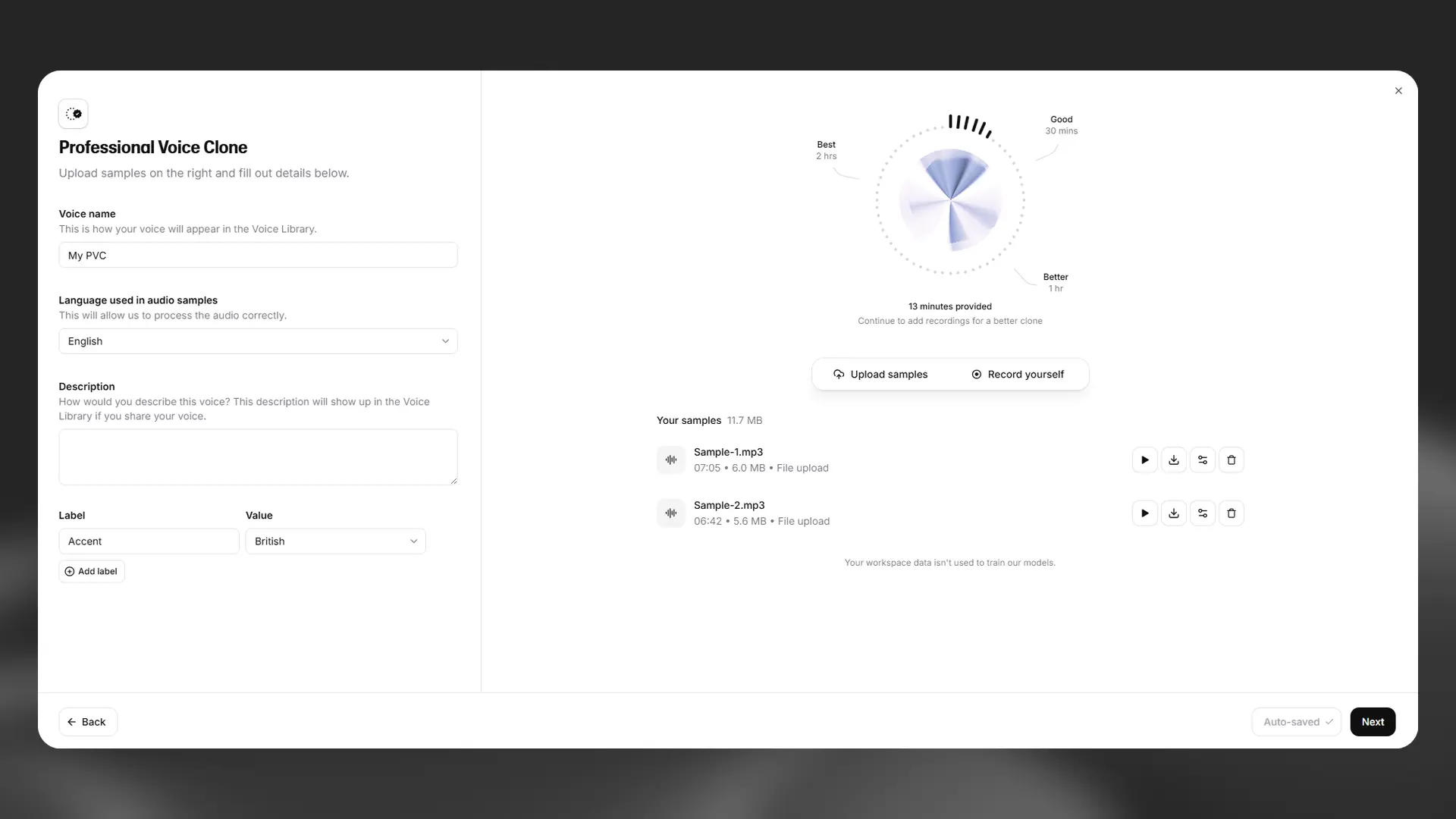
Upload your audio samples by clicking Upload samples.
If you don’t already have pre-recorded training audio, you can also record directly into the interface by selecting Record yourself. We’ve included sample scripts for narrative, conversational and advertising purposes. You can also upload your own script.
Once your audio has been uploaded, you will see feedback on the length of your samples. For the best results, we recommend uploading at least an hour of training audio, and ideally as close to three hours as possible.
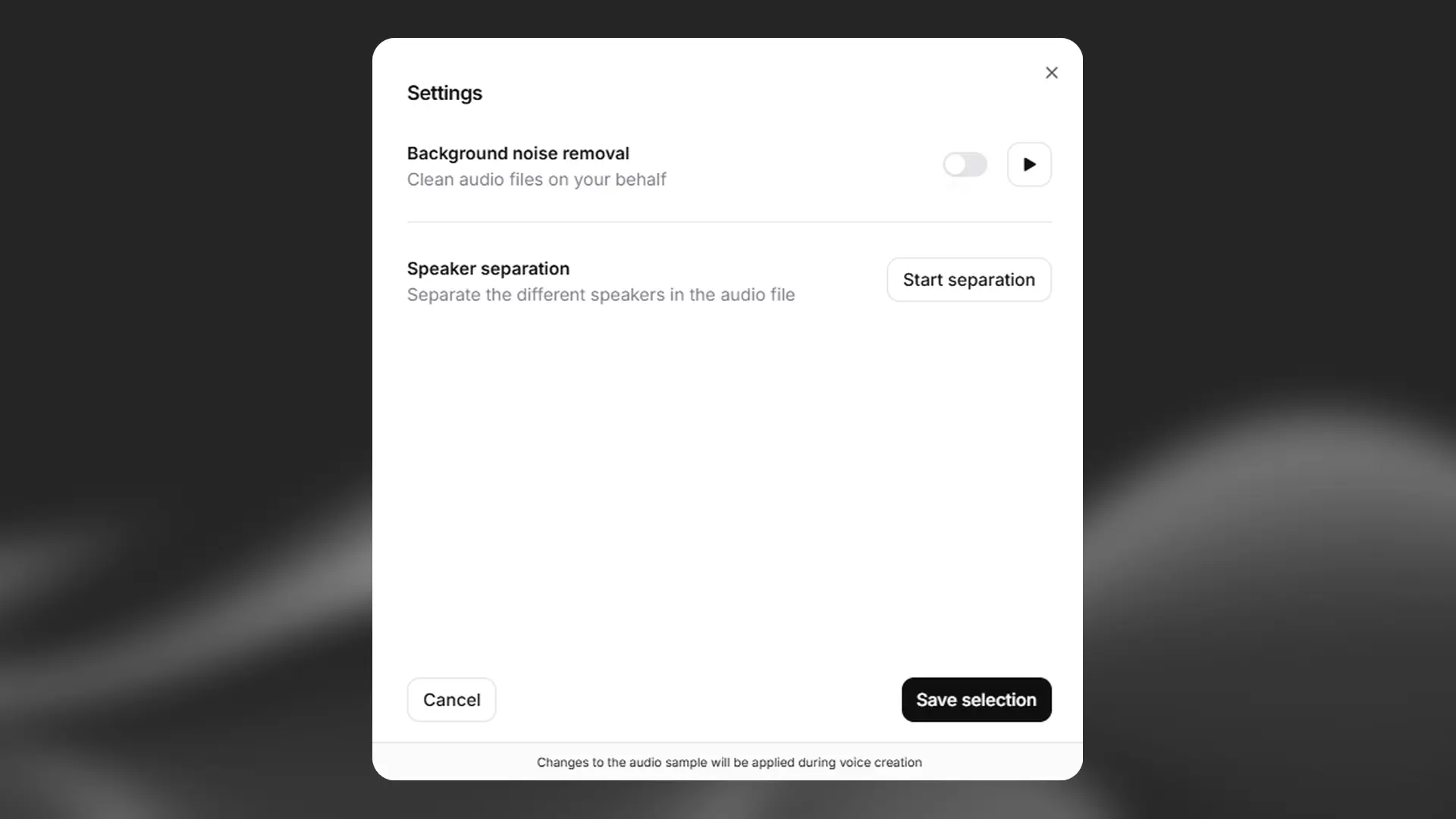
Once your audio samples have been uploaded, you can process them to improve the quality. You can remove any background noise, and you can also separate out different speakers, if your audio includes more than one speaker. To access these options, click the Audio settings button next to the clip you want to process.
Once everything is recorded and uploaded, you will be asked to verify your voice. To ensure a smooth experience, please try to verify your voice using the same or similar equipment used to record the samples and in a tone and delivery that is similar to those present in the samples. If you do not have access to the same equipment, try verifying the best you can. If it fails, you can either wait 24 hours to try verification again, or reach out to support for help.
Before you can use your voice, it needs to complete the fine tuning process. You can check the status of your voice in My Voices while it’s processing. You’ll be notified when it’s ready to use.
Under the Voices section in the dashboard, select the Personal tab, then click Use next to your voice clone to begin using it.
There are a few things to be mindful of before you start uploading your samples, and some steps that you need to take to ensure the best possible results.
Professional Voice Cloning is highly accurate in cloning the samples used for its training. It will create a near-perfect clone of what it hears, including all the intricacies and characteristics of that voice, but also including any artifacts and unwanted audio present in the samples. This means that if you upload low-quality samples with background noise, room reverb/echo, or any other type of unwanted sounds like music or multiple people speaking, the AI will try to replicate all of these elements in the clone as well.
Make sure there’s only a single speaking voice throughout the audio, as more than one speaker or excessive noise or anything of the above can confuse the AI. This confusion can result in the AI being unable to discern which voice to clone or misinterpreting what the voice actually sounds like because it is being masked by other sounds, leading to a less-than-optimal clone.
Make sure you have enough material to clone the voice properly. The bare minimum we recommend is 30 minutes of audio, but for the optimal result and the most accurate clone, we recommend closer to 2-3 hours of audio. The more audio provided the better the quality of the resulting clone.
The speaking style in the samples you provide will be replicated in the output, so depending on what delivery you are looking for, the training data should correspond to that style (e.g. if you are looking to voice an audiobook with a clone of your voice, the audio you submit for training should be a recording of you reading a book in the tone of voice you want to use). It is better to just include one style in the uploaded samples for consistencies sake.
Use samples speaking the language you want the PVC to be used for
It is best to use samples speaking where you are speaking the language that the PVC will mainly be used for. Of course, the AI can speak any language that we currently support. However, it is worth noting that if the voice itself is not native to the language you want the AI to speak - meaning you cloned a voice speaking a different language - it might have an accent from the original language and might mispronounce words and inflections. For instance, if you clone a voice speaking English and then want it to speak Spanish, it will very likely have an English accent when speaking Spanish. We only support cloning samples recorded in one of our supported languages, and the application will reject your sample if it is recorded in an unsupported language.
See the examples below for what to expect from a good and bad recording.
For now, we only allow you to clone your own voice. You will be asked to go through a verification process before submitting your fine-tuning request.
Tips and suggestions
Professional Recording Equipment
Professional Recording Equipment
Use high-quality recording equipment for optimal results as the AI will clone everything about the audio. High-quality input = high-quality output. Any microphone will work, but an XLR mic going into a dedicated audio interface would be our recommendation. A few general recommendations on low-end would be something like an Audio Technica AT2020 or a Rode NT1 going into a Focusrite interface or similar.
Use a Pop-Filter
Use a Pop-Filter
Use a Pop-Filter when recording. This will minimize plosives when recording.
Microphone Distance
Microphone Distance
Position yourself at the right distance from the microphone - approximately two fists away from the mic is recommended, but it also depends on what type of recording you want.
Noise-Free Recording
Noise-Free Recording
Ensure that the audio input doesn’t have any interference, like background music or noise. The AI cloning works best with clean, uncluttered audio.
Room Acoustics
Room Acoustics
Preferably, record in an acoustically-treated room. This reduces unwanted echoes and background noises, leading to clearer audio input for the AI. You can make something temporary using a thick duvet or quilt to dampen the recording space.
Audio Pre-processing
Audio Pre-processing
Consider editing your audio beforehand if you’re aiming for a specific sound you want the AI to output. For instance, if you want a polished podcast-like output, pre-process your audio to match that quality, or if you have long pauses or many “uhm”s and “ahm”s between words as the AI will mimic those as well.
Volume Control
Volume Control
Maintain a consistent volume that’s loud enough to be clear but not so loud that it causes distortion. The goal is to achieve a balanced and steady audio level. The ideal would be between -23dB and -18dB RMS with a true peak of -3dB.
Sufficient Audio Length
Sufficient Audio Length
Provide at least 30 minutes of high-quality audio that follows the above guidelines for best results - preferably closer to 2+ hours of audio. The more quality data you can feed into the AI, the better the voice clone will be. The number of samples is irrelevant; the total runtime is what matters. However, if you plan to upload multiple hours of audio, it is better to split it into multiple ~30-minute samples. This makes it easier to upload.
FAQ
What is the difference between Instant Voice Cloning (IVC) and Professional Voice Cloning (PVC)?
Professional Voice Cloning (PVC), unlike Instant Voice Cloning (IVC) which lets you quickly clone voices with less than 2 minutes of audio, allows you to train a more realistic model of your voice. This is achieved by training a dedicated model on a large set of voice data to produce a model that’s virtually indistinguishable from your original voice.
Since Professional Voice Clones require fine-tuning and training, it will take some time before you can use your voice clone. Giving an estimate is challenging as it depends on the number of people in the queue before you and a few other factors, but usually fine-tuning will take 3-6 hours.
You will receive an email notification once your Professional Voice Clone is ready.
Can I create a Professional Voice Clone of someone else's voice?
No. You can only create a Professional Voice Clone of your own voice. Even with their consent, you cannot clone someone else’s voice. All Professional Voice Clones require a verification process to confirm that the voice belongs to you.
If someone wants to share their voice with you, they can create and verify a Professional Voice Clone on their own account, then share it with you privately using a sharing link. Learn more in our article: How do I share a voice?
How many Professional Voice Clones (PVCs) can I have?
Professional Voice Clone (PVC) slots vary by subscription tier:
Base PVC Slots
Free and Starter plan: No PVC slots available
Creator, Pro, and legacy Scale plan: 1 PVC slot
Scale and legacy Business plan: 3 PVC slots
Business plan: 10 PVC slots
Enterprise plan: Custom number of PVC slots
Additional PVC Slots
You can earn additional PVC slots through our quality review process:
If your existing PVC gets marked as Studio Quality through our manual review process, you’ll automatically receive an additional PVC slot
This can happen multiple times if multiple voices get marked as Studio Quality
You cannot submit more PVC voices unless you either:
1Get extra slots through the Studio Quality review process
Professional Voice Clones can only be used to clone your own voice
If you downgrade below the Creator tier, your PVC will stay in your library but you won’t be able to use it until you upgrade to Creator or above
The total number of custom voices you can have (including PVCs) depends on your subscription tier
How do I add or upgrade the models used to train my Professional Voice Clone?
All Professional Voice Clones (PVCs) will automatically train on the Flash v2.5, Turbo v2.5 and Multilingual v2 models. PVCs trained on English audio will also automatically train on the Flash v2 and Turbo v2 models.
If you have an existing PVC, you now have the option to fine-tune on additional models. In the future, if new models are released that support fine-tuning, you will receive a notification. This is shown by an exclamation icon, which will appear to the right of your voice in the voice list in My Voices. Hovering over this icon will display the notification.
To start the fine-tuning process, hover over the name of your voice in the list in My Voices, and you will see all available models. Models that the voice has already been fine-tuned on will be displayed with a tick icon, and models that are available for fine-tuning will be displayed with a plus icon. To begin fine tuning, just click on the model.
While the voice is fine-tuning, you can hover over the model name to see the progress. Please note that due to voice caching, you may need to refresh the page to see the latest progress. Once the fine-training has been completed, you will be notified both in-app and by email.
What does the status of my Professional Voice Clone mean?
Your Professional Voice Clone will go through a few different stages while it is processing. These stages are reflected in the status shown for your Professional Voice Clone in My Voices.
To view the current status, find your voice in the list and look at the icons displayed to the right.
Draft: This status means that your voice is incomplete. Generally this is either
because you haven’t completed creating the voice, or you haven’t verified the voice yet.
To go through the verification process, click the tick icon.
To go back to the voice creation process, click More actions (three dots) and select Edit voice.
Once you’ve verified your voice, it will need to fine-tune on our models before you can use it. You can track this process by hovering over the name of your voice in My Voices. You’ll see all available models listed here, with an icon to indicate the status for each model.
Hover over the name of the model for more information, and you will see one of the following:
The training run has been scheduled: This means that your voice is waiting for a
slot to open up so it can be trained. The length of time that your voice will be queued will depend
on how many other voices are also in the queue.
Creating dataset and Running fine-tuning: Once a slot opens up, it
will begin the fine-tuning process. This can take between 6-24 hours. You’ll see how far through
each step in the training process your voice is, indicated by a percentage.
We are sorry the training run experienced issues and has been retried. No further action is
required
: This means that something went wrong. but your voice has been automatically queued to retry the
fine-tuning process. Your voice should successfully complete the fine-tuning process on the next
try, but if you experience multiple failures, please contact
Support.
Voice is ready to be used with the model: This means that the fine-tuning process
for this model has been completed, and you can now use your voice with this model.
Click to start fine-tuning: Some models do not train automatically, and you will
need to click the model name to begin fine-training. If additional models have become available for
your voice to fine-tune on, you’ll see an exclamation icon next to your voice.
To begin the fine-tuning process, just hover over your voice’s name and click the name of the model.
When will my professional voice clone (PVC) be ready?
Professional Voice Cloning involves training (fine-tuning) the model on large sets of a particular speaker’s voice to create a custom model.
Once you’ve uploaded your samples and verified your voice, your Professional Voice Clone will be added to the queue. The estimated training time is roughly 2-6 hours. This is dependent on a few factors, so it is hard to give an exact estimate. Unfortunately, it can sometimes take longer.
When your PVC has completed the fine-tuning process, you will receive notifications in-app and by email letting you know that your voice is now ready for use.
My professional voice clone failed or is delayed, what can I do?
After you’ve verified your voice, it will need to fine-tune on our models before you will be able to use it. While this is happening, you can check the status of your voice in My Voices by hovering over the name of your voice. This will show you all the available models for your voice. To check the status for each model, hover over the model’s name.
If something went wrong, then you may see the following status:
We are sorry the training run experienced issues and has been retried. No further action is required. This means that something went wrong. but your voice has been automatically queued to
retry the fine-tuning process. Your voice should successfully complete the fine-tuning process on
the next try, but if you experience multiple failures, this might be an issue with the dataset that
the AI cannot resolve.
You can try to resolve this by deleting the voice and uploading the data again, starting from the beginning. This has been shown to help some users.
If this doesn’t resolve the issue, you may need to review your training audio and potentially use different training audio.
You can always contact Support if you’re experiencing failures during the fine-tuning process.
What can I do if I failed to verify my Professional Voice Clone (PVC)?
If you fail all your verification attempts during the creation of your professional voice clone, you can wait 24 hours, after which time you will be able to retry the process.
You can also reach out to support so they can look into it for you. If everything looks correct, they will remove the failed verification attempts so you can retry the process from the start.
Here are some recommendations to help you successfully verify your Professional Voice Clone:
Make sure that your web browser is allowed to use your microphone and that you are not muted.
Ensure that the recorded audio from your computer microphone sounds similar to the audio uploaded for cloning, without any background noise or other external audio interference.
Try to speak in a similar style to the audio you used to train the voice.
Read each verification line only once, then press Stop to stop recording. Reading the line more than once can cause the verification process to fail.
How can I delete my unverified Professional Voice Clone (PVC)?
Unfortunately, this is not possible. As mentioned during the setup process of your Professional Voice Clone (PVC), once you advance to the verification stage, you are locked in until you’ve verified your voice.
If you need help with your Professional Voice Clone, please reach out to support here.
What languages are supported with Professional Voice Cloning (PVC)?
We support Professional Voice Cloning for all languages supported by the Flash v2.5 and Turbo v2.5 model.
Currently, these are the languages we support with professional voice cloning:
🇺🇸 English (USA)
🇬🇧 English (UK)
🇦🇺 English (Australia)
🇨🇦 English (Canada)
🇯🇵 Japanese
🇨🇳 Chinese
🇩🇪 German
🇮🇳 Hindi
🇫🇷 French (France)
🇨🇦 French (Canada)
🇰🇷 Korean
🇧🇷 Portuguese (Brazil)
🇵🇹 Portuguese (Portugal)
🇮🇹 Italian
🇪🇸 Spanish (Spain)
🇲🇽 Spanish (Mexico)
🇮🇩 Indonesian
🇳🇱 Dutch
🇹🇷 Turkish
🇵🇭 Filipino
🇵🇱 Polish
🇸🇪 Swedish
🇧🇬 Bulgarian
🇷🇴 Romanian
🇸🇦 Arabic (Saudi Arabia)
🇦🇪 Arabic (UAE)
🇨🇿 Czech
🇬🇷 Greek
🇫🇮 Finnish
🇭🇷 Croatian
🇲🇾 Malay
🇸🇰 Slovak
🇩🇰 Danish
🇮🇳 Tamil
🇺🇦 Ukrainian
🇷🇺 Russian
🇭🇺 Hungarian
🇳🇴 Norwegian
🇻🇳 Vietnamese
What files do you accept for voice cloning?
Recommended:
MP3 192kbps+
Length:
1-2 minutes of good audio for Instant Voice Cloning
30min - 180min of good audio for Professional Voice Cloning
For both Instant Voice Cloning and Professional Voice Cloning, we accept a plethora of file types, but we strongly recommend using MP3 with a bitrate of 192kbps or above. Using an uncompressed format such as WAV will yield little to no improvement. It is instead recommended to focus on the quality of the actual recording to ensure it is recorded professionally without any background noise, room reverb, multiple speakers, at a consistent volume with a consistent tone, no extremely long gaps of silence, and so on.
Are there any restrictions on what voices I can upload for voice cloning?
At Eleven, we’re fully committed both to respecting intellectual property rights and to implementing safeguards against the potential misuse of our technology:
We only partner with clients who adhere to our Terms of Service and Prohibited Use Policy which prohibit malicious use of our technology towards any purpose which can be deemed illegal or harmful;
We seek to support voice owners and their licensors in claiming their rights and all known infringements will be reviewed and actioned;
All audio generated by our models can be instantly traced back to the user responsible for the generation.
The technology we’re developing is new and clear regulation is yet to be introduced. Part of our goal as an AI research lab is to spread awareness about the existence of this technology, its potential, as well as its limitations.
Are there any tips to get good-quality cloned voices?
The bottom line is: good consistent input = good consistent output.
Length
Instant Voice Cloning: 1 - 2 minutes of good audio
Professional Voice Cloning: 30 - 180 minutes of good audio
Use the best and clearest audio clips that you can find. There should only be one speaker without background noise of interference and their voice should be loud and clear.
Instead of using many clips of different quality just to increase the length, prioritize clips where the microphone quality is obviously very high and where the quality and tone is consistent throughout, rather than focusing on increasing the total runtime.
Ensure that most of the dialogue in your clips aligns with the speaker’s speaking style and intonation that you prefer the most. You don’t want too many chunks of dialogue where the speaker deviates from the desired speech patterns you want to hear.
If necessary, use a noise remover to reduce any background noise.
You can find more information in our documentation here.
Can I clone my voice in a language other than English?
Yes, you can clone your voice speaking any language that is supported by the Flash v2.5 and Turbo v2.5 model. You can find the full list of languages here.
You can even clone a voice speaking a language that the AI is not compatible with, but the results might be very unpredictable, as the AI has never heard that language before. However, it will try its best to clone the voice tonality of the speaker, but it will not be able to speak that language. We would not recommend doing this.
Can I export my voice clones?
No, you cannot export your voice clones, and they are only usable on ElevenLabs and not anywhere else.
If you want to save the voice clone to be able to clone it again later, you will have to save the samples that you used to create the cloned voice. Please be aware that each clone will be slightly different, even if the same audio is used.
Why does my voice or accent not sound correct after cloning?
Currently, we offer two choices for cloning:
Instant Voice Cloning (IVC): IVC is less resource-intensive and provides instant
results that you can use immediately. This method is swift, requiring only about 1 to 3 minutes
of audio input for a high-quality clone, and is often ideal for most general uses but might have
trouble with unique voices or accents.
Professional Voice Cloning (PVC): PVC demands significantly more resources and
you are required to provide the AI with a substantial amount of data (between a minimum of 30
minutes and closer to 3 hours for optimal results). This process involves fine-tuning the model
using the provided dataset to create a customized model. The estimated training time is roughly
2-6 hours, but the process may take longer depending on how many other voices are queued for
fine-tuning.
If you have a rather unique voice with a less common accent, instant voice cloning might not provide a perfect replication of your voice. Then the only way to achieve something like that might be through professional voice cloning. Instant voice cloning is generally very accurate, but under certain circumstances, such as those mentioned above, you might have to resort to professional voice cloning to obtain the most perfect clone.
Unfortunately, there is no way to influence the accent or tone of the clone after the clone has already been created; the only way to influence it is to change the actual samples you use for cloning. Just small changes to the samples can make a big difference.
What does the error 'No model found for this voice. Please select another voice' mean?
You will see this error if you try to use your Professional Voice Clone (PVC) before it has completed the fine-tuning process and is available for use.
When you create a PVC, it needs to go through a number of processes before it becomes available for use. After you have verified your voice, it will be processed and queued for fine-tuning. Depending on how many other voices are currently queued for fine-tuning, we estimate that this process will usually take between 3-6, but it can take up to 24 hours.
You can check the progress of your PVC in My Voices by finding the voice in your list of voices, then clicking View to see more details. You can hover over each model to see the current status.