Streaming text to speech
This guide covers three approaches: generating speech as a file, streaming the audio response directly, and optionally uploading generated audio to an AWS S3 bucket to share via a signed URL.
This guide assumes you have set up your API key and SDK. Complete the quickstart first if you haven’t. The optional S3 upload section also requires an AWS account with access to S3.
Curious why streaming works the way it does? Understanding audio streaming explains the protocol, buffering, and latency tradeoffs in depth.
Convert text to speech (file)
To convert text to speech and save it as a file, we’ll use the convert method of the ElevenLabs SDK and then it locally as a .mp3 file.
You can then run this function with:
Convert text to speech (streaming)
If you prefer to stream the audio directly without saving it to a file, you can use our streaming feature.
You can then run this function with:
Bonus - Uploading to AWS S3 and getting a secure sharing link
Once your audio data is created as either a file or a stream you might want to share this with your users. One way to do this is to upload it to an AWS S3 bucket and generate a secure sharing link.
Creating your AWS credentials
To upload the data to S3 you’ll need to add your AWS access key ID, secret access key and AWS region name to your .env file. Follow these steps to find the credentials:
- Log in to your AWS Management Console: Navigate to the AWS home page and sign in with your account.
- Access the IAM (Identity and Access Management) Dashboard: You can find IAM under “Security, Identity, & Compliance” on the services menu. The IAM dashboard manages access to your AWS services securely.
- Create a New User (if necessary): On the IAM dashboard, select “Users” and then “Add user”. Enter a user name.
- Set the permissions: attach policies directly to the user according to the access level you wish to grant. For S3 uploads, you can use the AmazonS3FullAccess policy. However, it’s best practice to grant least privilege, or the minimal permissions necessary to perform a task. You might want to create a custom policy that specifically allows only the necessary actions on your S3 bucket.
- Review and create the user: Review your settings and create the user. Upon creation, you’ll be presented with an access key ID and a secret access key. Be sure to download and securely save these credentials; the secret access key cannot be retrieved again after this step.
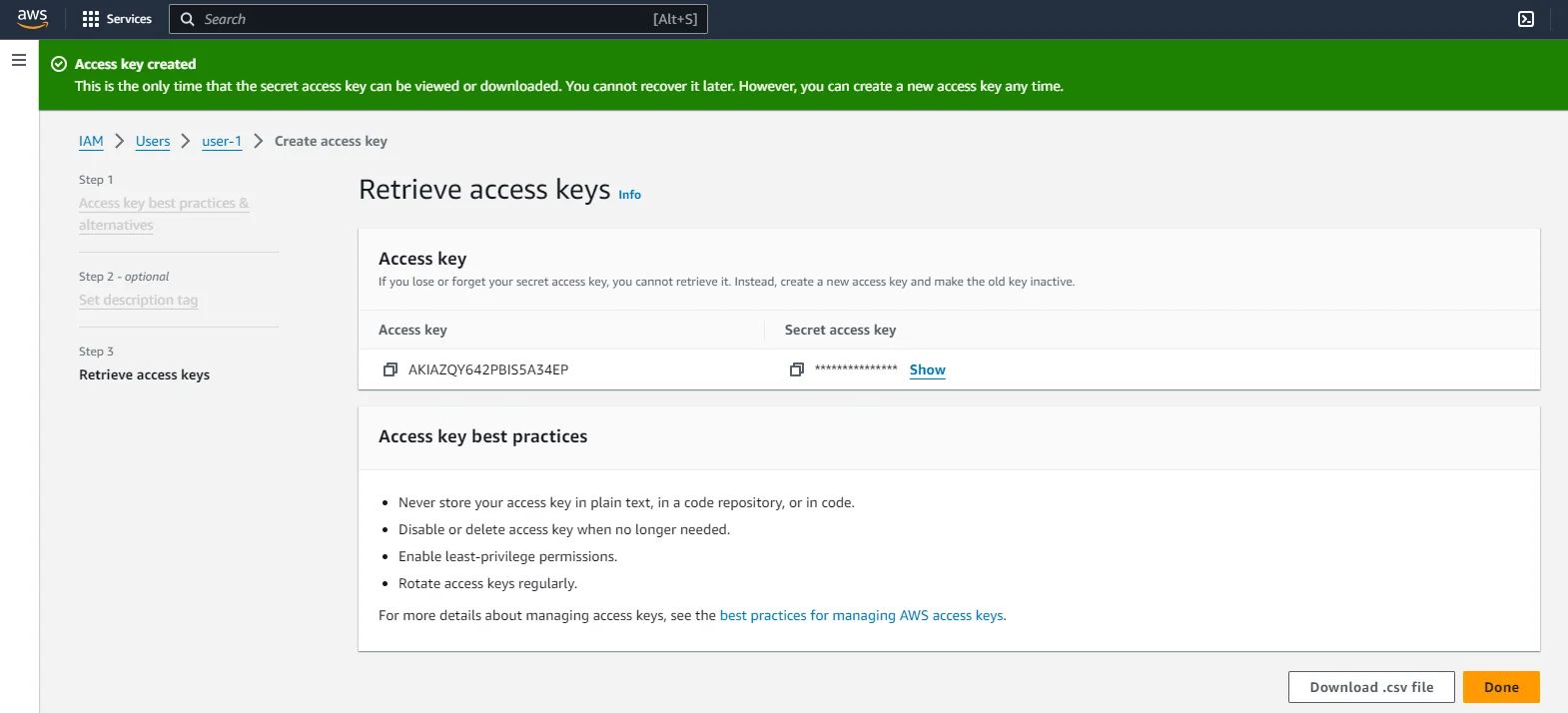
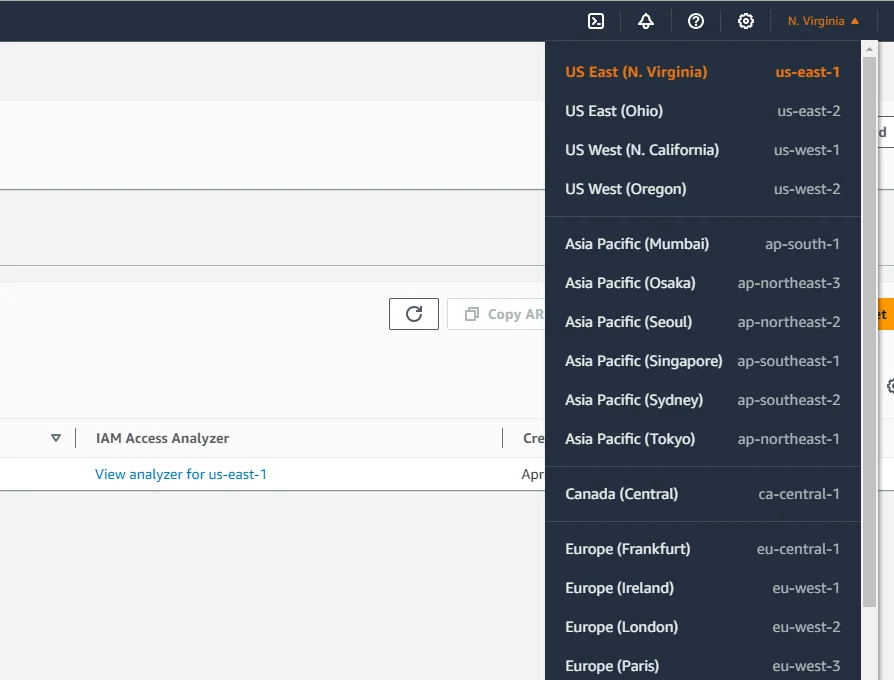
- Get AWS region name: ex. us-east-1
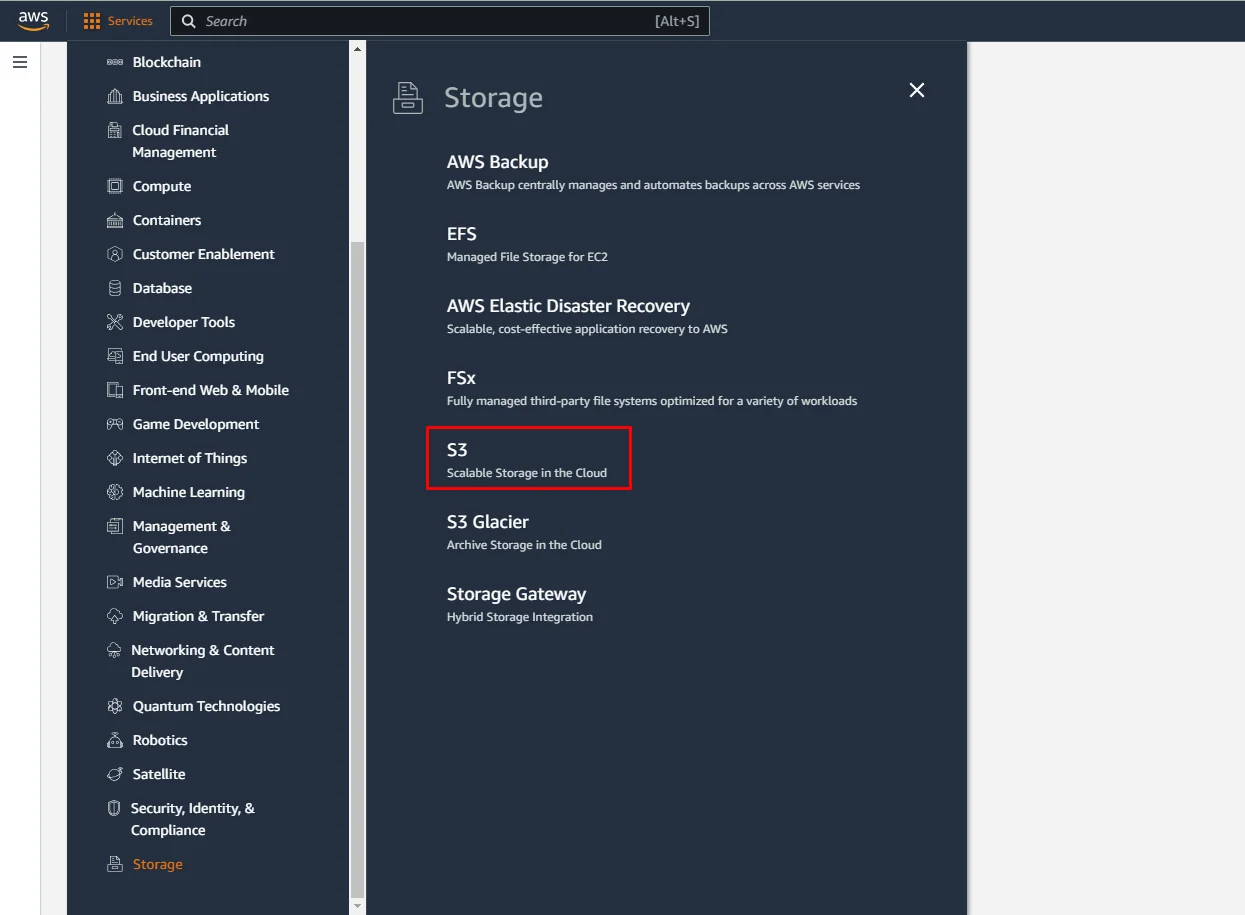
If you do not have an AWS S3 bucket, you will need to create a new one by following these steps:
- Access the S3 dashboard: You can find S3 under “Storage” on the services menu.
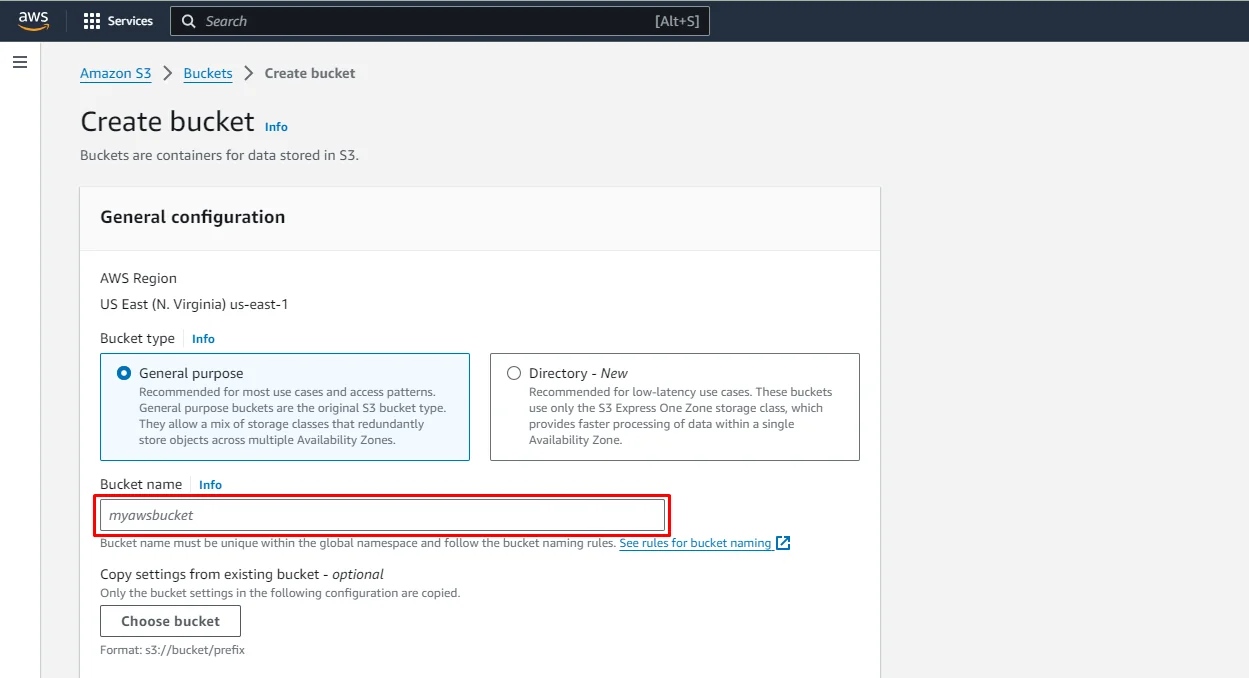
- Create a new bucket: On the S3 dashboard, click the “Create bucket” button.
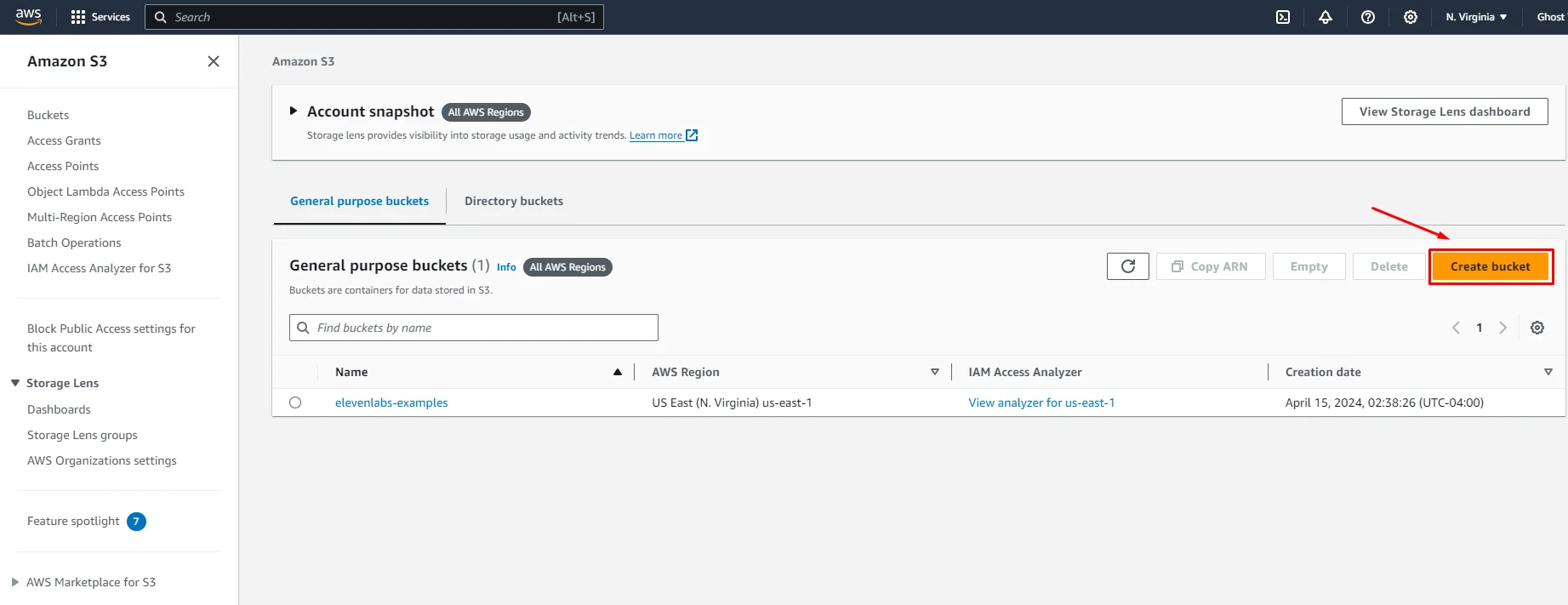
- Enter a bucket name and click on the “Create bucket” button. You can leave the other bucket options as default. The newly added bucket will appear in the list.
Installing the AWS SDK and adding the credentials
Install boto3 for interacting with AWS services using pip and npm.
Then add the environment variables to .env file like so:
Uploading to AWS S3 and generating the signed URL
Add the following functions to upload the audio stream to S3 and generate a signed URL.
You can then call uploading function with the audio stream from the text.
After uploading the audio file to S3, generate a signed URL to share access to the file. This URL will be time-limited, meaning it will expire after a certain period, making it secure for temporary sharing.
You can now generate a URL from a file with:
If you want to use the file multiple times, you should store the s3 file path in your database and then regenerate the signed URL each time you need rather than saving the signed URL directly as it will expire.
Putting it all together
To put it all together, you can use the following script:
Conclusion
You now know how to convert text into speech and generate a signed URL to share the audio file. This functionality opens up numerous opportunities for creating and sharing content dynamically.
Here are some examples of what you could build with this.
-
Educational Podcasts: Create personalized educational content that can be accessed by students on demand. Teachers can convert their lessons into audio format, upload them to S3, and share the links with students for a more engaging learning experience outside the traditional classroom setting.
-
Accessibility Features for Websites: Enhance website accessibility by offering text content in audio format. This can make information on websites more accessible to individuals with visual impairments or those who prefer auditory learning.
-
Automated Customer Support Messages: Produce automated and personalized audio messages for customer support, such as FAQs or order updates. This can provide a more engaging customer experience compared to traditional text emails.
-
Audio Books and Narration: Convert entire books or short stories into audio format, offering a new way for audiences to enjoy literature. Authors and publishers can diversify their content offerings and reach audiences who prefer listening over reading.
-
Language Learning Tools: Develop language learning aids that provide learners with audio lessons and exercises. This makes it possible to practice pronunciation and listening skills in a targeted way.