Studio
Create professional video and audio content with our end-to-end production workflow
Overview
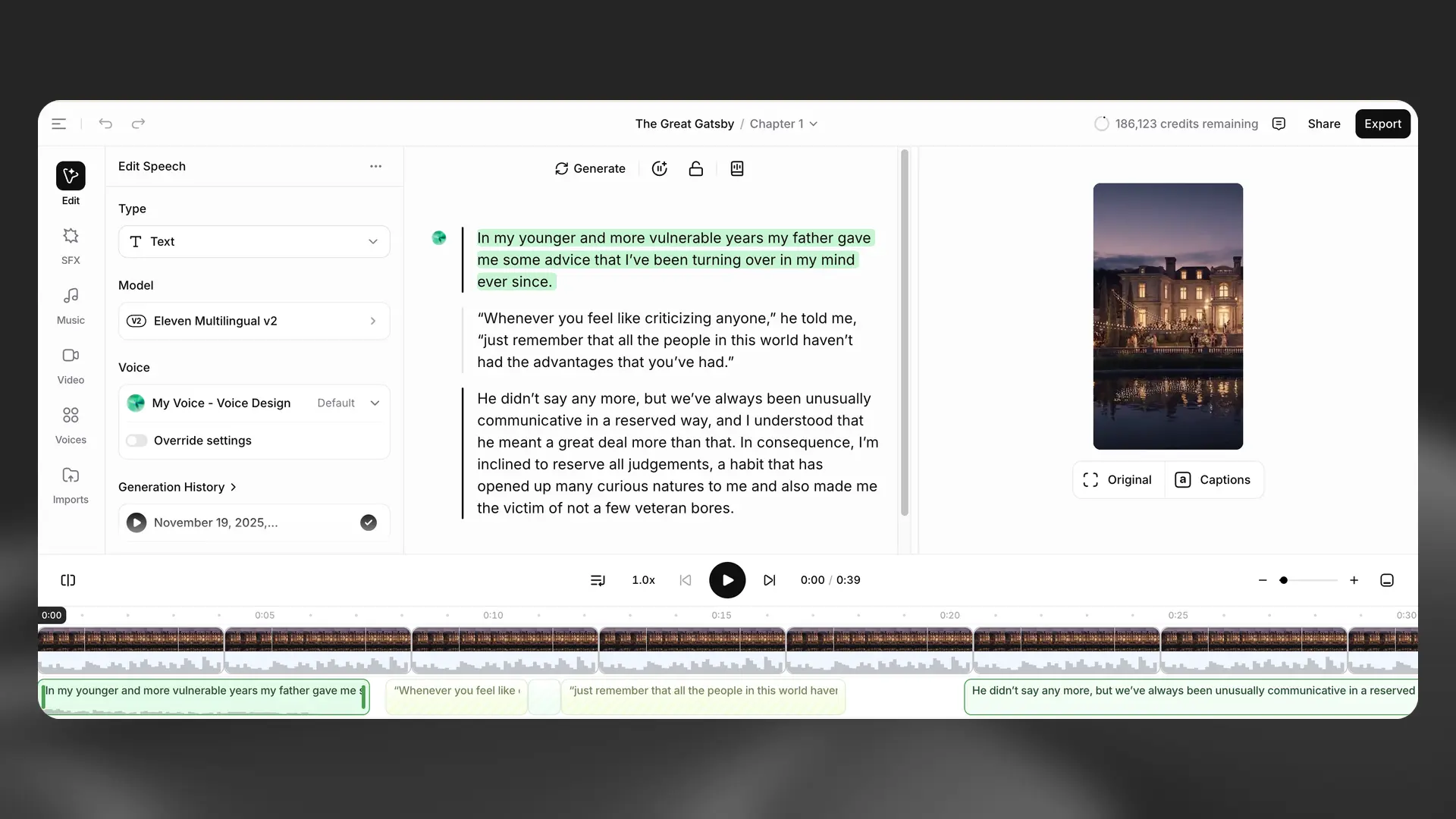
Studio provides an end‑to‑end workflow for creating video and audio content.
With Studio 3.0, you can now add a dedicated timeline with a video track and captions so you can build complete voiceovers. You can also layer music and sound effects on separate tracks, import external audio, and fine‑tune timing down to individual sentences. Once your project is ready for feedback, you can use our new sharing and commenting features to gather feedback from teammates.
Finally, you can export your work in various audio formats (per chapter or whole project) or as a video if a video track was included.
Studio supports our latest speech models, including v3. You can switch models at any time in Project settings.
Guide
Enhance your project
Add video, narration, music, and sound effects to your project using our timeline editor.
You can use our Audio Native feature to easily and effortlessly embed any Studio audio project onto your website.
Starting options
Some settings are automatically selected by default when you create a new project.
The default model is Multilingual v2 for most new projects. You can also choose newer models, including v3, in Project Settings.
The quality setting is automatically selected depending on your subscription plan, and will not increase your credit usage.
For free, Starter and Creator subscriptions the quality will be 128 kbps MP3, or WAV generated from 128 kbps source.
For Pro, Scale, Business and Enterprise plans, the quality will be 16-bit, 44.1 kHz WAV, or 192 kbps MP3 (Ultra Lossless).
Video exports on free and Starter plans include a watermark. To export videos without a watermark, you need a Creator plan or above.
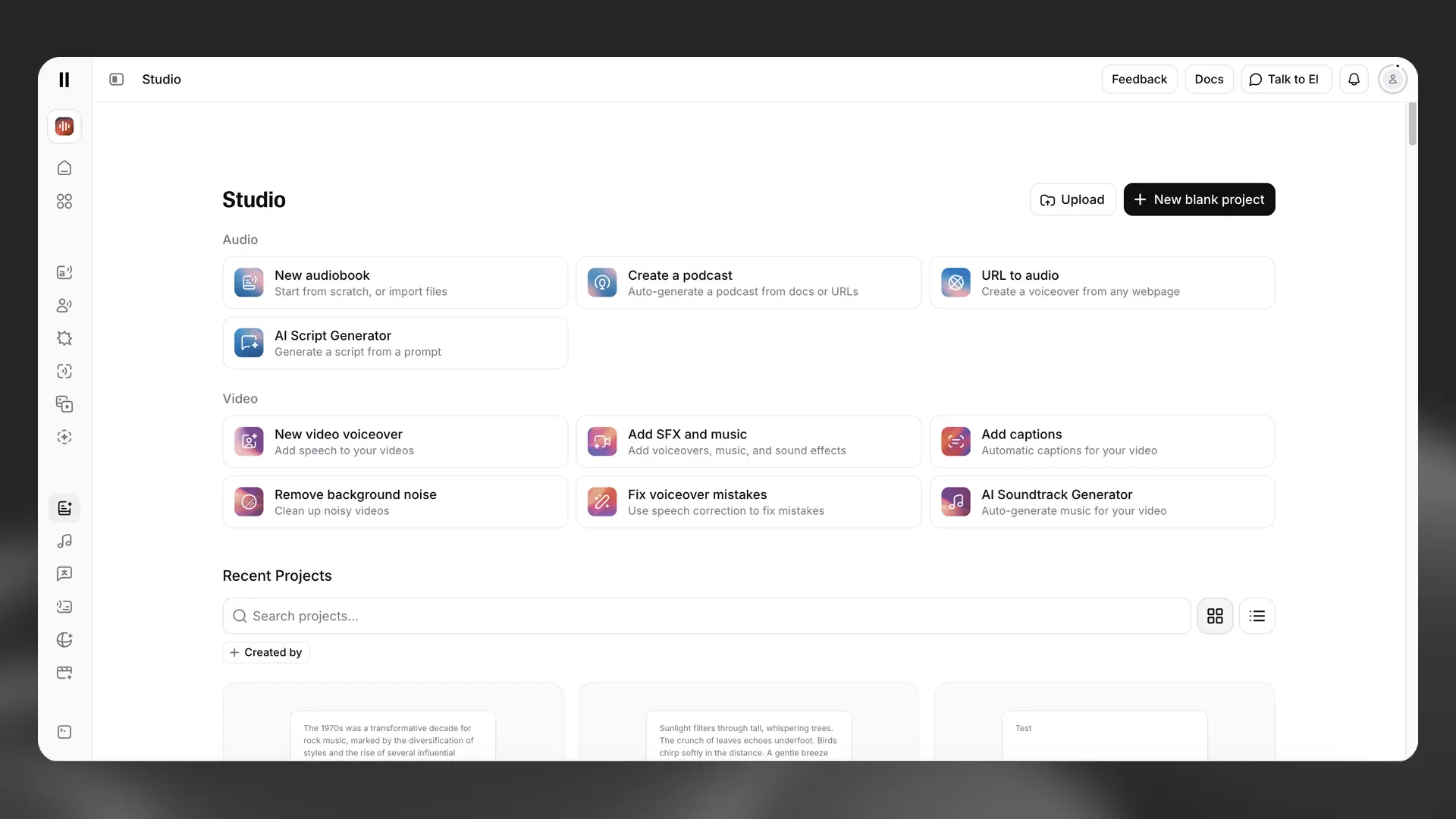
Quick start
Upload
Upload
Upload a file to start from existing media. We’ll analyze it and choose the best layout automatically: text or audio uploads open in the audio layout; video files open in the video layout with the timeline and captions available.
Start audio project from scratch
Start audio project from scratch
Create a blank audio project and begin writing your script. Add voices, music, and sound effects later from the timeline.
Start video project from scratch
Start video project from scratch
Create a blank video project with a video track ready to add footage, voiceover, and captions.
Audio
New audiobook
New audiobook
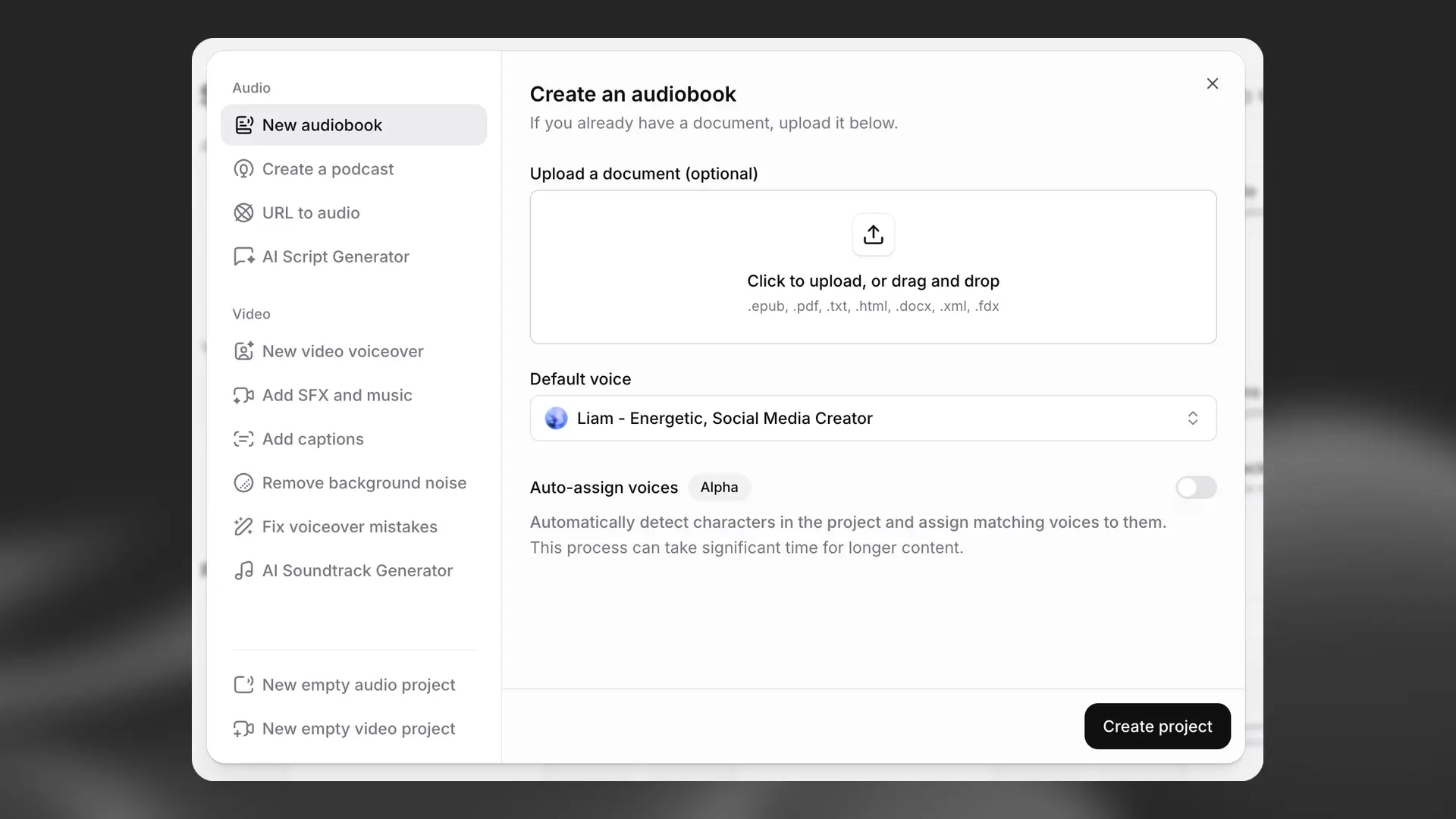
You’ll see a pop‑up to upload a file; we’ll import it into your new project.
You can upload EPUB, PDF, TXT, HTML, and DOCX files.
You can also select a default voice and optionally enable Auto‑assign voices to detect characters and assign matching voices. This adds some processing time.
Create a podcast
Create a podcast
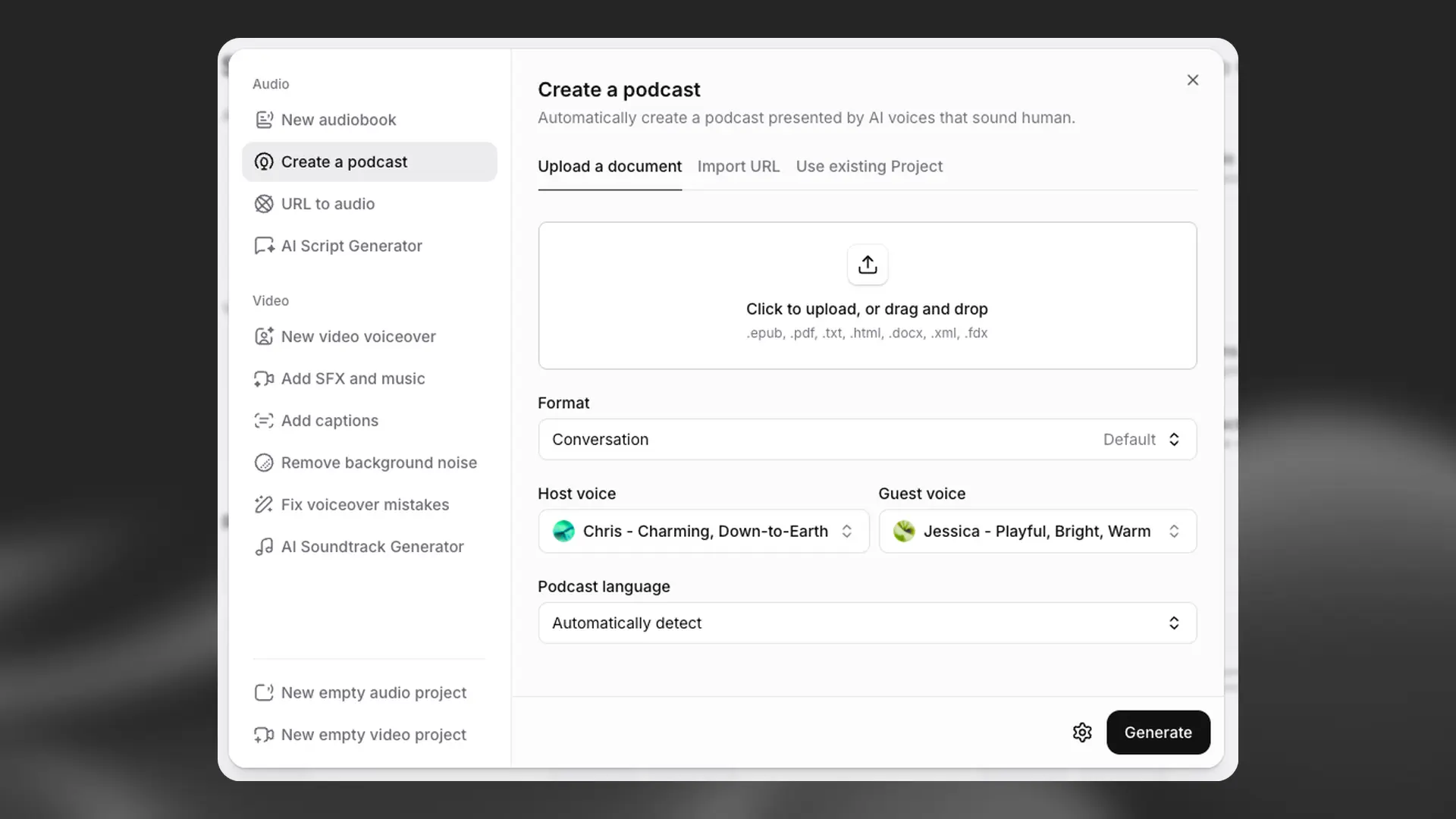
This option will use GenFM to automatically create a podcast based on an uploaded document, a webpage via URL, or an existing project.
With this option, GenFM will generate a new script from your source. If you want to keep your script unchanged, use New audiobook or Start audio project from scratch.
In the format settings, choose a conversation between a host and guest, or a more focused bulletin‑style podcast with a single host. You can also set the duration to short, default, or long.
You can choose your own preferred voices for the host and guest, or go with our suggested voices.
You can set the podcast language; if you don’t, it will match the language of the source material.
Use the cog icon to open advanced configuration and specify up to three focus areas.
URL to audio
URL to audio
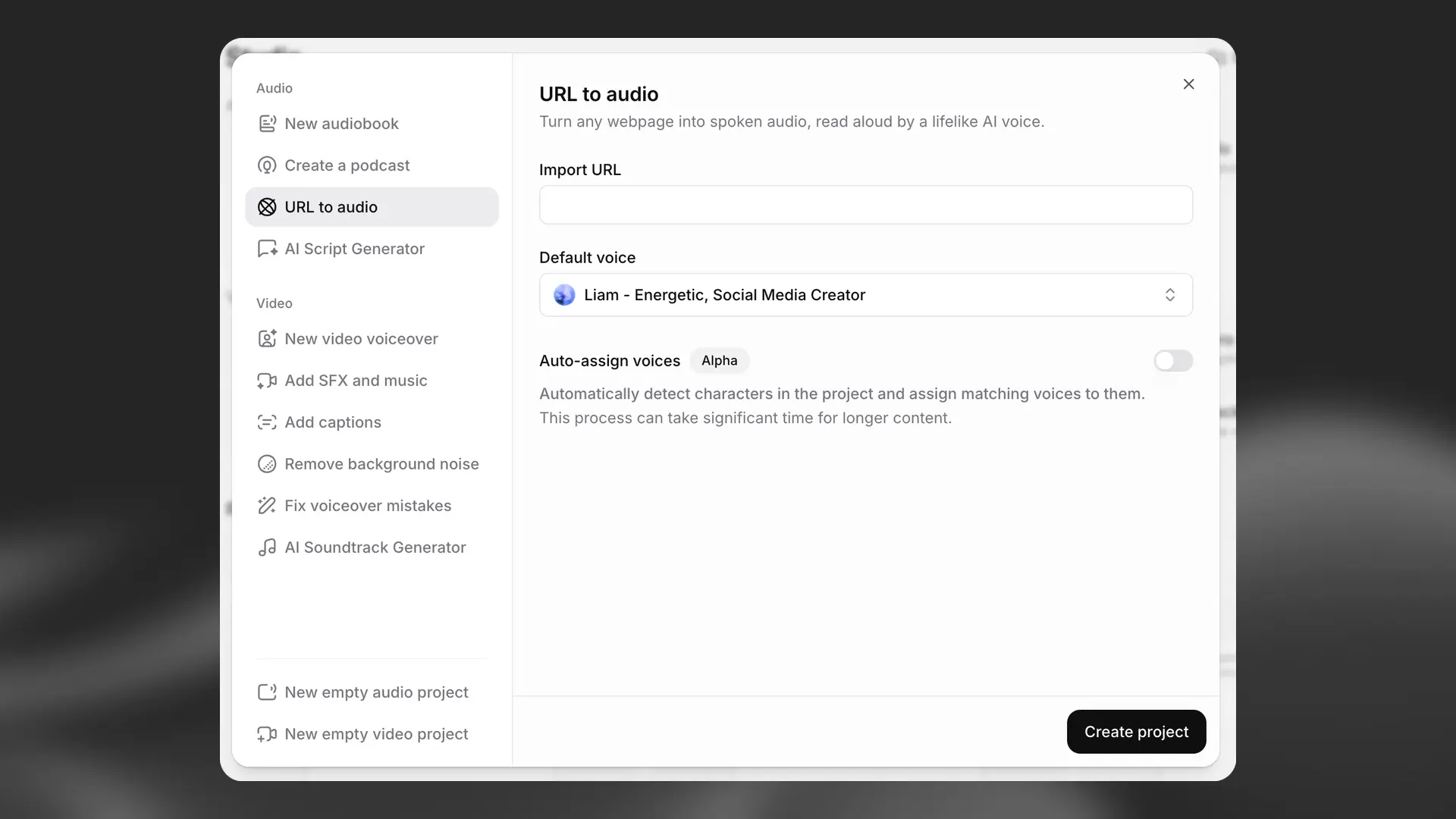
You’ll see a pop‑up to enter a URL; we’ll import the page text into your project.
You can also select a default voice for your project and optionally enable Auto‑assign voices to detect characters and assign matching voices. This adds some processing time.
AI Script Generator
AI Script Generator
Describe what you want and let the AI draft a script for you. Review the script, make edits, and start a new audio project from it.
Video
New video voiceover
New video voiceover
Create a project optimized for video voiceovers. Import your video, transcribe or generate narration, and enable captions with a chosen template.
Enhance your video
Enhance your video
Upload a video and let Studio suggest fitting music and sound effects. Tweak the mix on the timeline.
Add captions
Add captions
Open the Captions tab by default to transcribe narration or imported audio, then style captions with templates and positioning.
Remove background noise
Remove background noise
Upload a video and reduce background noise in the audio track. Proceed to add voiceover, music, and SFX as needed.
Fix voiceover mistakes
Fix voiceover mistakes
Upload a video and we’ll automatically transcribe the audio, flag potential misreads or timing issues, and help correct them with targeted speech regeneration.
AI Soundtrack Generator
AI Soundtrack Generator
Automatically generate music that matches your video’s mood and pacing, then place it on a dedicated music track.
Generating and Editing
Once you’ve added content, either by importing it or creating it yourself, you can use the Export button to render your chapter or project in one step. Narration will be generated where needed, and the output will be audio or video depending on your tracks and settings.
This will automatically generate and download an audio or video file, but you can still edit your project after this.
Once you’ve finished editing, you will need to use the Export button again to generate and download a new version of your project that includes the updated media.
Timeline and tracks
Timeline and tracks
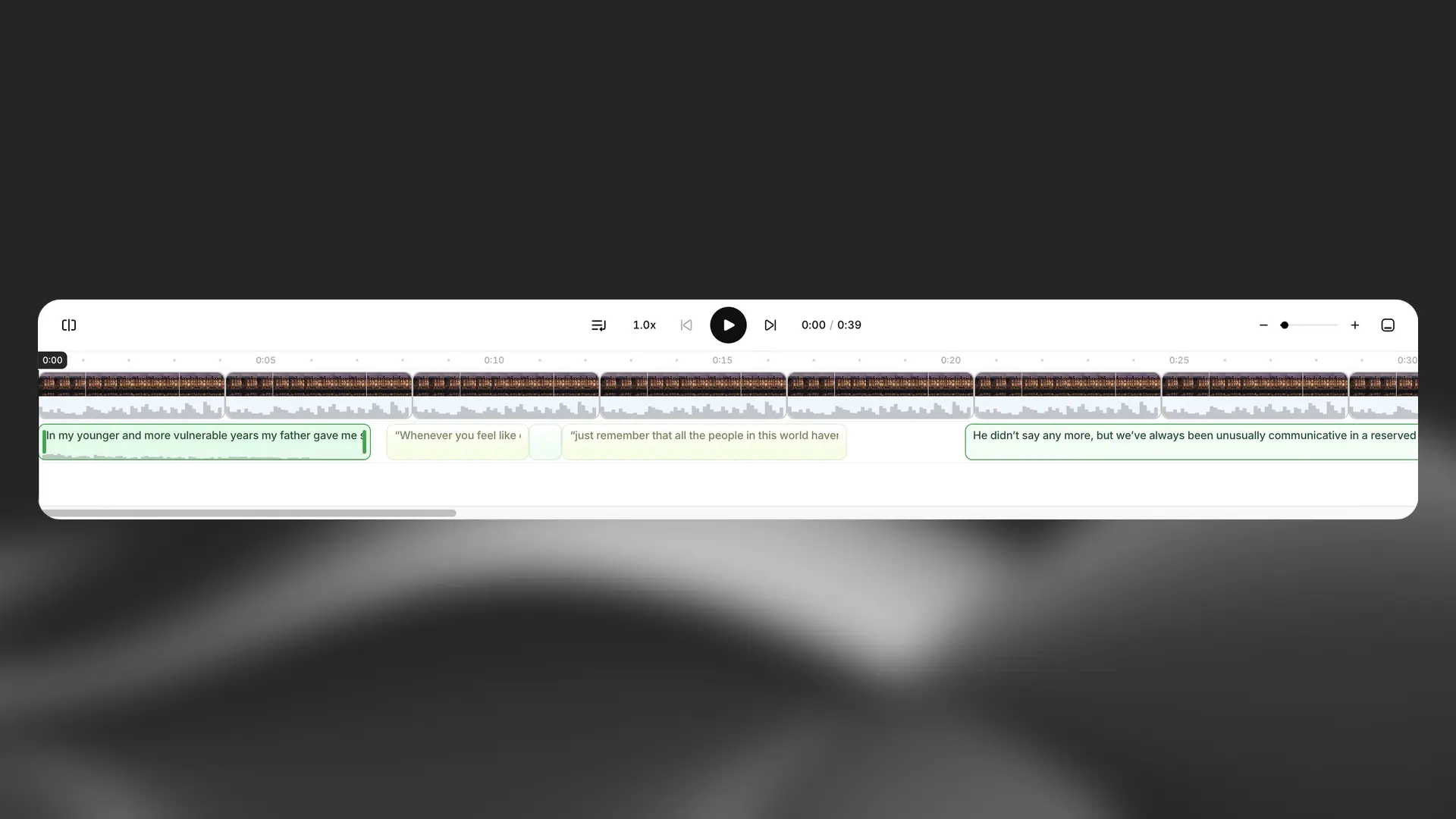
The timeline gives you a chapter‑wide view of your project so you can see narration, music, SFX, and video at a glance.
You can adjust timing between paragraphs and even individual sentences, trim clip edges, split and duplicate clips to iterate quickly, and zoom or pan to navigate longer chapters. Waveforms help you visualize loudness so you can align levels precisely across tracks.
Contextual sidebar
Contextual sidebar
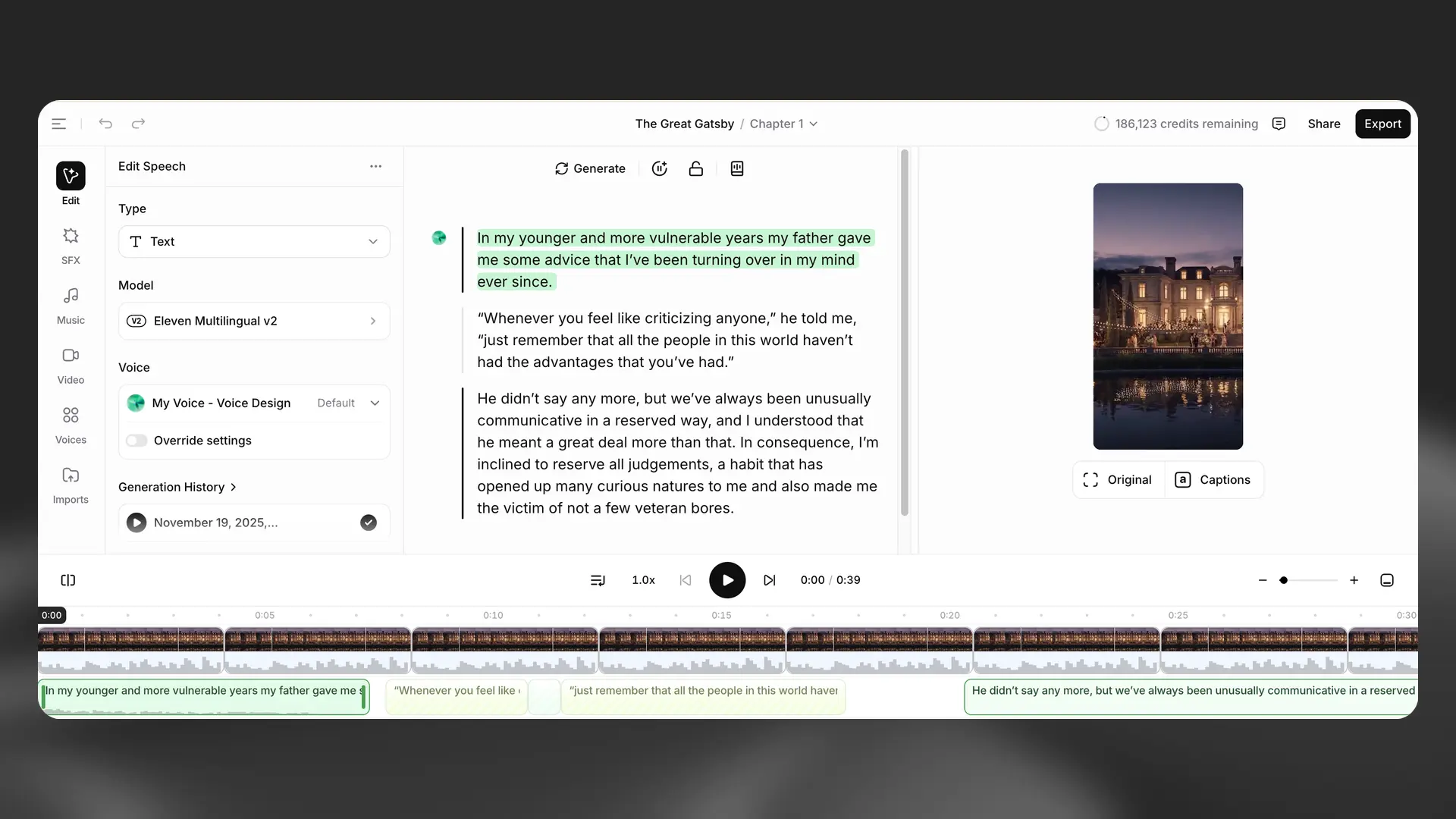
The Contextual sidebar shows tools and details for the currently selected item in your project. For narration, you’ll see voice and delivery controls; for media clips (audio, music, SFX, or video), you’ll see relevant clip properties and actions.
Chapters sidebar
Chapters sidebar
When you create a Studio project using the New audiobook option and import a document that includes chapters, chapters will be automatically detected.
To manage chapters in an existing project, go to Project options in the top left corner, then select Manage chapters. This will open the Chapters sidebar.
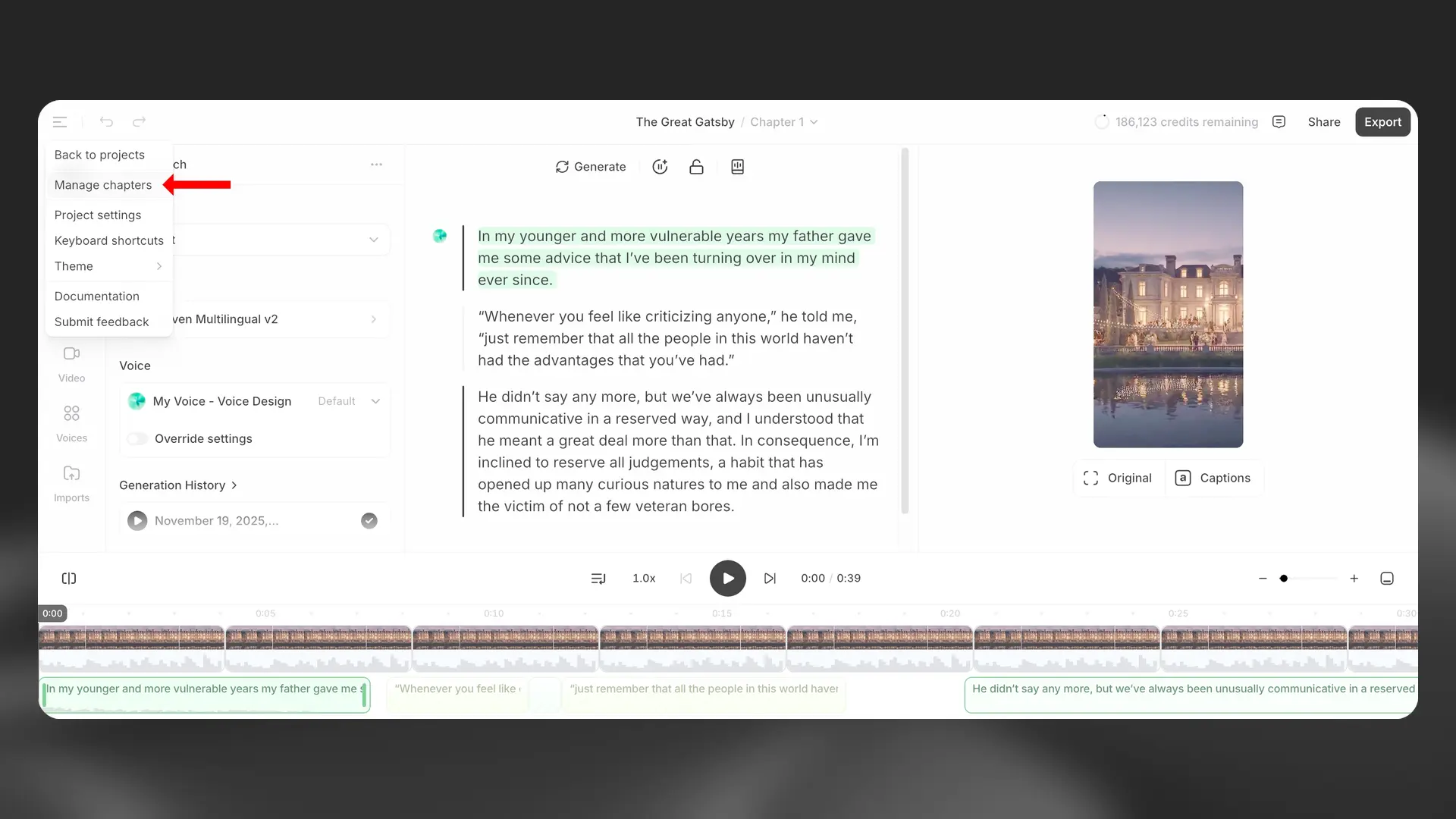
You can add a new chapter using the + button. You can also rename and remove chapters using the Chapter actions (three dots) button, and drag and drop the chapters to rearrange them.
Generate/Regenerate
Generate/Regenerate
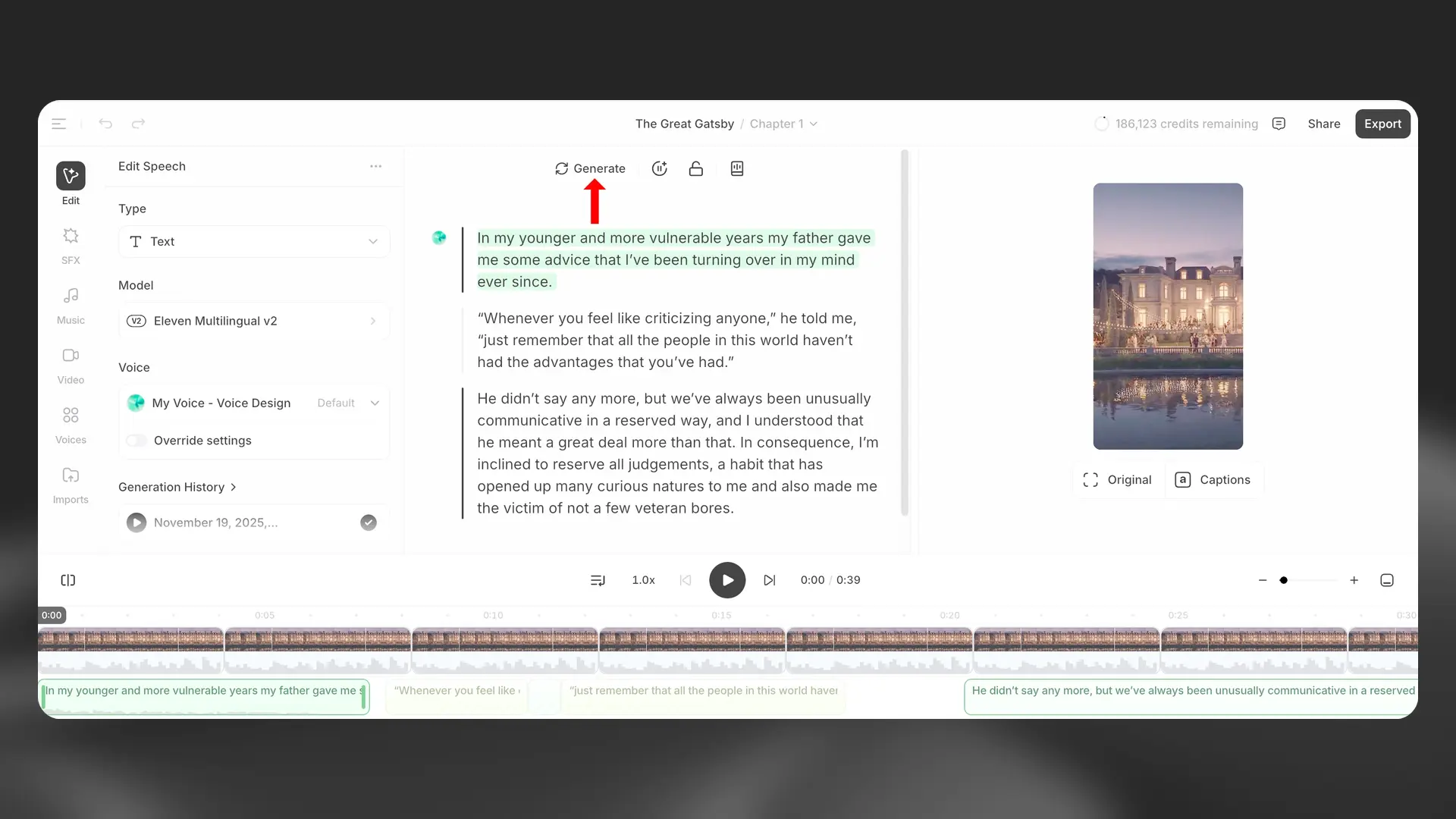
The Generate button will generate audio if you have not yet generated audio for the selected text, or will generate new audio if you have already generated audio. This will cost credits.
If you have made changes to the paragraph such as changing the text or the voice, then the paragraph will lose its converted status, and will need to be generated again.
The status of a paragraph (converted or unconverted) is indicated by the bar to the left of the paragraph. Unconverted paragraphs have a pale grey bar while converted paragraphs have a dark grey bar.
If the button says Regenerate, then this means that you won’t be charged for the next generation. You’re eligible for two free regenerations provided you don’t change the voice or the text.
This action applies to narration and other generated speech. Timeline items like video, external audio, music, SFX, and captions are arranged on the timeline and rendered when you export.
Play
Play
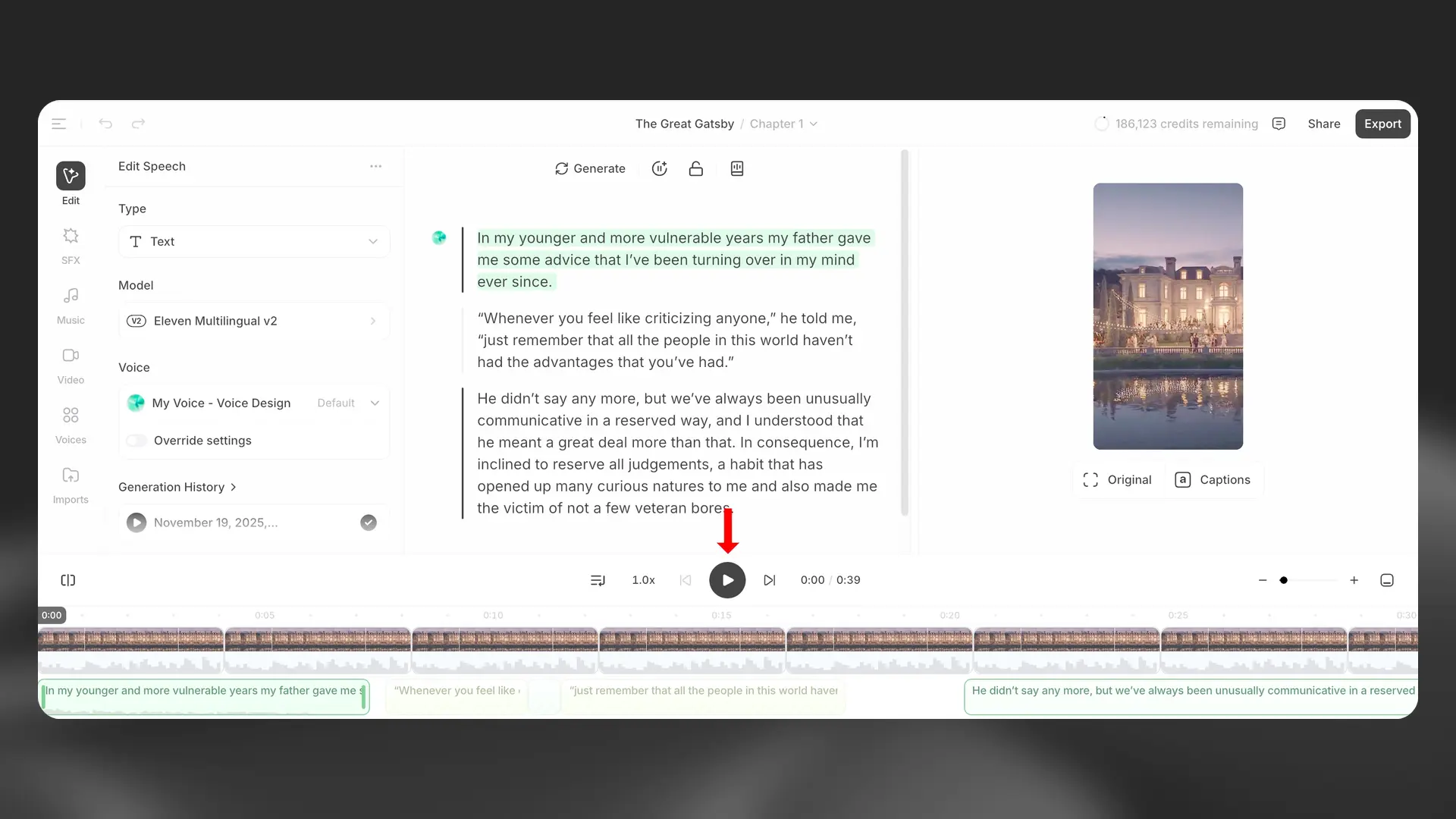
You can use the Play button in the player at the bottom of the Studio interface to play audio that has already been generated, or generate audio if a paragraph has not yet been converted. Generating audio will cost credits. If you have already generated audio, then the Play button will play the audio that has already generated and you won’t be charged any credits. There are three modes when using the Play button. Until end (generate clips ahead) will play existing audio, or generate new audio for paragraphs that have not yet been generated, from the selected paragraph to the end of the current chapter, generating multiple clips ahead. Until end (generate one at a time) will play existing audio or generate new audio from the selected paragraph to the end of the current chapter, but generates only one clip at a time. Selection will play or generate audio only for the selected paragraph. When a video track is present, the player also previews video in sync with the playhead. Playing existing audio or video never consumes credits; only generating narration does.
Generation history
Generation history
The generation history for a paragraph appears in the contextual sidebar when the paragraph is selected. This shows all the previously generated audio for the selected paragraph, allowing you to listen to and download each individual generation.
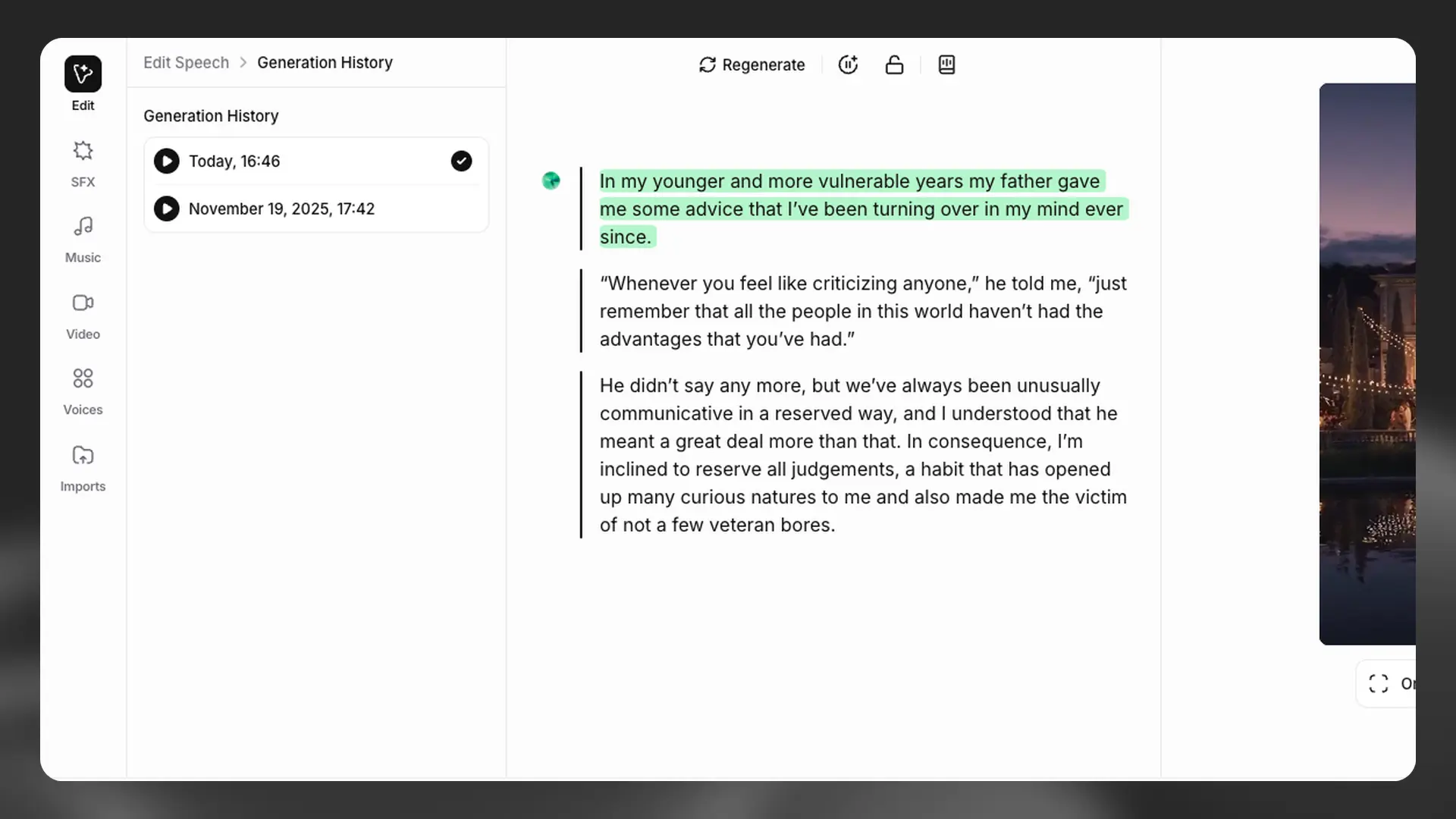
If you prefer an earlier version of a paragraph, you can restore it to that previous version. You can also remove generations, but be aware that if you remove a version, this is permanent and you can’t restore it.
Generation history applies to narration generations. It doesn’t track imported media (external audio, music, SFX) or video clips.
Undo and Redo
Undo and Redo
If you accidentally make a change, you can use the Undo button to restore the previous version, and the Redo button to restore the change.
Breaks
Breaks
You can add a pause by using the Insert break button. This inserts a break tag. By default, this will be set to 1 second, but you can change the length of the break up to a maximum of 3 seconds.
For precise timing, prefer the timeline with trimming and sentence‑level control. Some newer models may reduce or ignore break tags in favor of natural flow.
Breaks affect generated speech delivery only; they don’t move or pause other timeline tracks. Use the timeline to create precise pauses across music, SFX, and video.
Actor Mode
Actor Mode
Actor Mode allows you to specify exactly how you would like a section of text to be delivered by uploading a recording, or by recording yourself directly. You can either highlight a selection of text that you want to work on, or select a whole paragraph. Once you have selected the text you want to use Actor Mode with, click Direct speech with your voice from the AI Tools section of the sidebar, and the Actor Mode pop-up will appear.
For an overview of Actor Mode, see this video.
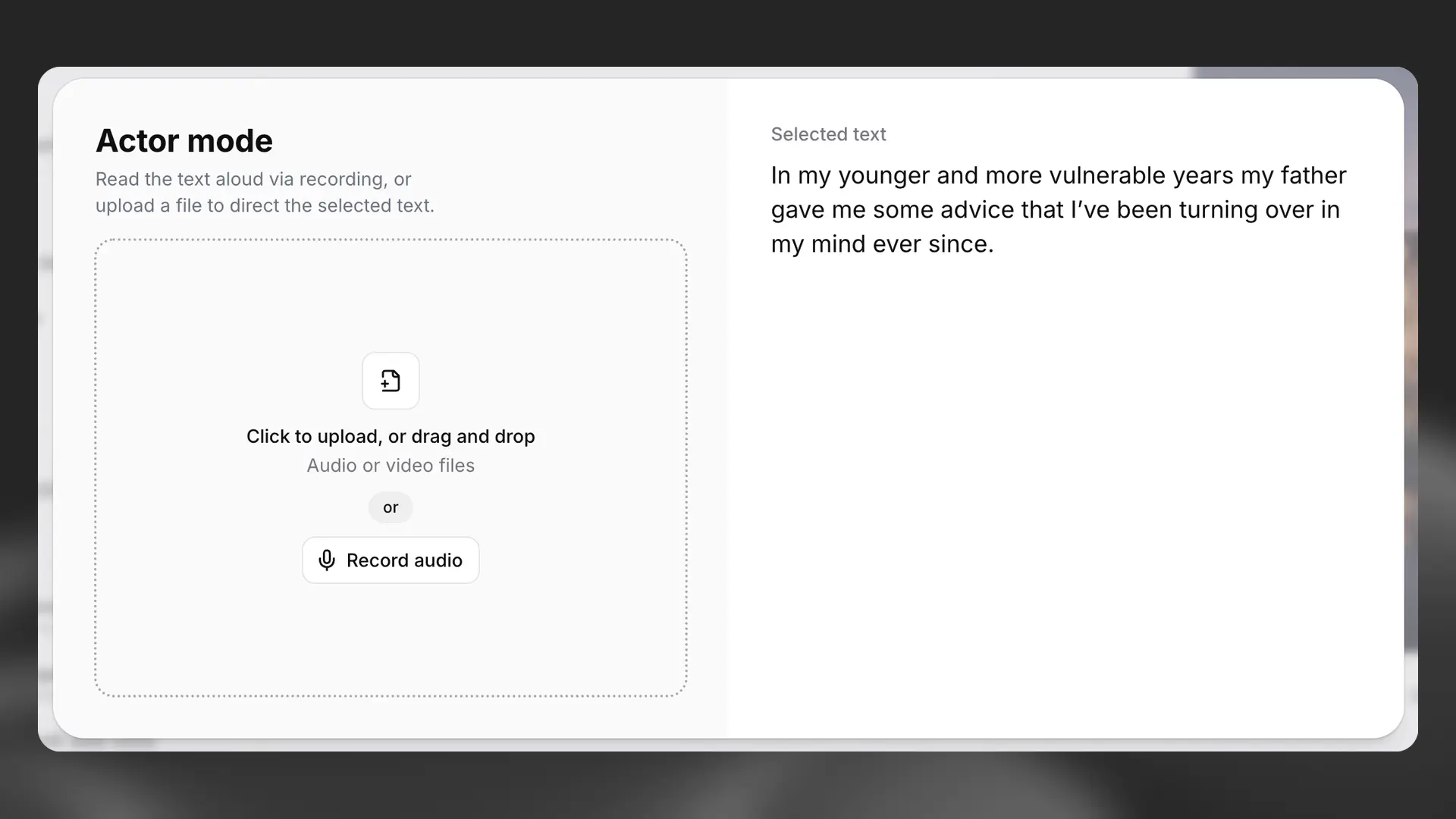
Either upload or record your audio, and you will then see the option to listen back to the audio or remove it. You will also see how many credits it will cost to generate the selected text using the audio you’ve provided.
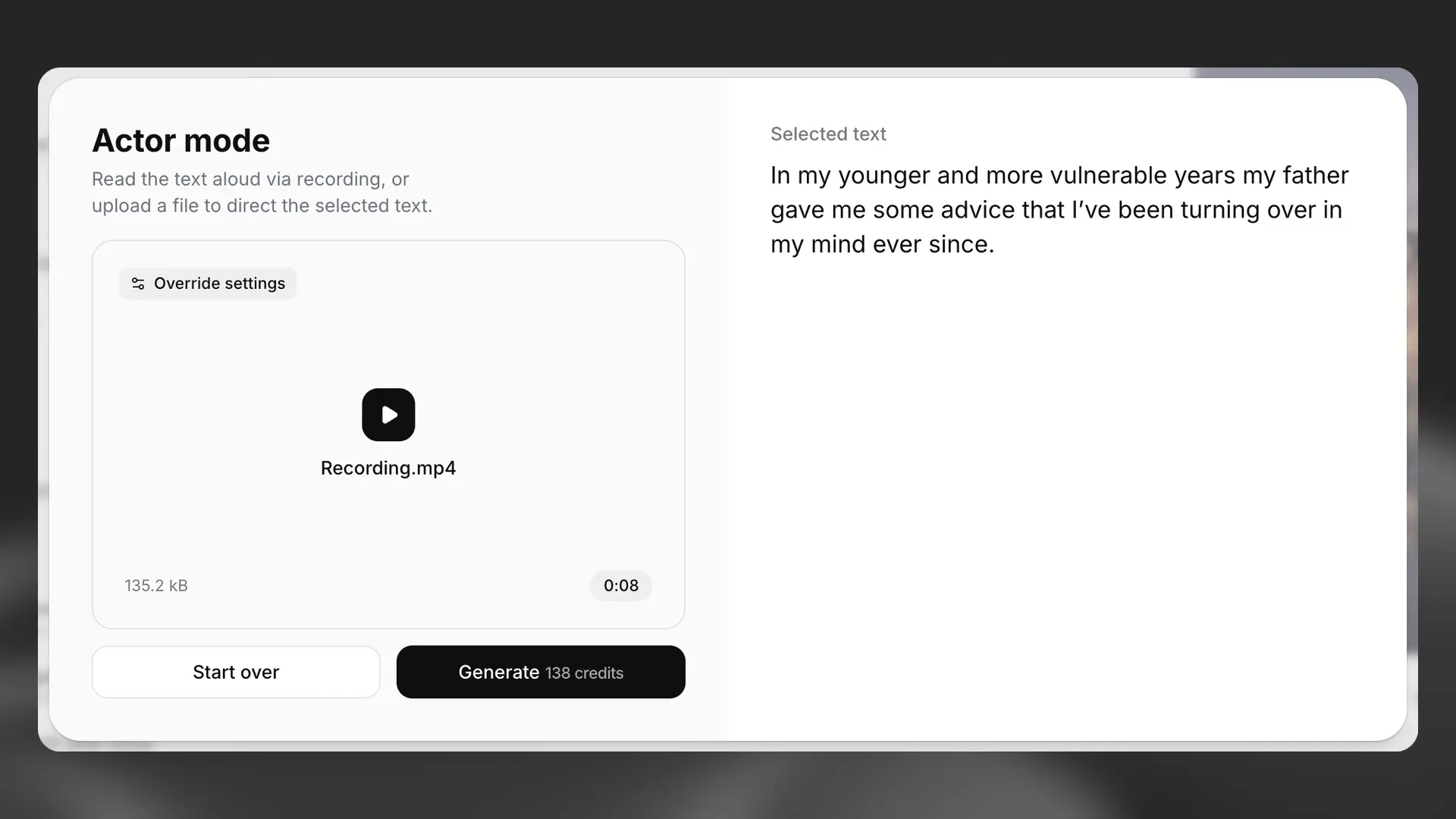
If you’re happy with the audio, click Generate, and your audio will be used to guide the delivery of the selected text.
Actor Mode will replicate all aspects of the audio you provide, including the accent.
Video track and voiceovers
Video track and voiceovers
Add a video track to voice over existing footage or to pair narration with b‑roll. Import a video file or add a blank track, then align the narration to key visual beats on the timeline. When needed, enable captions and choose a template to match your style.
Captions
Captions
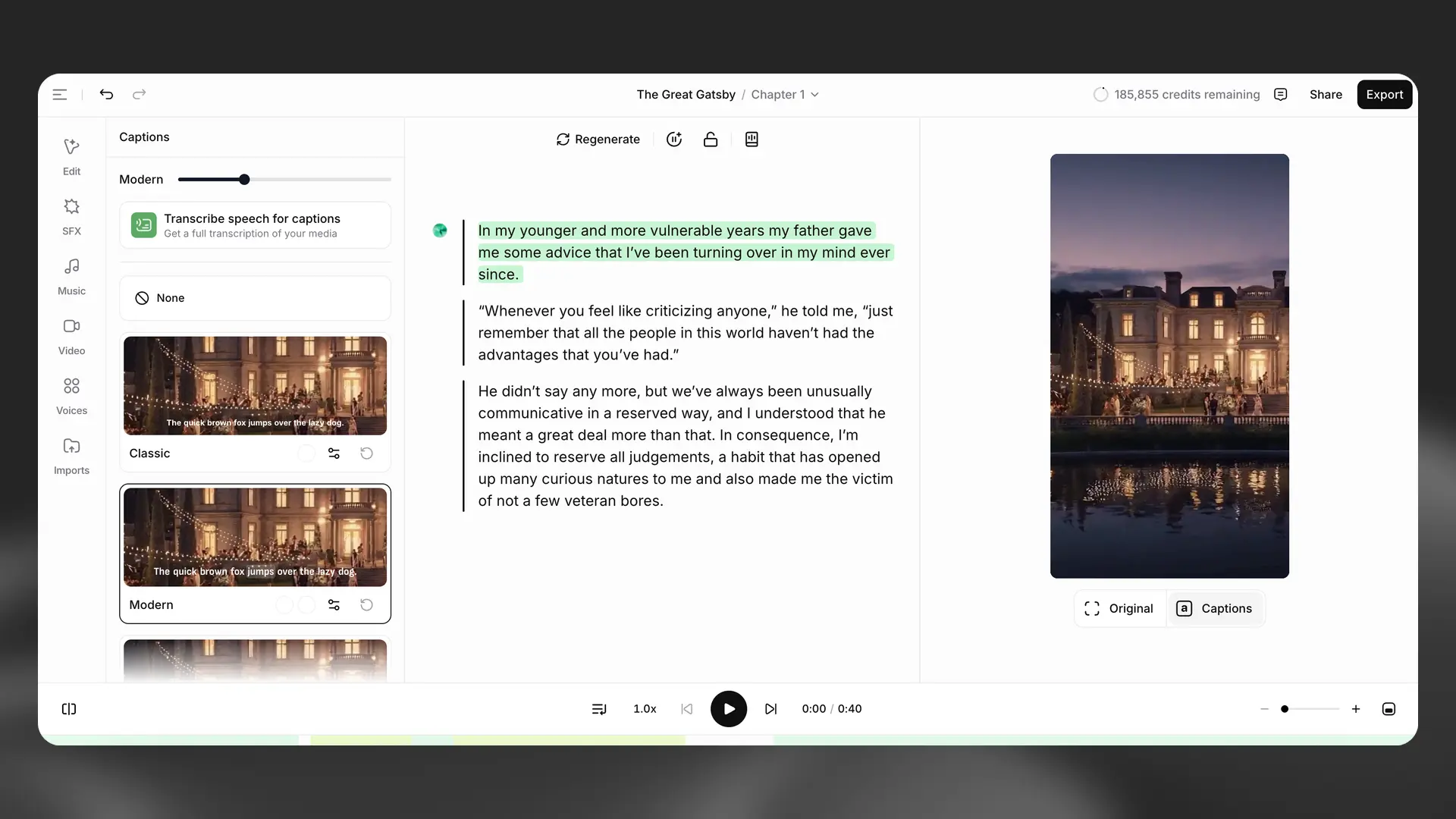
Convert narration into styled captions for accessibility and engagement. Captions are generated automatically and can be customized with templates for colors, fonts, and placement. Edit text and timing directly on the timeline to correct any mismatches, then export your video with burned‑in captions.
External audio
External audio
Import your own audio files - such as dialogue, stingers, or ambience - and mix them with narration, music, and SFX. Drag files into the timeline or use the import action, then trim, split, duplicate, and adjust clip volume as needed. Stereo files remain stereo on export.
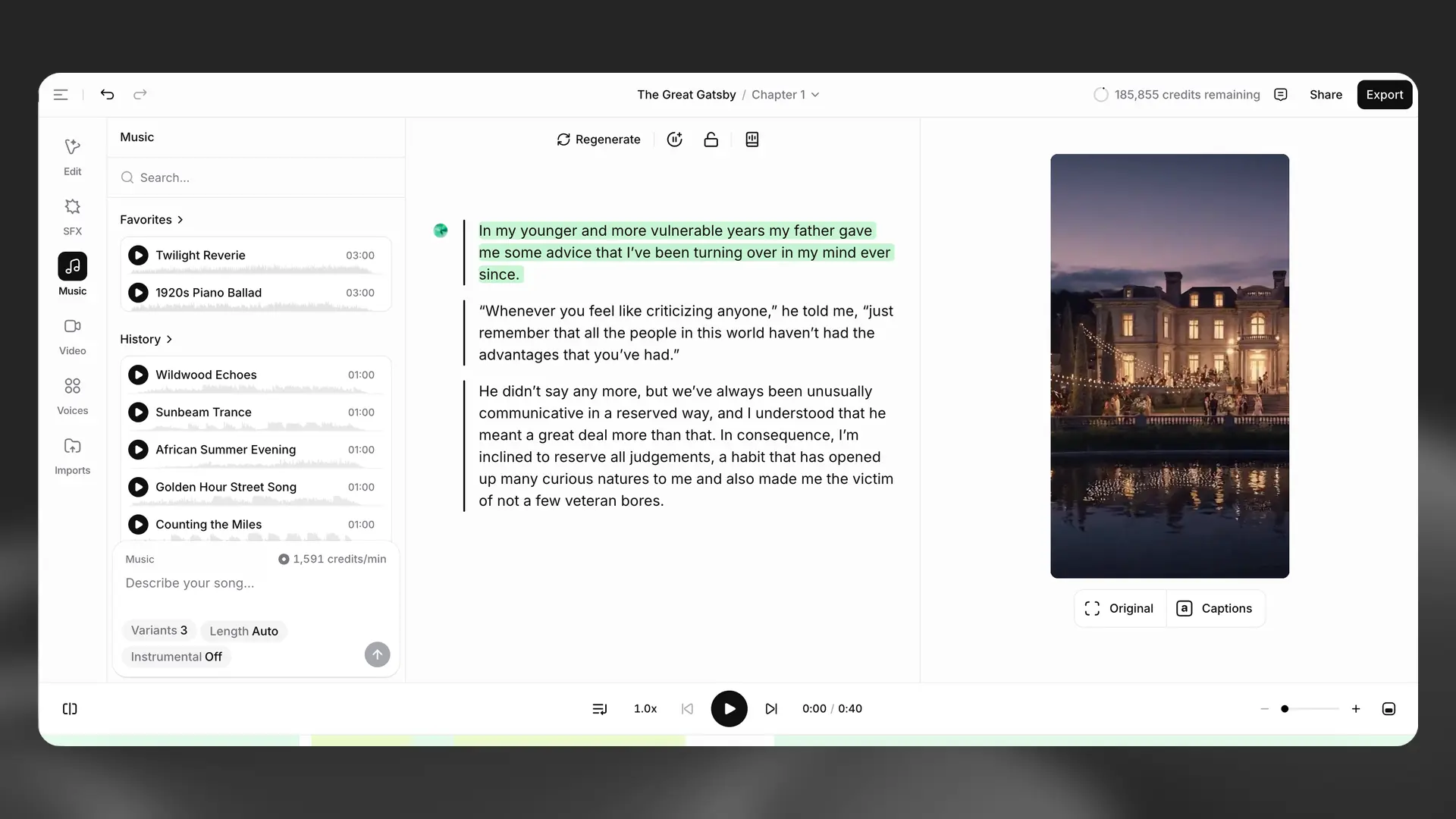
Music
Music
Generate music directly in Studio and place it on its own track in the timeline. Create new songs from prompts (choose a vibe and length) or import existing tracks. Music clips can be trimmed duplicated and moved to match the narration, and you can adjust volume per clip. When the source is stereo stereo is preserved.
Sound effects
Sound effects
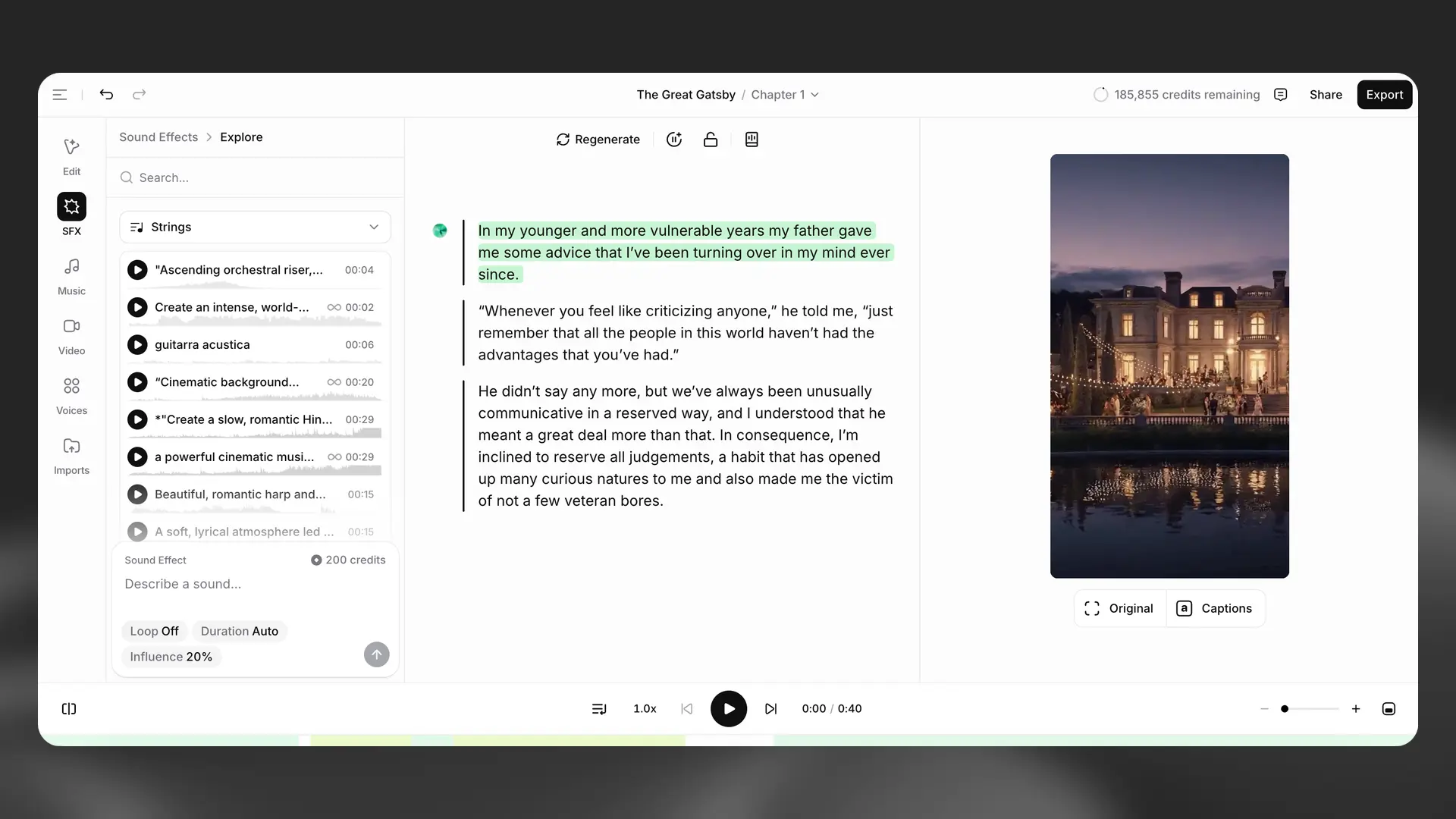
Add sound effects as separate clips on the timeline. You can position them anywhere, layer multiple effects, and adjust their timing precisely with trimming and duplication.
You can create effects from a text prompt inside Studio or browse and insert items from the SFX library.
You can regenerate previews to explore variants and then apply your chosen effect to the timeline. Deleting and duplicating SFX clips works the same as other timeline clips.
Sound effects are not supported in ElevenReader exports, or when streaming the project using the Studio API.
Lock paragraph
Lock paragraph
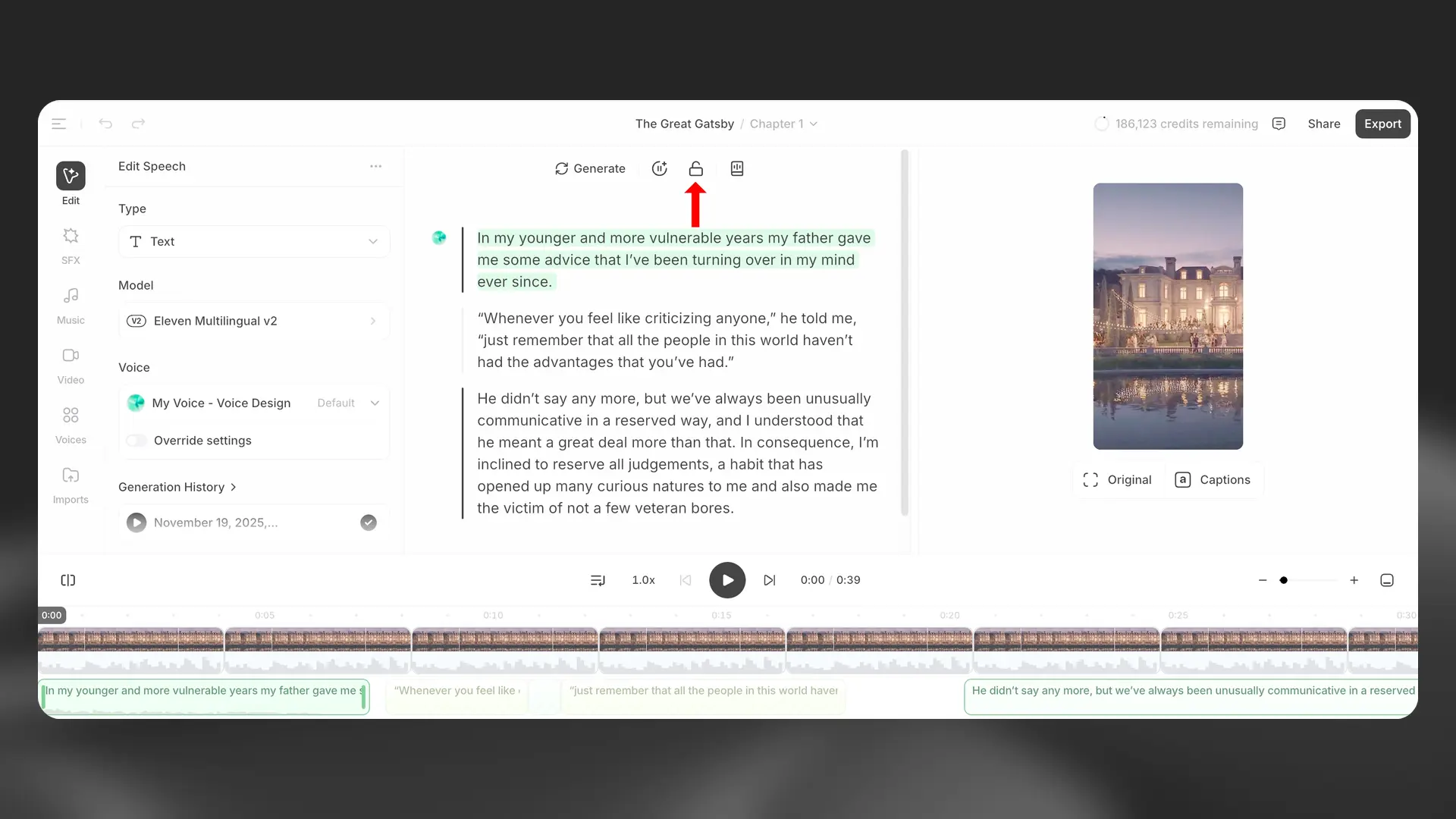
Once you’re happy with the performance of a paragraph, you can use the Lock paragraph button to prevent any further changes.

Locked paragraphs are indicated by a lock icon to the left of the paragraph. If you want to unlock a paragraph, you can do this by clicking the Lock paragraph button again. Locking applies to narration content; you can continue editing timeline clips like video, music, and SFX.
Keyboard shortcuts
Keyboard shortcuts
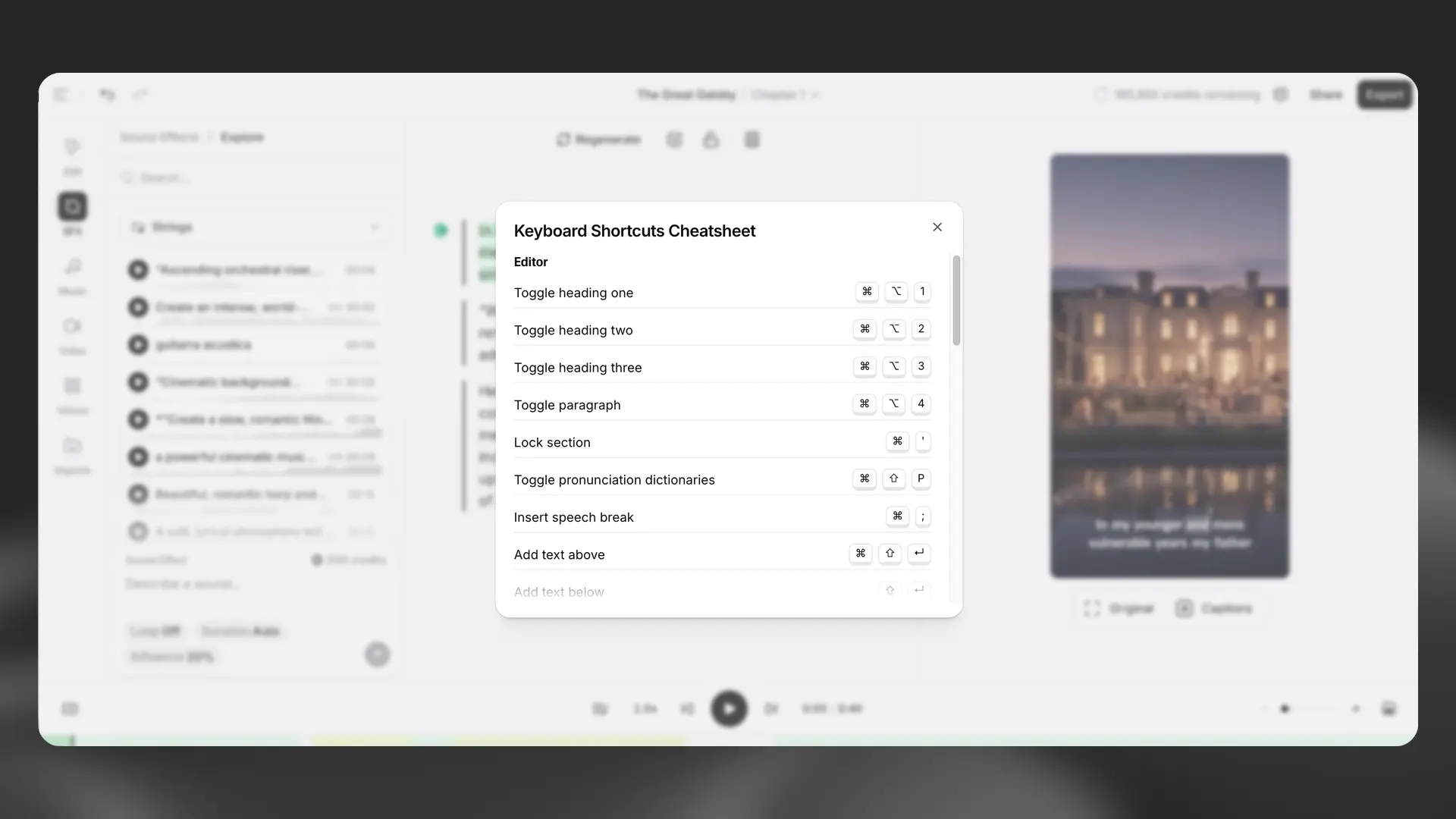
There are a range of keyboard shortcuts that can be used in Studio to speed up your workflow. To see a list of all available keyboard shortcuts, click the Project options button, then select Keyboard shortcuts.
Settings
Voices
Voices
We offer many types of voices, including the curated Default Voices library; completely synthetic voices created using our Voice Design tool; and you can create your own collection of cloned voices using our two technologies: Instant Voice Cloning and Professional Voice Cloning. Browse through our voice library to find the perfect voice for your production.
Not all voices are equal, and a lot depends on the source audio used to create that voice. Some voices will perform better than others, while some will be more stable than others. Additionally, certain voices will be more easily cloned by the AI than others, and some voices may work better with one model and one language compared to another. All of these factors are important to consider when selecting your voice.
If you’re unhappy with a voice, but you’re happy with the delivery of the narration, you can use our Voice Changer functionality to change the voice, but preserve the narration
Voice settings
Voice settings
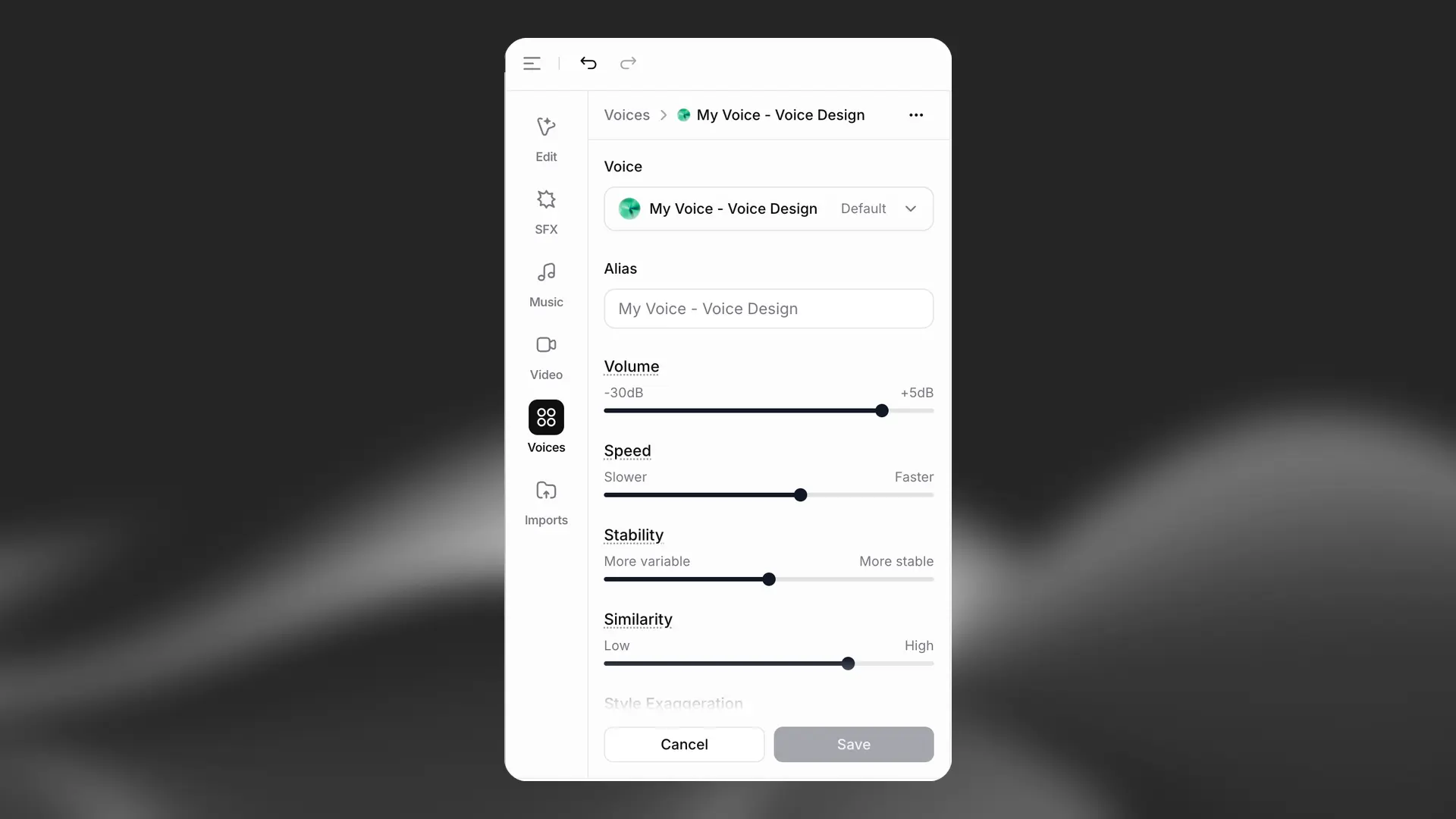
Our users have found different workflows that work for them. The most common setting is stability around 50 and similarity near 75, with minimal changes thereafter. Of course, this all depends on the original voice and the style of performance you’re aiming for.
It’s important to note that the AI is non-deterministic; setting the sliders to specific values won’t guarantee the same results every time. Instead, the sliders function more as a range, determining how wide the randomization can be between each generation.
If you have a paragraph or text selected, you can use the Override settings toggle to change the settings for just the current selection. If you change the settings for the voice without enabling this, then this will change the settings for this voice across the whole of your project. This will mean that you will need to regenerate any audio that you had previously generated using different settings. If you have any locked paragraphs that use this voice, you won’t be able to change the settings unless you unlock them.
Alias
You can use this setting to give the voice an alias that applies only for this project. For example, if you’re using a different voice for each character in your audiobook, you could use the character’s name as the alias.
Volume
If you find the generated audio for the voice to be either too quiet or too loud, you can adjust the volume. The default value is 0.00, which means that the audio will be unchanged. The minimum value is -30 dB and the maximum is +5 dB.
Speed
The speed setting allows you to either speed up or slow down the speed of the generated speech. The default value is 1.0, which means that the speed is not adjusted. Values below 1.0 will slow the voice down, to a minimum of 0.7. Values above 1.0 will speed up the voice, to a maximum of 1.2. Extreme values may affect the quality of the generated speech.
Stability
The stability slider determines how stable the voice is and the randomness between each generation. Lowering this slider introduces a broader emotional range for the voice. This is influenced heavily by the original voice. Setting the slider too low may result in odd performances that are overly random and cause the character to speak too quickly. On the other hand, setting it too high can lead to a monotonous voice with limited emotion.
For a more lively and dramatic performance, it is recommended to set the stability slider lower and generate a few times until you find a performance you like.
On the other hand, if you want a more serious performance, even bordering on monotone at very high values, it is recommended to set the stability slider higher. Since it is more consistent and stable, you usually don’t need to generate as many samples to achieve the desired result. Experiment to find what works best for you!
Similarity
The similarity slider dictates how closely the AI should adhere to the original voice when attempting to replicate it. If the original audio is of poor quality and the similarity slider is set too high, the AI may reproduce artifacts or background noise when trying to mimic the voice if those were present in the original recording.
Style exaggeration
With the introduction of the newer models, we also added a style exaggeration setting. This setting attempts to amplify the style of the original speaker. It does consume additional computational resources and might increase latency if set to anything other than 0. It’s important to note that using this setting has shown to make the model slightly less stable, as it strives to emphasize and imitate the style of the original voice.
In general, we recommend keeping this setting at 0 at all times.
Speaker boost
This setting boosts the similarity to the original speaker. However, using this setting requires a slightly higher computational load, which in turn increases latency. The differences introduced by this setting are generally rather subtle.
Pronunciation dictionaries
Pronunciation dictionaries

Sometimes you may want to specify the pronunciation of certain words, such as character or brand names, or specify how acronyms should be read. Pronunciation dictionaries allow this functionality by enabling you to upload a lexicon or dictionary file that includes rules about how specified words should be pronounced, either using a phonetic alphabet (phoneme tags) or word substitutions (alias tags).
Phoneme tags are only compatible with “Eleven Flash v2”, “Eleven Turbo v2” and “Eleven English v1” models.
Whenever one of these words is encountered in a project, the AI will pronounce the word using the specified replacement. When checking for a replacement word in a pronunciation dictionary, the dictionary is checked from start to end and only the first replacement is used.
Existing pronunciation dictionaries can be connected to your project from the Pronunciations Editor. You can open this from the toolbar. Find the dictionary you want to connect in the drop down menu and select Connect.
You can create a new pronunciation dictionary from your project by creating an entry in the Pronunciations Editor, or you can upload or create a pronunciation dictionary from Open all pronunciation dictionaries in the Pronunciations Editor. You can then select Connect to connect the pronunciation dictionary to the current project.
For more information on pronunciation dictionaries, please see our prompting best practices guide.
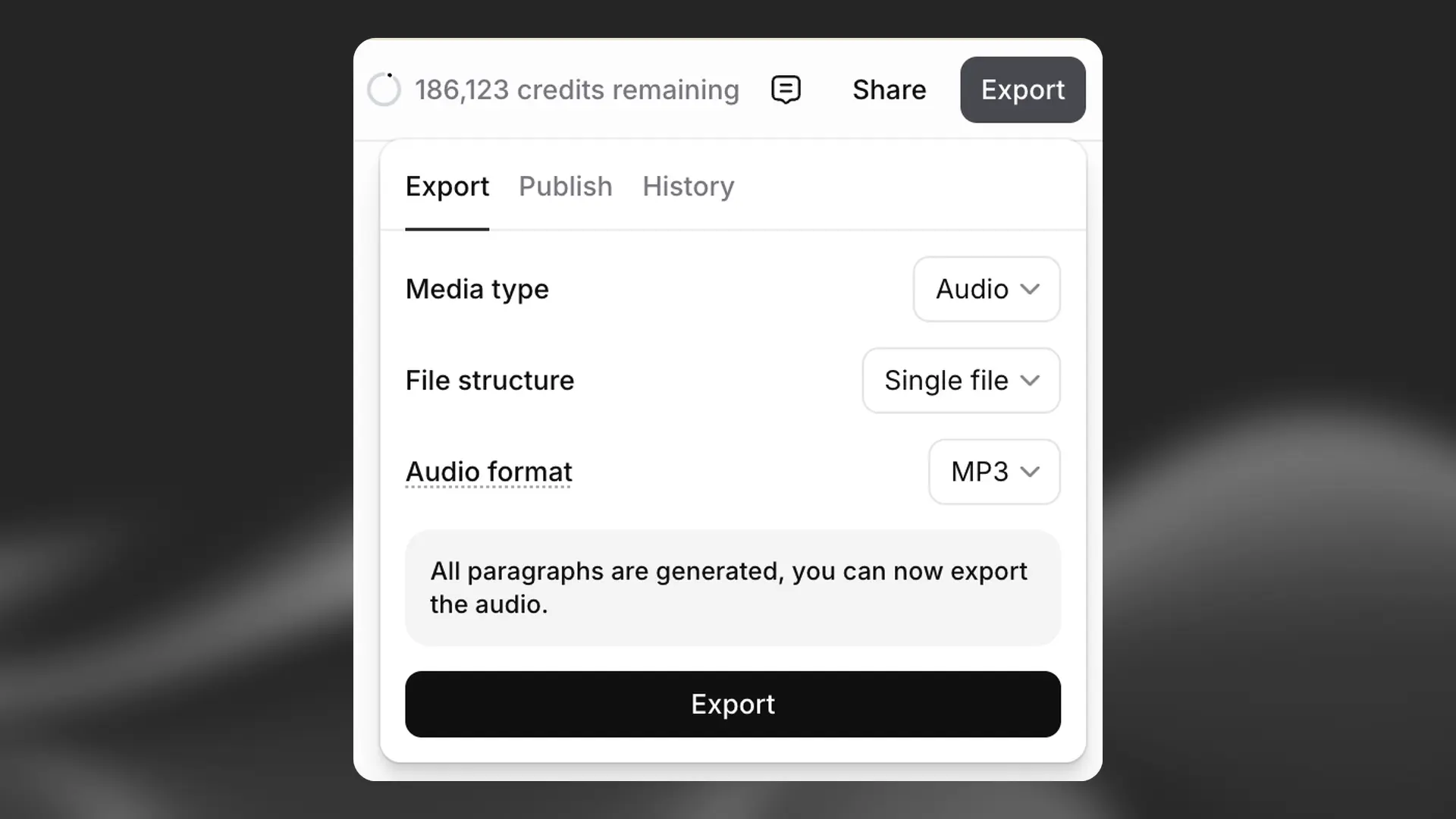
Export settings
Export settings
Within the Export tab under Project settings you can add additional metadata such as Title, Author, ISBN and a Description to your project. This information will automatically be added to the downloaded audio files. You can also access previous versions of your project, and enable volume normalization. These settings apply to audio exports; video appearance is controlled by your timeline and caption templates.
Exporting and Sharing
When you’re happy with your chapter or project, use the Export button to generate a downloadable version. If you’ve already generated audio for every paragraph in either your chapter or project, you won’t be charged any additional credits to export. If there are any paragraphs that do need converting as part of the export process, you will see a notification of how many credits it will cost to export.
Video exports on free and Starter plans include a watermark. To export videos without a watermark, you need a Creator plan or above.
Export options
Export options
If your project only has one chapter, you will just see the option to export as either MP3 or WAV (audio), or as video when a video track/captions are present.
If your project has multiple chapters, you will have the option to export each chapter individually, or export the full project. If you’re exporting the full project, you can either export as a single file, or as a ZIP file containing individual files for each chapter. You can also choose whether to download as MP3 or WAV for audio‑only exports.
For video exports, enable captions and add a video track (or shareable TTS video) before exporting. Video is rendered with your selected caption template.
Quality setting
Quality setting
The quality of the export depends on your subscription plan. For newly created projects, the quality will be:
- Free, Starter and Creator: 128 kbps MP3, or WAV converted from 128 kbps source.
- Pro, Scale, Business and Enterprise plans: 16-bit, 44.1 kHz WAV, or 192 kbps MP3 (Ultra Lossless).
If you have an older project, you may have set the quality setting when you created the project, and this can’t be changed. You can check the quality setting for your project in the Export menu by hovering over Format
Downloading
Downloading
Once your export is ready, it will be automatically downloaded. For shareable TTS videos, you can also copy a link for quick sharing.
You can access and download all previous exports, of both chapters and projects, by clicking the Project options button and selecting Exports.
Sharing
Sharing
From the editor, create a read‑only link so others can play your timeline and review your mix without downloading files. You can revoke access at any time. Commenting is available at launch, including anonymous comments.

Commenting
Commenting
Invite collaborators or your audience to leave feedback directly on the timeline. Comments are timestamped to the playhead so feedback appears exactly where it’s relevant. Commenters don’t need an ElevenLabs account and can leave a name or post anonymously. Discussions stay organized with threaded replies and optional mentions of collaborators.
To add a comment, open a shared project link (or the editor with sharing enabled), move the playhead to the right moment, and click Add comment. Type your message and post; use Reply to continue the thread. You’ll receive email notifications when there’s a new comment or reply in a thread you started or participated in.
When feedback is addressed, mark the thread as Resolved; it will collapse in the list and can be reopened later. Resolving a thread pauses further notifications until it is reopened.
FAQ
Free regenerations
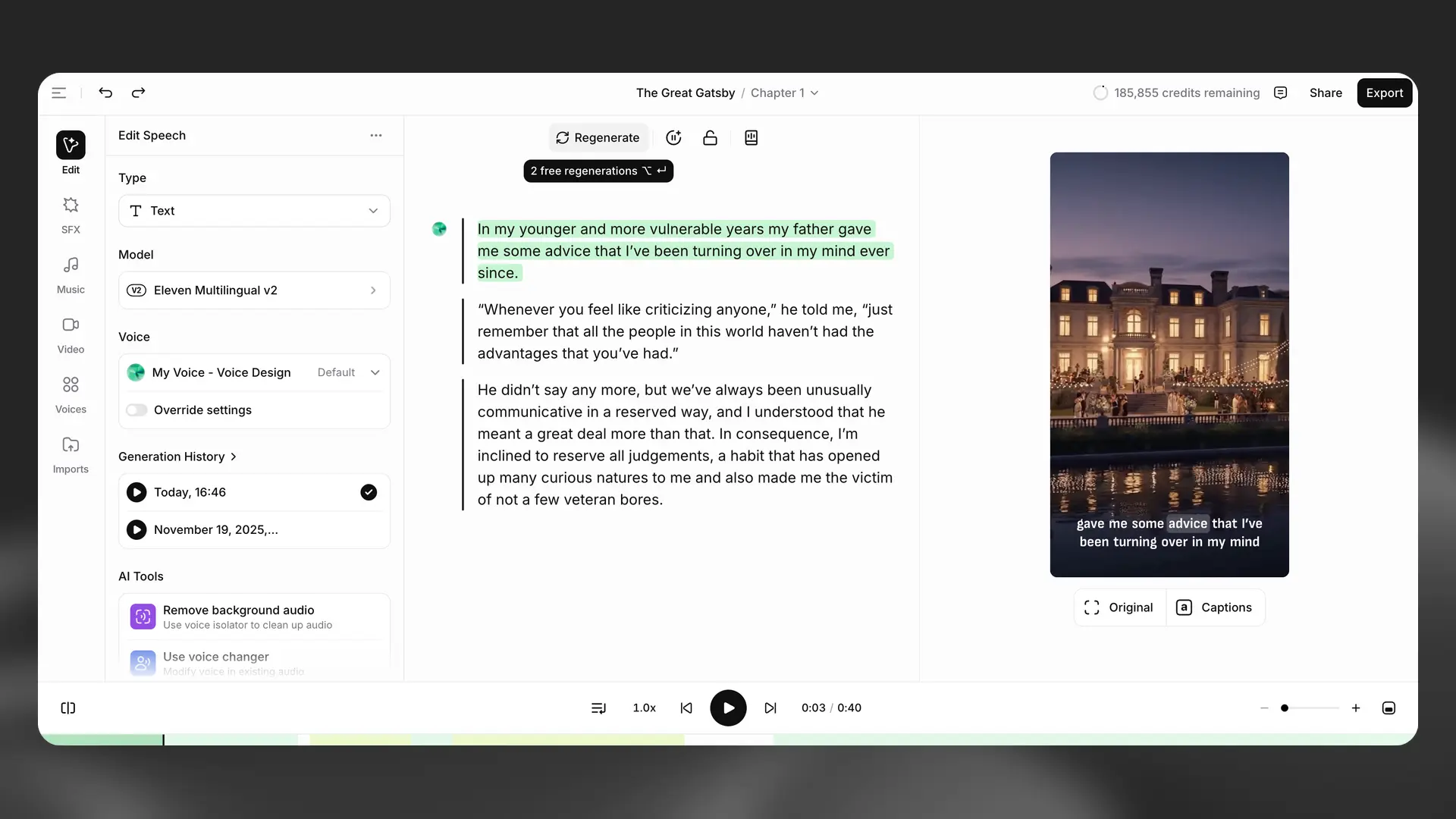
In Studio, provided you don’t change the text or voice, you can regenerate a selected paragraph or section of text twice for free.
If free regenerations are available for the selected paragraph or text, you will see Regenerate. If you hover over the Regenerate button, the number of free regenerations remaining will be displayed.
Once your free regenerations have been used, the button will display Generate, and you will be charged for subsequent generations.
Auto-regeneration for bulk conversions
When using Export to generate audio for a full chapter or project, auto-regeneration automatically checks the output for a range of issues including:
- volume distortions
- voice similarity
- mispronunciations
- missing or additional words
If any issues are detected, the tool will automatically regenerate the audio up to twice, at no extra cost.
This feature may increase the processing time but helps ensure higher quality output for your bulk conversions.